Handwritten Form Recognition Using Artificial Neural Network
Form Recognizer aims to build a deep learning model to extract handwritten text from a scanned Permanent Account Number (PAN) application form and convert them into digital format or editable text and store it in an excel file for further processing like statistical analysis or machine learning. The Learning model is based on the Convolution Neural Network (CNN) for the feature extraction and higher end classification. To accomplish this task, the handwritten forms are scanned, preprocessed to remove noise and handwritten fields are extracted. OpenCV is used to get the contours of the characters in the extracted images. This approach gives better accuracy than using plain CNN without out contours. The CNN model gives an accuracy of 91% on merger of numbers, uppercase and lower-case alphabets of EMINST dataset. Further, handwritten form recognizer system is built by incorporating this learning model, which is in turn integrated with preprocessing and segmentation methods. Finally, the output of the system is stored in a CSV file.
Usually, handwritten Text recognition (HTR) works in the offline mode and it recognizes the handwritten text in the scanned image and converts them into digital text. This saves time as well as reduces the error rates which are a concern in the case of manual data entry process. Though there was numerous works done on the Handwritten text recognition, it still remains as a challenge. It is even more challenging when it comes to text recognition on forms. Common challenges faced during the handwritten text recognition on the forms are due to the text surrounding boxes.
Also, handwritten characters recognition becomes highly uncertain as the handwriting varies from one person to another, some characters are written in the same shape, disconnected structure, varying thickness and quality of scanners used.
PAN which stands for Permanent Account Number is a unique identifier of every resident of India. Any person can apply and get the PAN number by filling and submitting the PAN application form to the Income Tax department of India. This project considers the PAN application form filled in Capital letters and extracts the values against each field such as First name, Last name, Father's name, Mother's name, Address, phone number, date of birth, applicant's photo and signature and saves to an excel sheet.
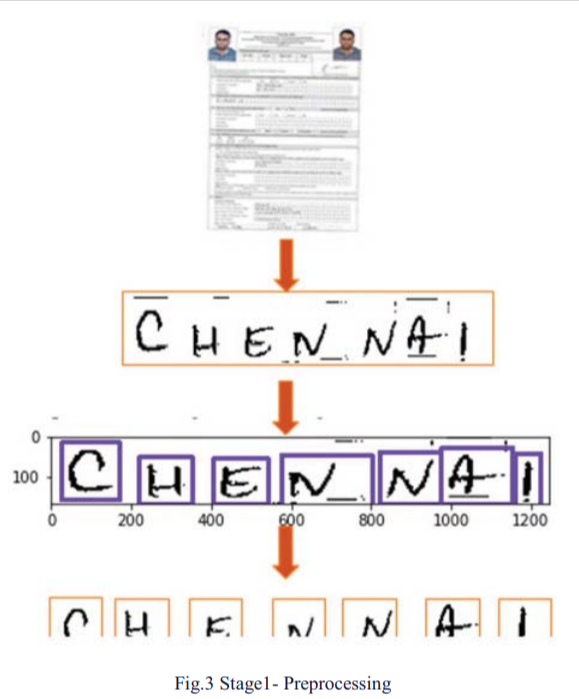
The model pipeline includes the stages image preprocessing, feature extraction and classification to convert the features to the text. In the image preprocessing stage, image (filled PAN application) is binarized, scaled, contrast is improved, and the surrounding lines are removed. The handwritten fields are extracted from the preprocessed form images. Below is the example of such extracted images for CITY field.

These extracted images are saved in a new folder and renamed using a predefined file naming convention. Example: This image is saved as
Character Extraction for Prediction: The images (handwritten fields), extracted from the form, still cannot be fed to the CNN model as the CNN classifiers need images of each character. So, using OpenCV's contours technique, individual characters are identified. Below is a sample image with contouring:

Stage 1: Preprocessing
Once the contouring is done, the coordinates for each contour are retrieved and characters are extracted based on the coordinates and fed to the CNN model. CNN model predicts the text based on the character image fed by extracting the features information of the image.
Stage 1: Preprocessing
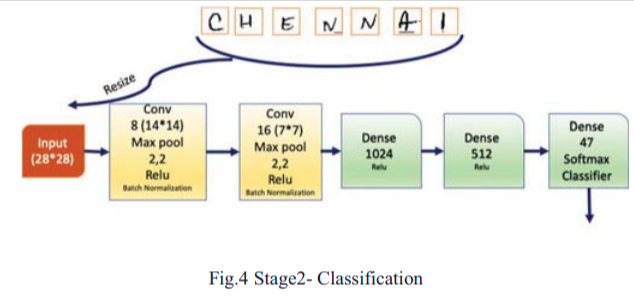
Stage2: Convolutional Neural Network - Classification
There has been a lot of research done in the past which has led to excellent results in handwriting recognition. In August 2013, a paper by Thomas M Breuel et al. [1], applied bidirectional LSTM networks to the problem of printed Latin and Fraktur characters recognition.
The results presented in this paper shows that LSTM yields excellent OCR results for both Latin/Antigua and Fraktur characters. But a common and valid concern with OCR systems based on machine learning or neural network techniques is whether they will generalize successfully to new data or to different languages. Also, an unsatisfactory aspect of LSTM-based models is that they are "black box" models.
In May 2017, Darmatasia and Mohamad Ivan Fanany proposed a machine learning model for recognizing handwritten characters on printed form documents [2]. The model used Convolutional Neural Network (CNN) for feature extraction and Support Vector Machines (SVM) as a high-end classifier. SVM, when used with LI loss function and L2 regularization, is able to give a recognition rate that is better than only using CNN. Using CNN-SVN model, achieved an accuracy of 98.85% on numeral characters, 93.05% on uppercase characters, 86.21% on lowercase characters and 91.37 on the merger of numeral and uppercase characters.
In another paper by JEM Adriano et al[4] in 2019, OCR process followed a workflow which includes 4 major phases. Image pre-processing is done using Sauvola binarization. Followed by character segmentation using blob analysis. Then, pre-trained Convolutional Neural Networks: GoogLeNet, AlexNet, and VGG16 used for feature extraction and character classification is done using Support Vector Machines (SVM), K-Nearest Neighbor (KNN), and Naïve Bayes classifiers. These combinations of Convolutional Neural Networks for feature extraction and SVM for character classification improved the results with accuracy going up to 98.62%.
Data Collection For the purpose of training and testing the model, team downloaded empty PAN application form from the below url
https://www.pan.utiitsl.com/PAN/forms/49A.
Then the PAN applications were distributed to 100 different people for filling them in different handwritings. Team also ensured that the applications were filled up in UPPERCASE
Data Preparation:
A) The filled pan applications were scanned and stored as JPG image of good resolution (approx: $1500*2500$)
B) Also, since each application contains two pages, name convention was followed to map front and back pages to the same applicant. Ex of the images files: image1-01.jpg (for first page), image1-02.jpg (for second page).
C) Along with filled PAN applications, CNN model was also trained with EMINST dataset.
D) Description of EMNIST Handwritten dataset The EMNIST dataset was downloaded from the url https://www.nist.gov/itl/products-and-services/emnist-dataset
EMNIST has got six different splits in the dataset, An information of the different dataset is provided below:
ByClass EMNIST: 814,255 characters, 62 unbalanced classes.
By Merge EMNIST: 814,255 characters. 47 unbalanced classes.
Balanced EMNIST: 131,600 characters. 47 balanced classes.
Letters EMNIST: 145,600 characters. 26 balanced classes.
Digits EMNIST: 280,000 characters. 10 balanced classes.
MNIST EMNIST: 70,000 characters. 10 balanced classes.
EMNIST By Merge was used in the CNN learning model
Methods: Deep learning methods that the team tried out for achieving the aim are: [1] Sequence to Sequence implementation using LSTM on IAM dataset [2] Simple CNN character classification using EMNIST dataset [3] CNN character classification with Contour detection using EMNIST dataset.
OCR model output mainly depended on the quality of the image. Hence the image preprocessing steps become inevitable before we feed the image to any deep learning model. OpenCV was used for image preprocessing. Along with normal preprocessing techniques like image scaling, Binarization, noise removal etc., surrounding box removal/masking was done to get rid of the surrounding boxes in the PAN application form and to get the written text much clearly.
Image Scaling: All the images were scaled to 300 DPI resolution which gave an image shape of $3500*2500$ (approx). Image Contrast: Image's contrast had been increased while scanning the images to minimize the time taken for preprocessing.
Binarize Image: This step was done to convert the input image in RGB scale to GRAYscale image. Removal of table structure: The surrounding boxes like table structure was a hindrance to our model, so these surrounding boxes were noise for the model.
Different surrounding boxes had different complexity. As shown in the below picture, Simple surrounding boxes were much easier than the Joined frame surrounding boxes, since there were fewer vertical lines in Simple surrounding boxes whereas in Joined frame surrounding boxes, there were so many vertical lines in between to be removed.

LableIMG is the annotating tool that is used to draw the bounding boxes for the handwritten fields of the PAN form. Once the bounding box is drawn, the coordinates for each bounding box is automatically identified by this tool. Also, for each bounding box drawn, it prompts to enter the label. Finally, once saved, this tool gives one xml file (with the same name of the image file) as output which contains the labels and the coordinates of the bounding boxes.
DNN Models Experimented: To achieve the objective of this project multiple deep learning models were experimented with
1. Sequence to Sequence implementation using LSTM on IAM dataset
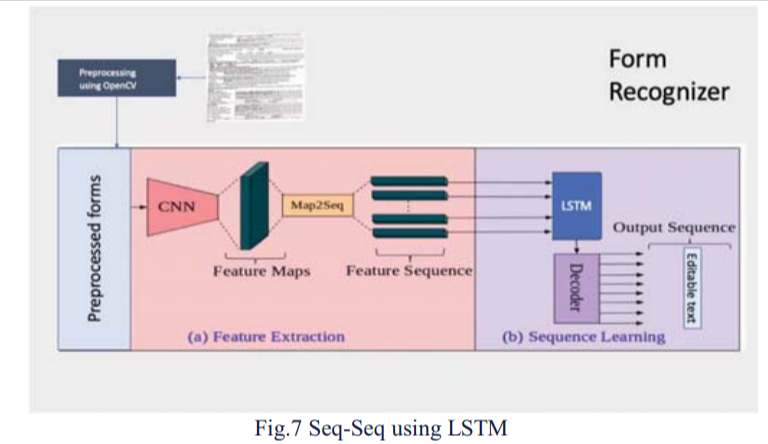
Model was not performing to expected level due to reasons:
-Space between the characters were more
-Required more resources and training on the more data with spaced characters

Simple CNN character classification using EMNIST dataset Since word level bounding boxes were only available, the team again went for the bounding boxes creation at the character level for the first page alone. Once the character level bounding boxes were created, the coordinates were used to extract the character of the field. Coordinates of the extracted character were sorted by x-min and character sequence was arrived, then character images were fed to CNN architecture and predicted the fields. The model accuracy was 90%. A sample output of this model was given below. This looked better when compared to Sequence to Sequence model.

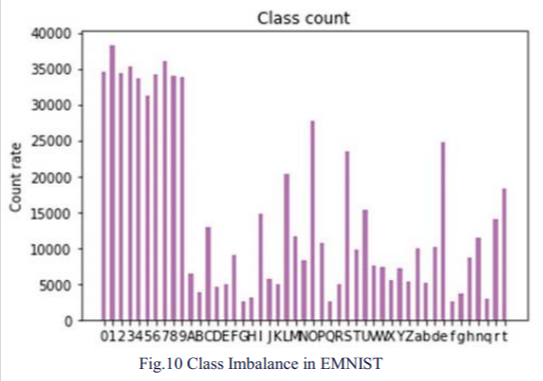
Class Imbalance problem: EMINST dataset which was used for model training also suffered from class imbalance problem. This also might count as the reason for lower prediction accuracy of the characters. The chart below showed the Dataset had more samples for numbers than the alphabets. Though this dataset is the combination of numbers and alphabets, due to the class imbalance, the model predicted good on numbers than in alphabets.
CNN Alphabet classification with contour detection The team thought that instead of creating bounding boxes for individual characters for all the Form images freshly, but to use word bounding boxes for CNN classification architecture. So, creating the contour for the characters in the word using OpenCV was arrived and used OpenCV to create the contour and the character images were extracted from the sorted contour coordinates and were fed to CNN classification model. Here again the accuracy of the model was 91%.

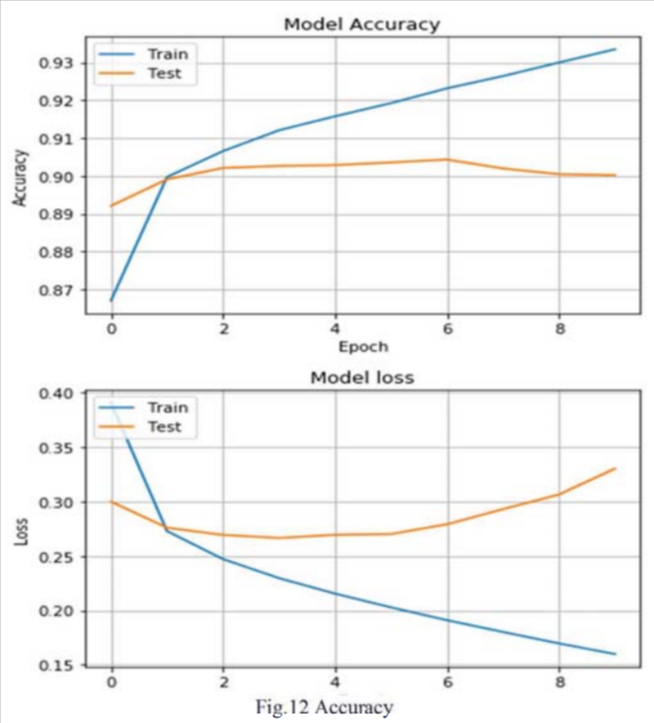
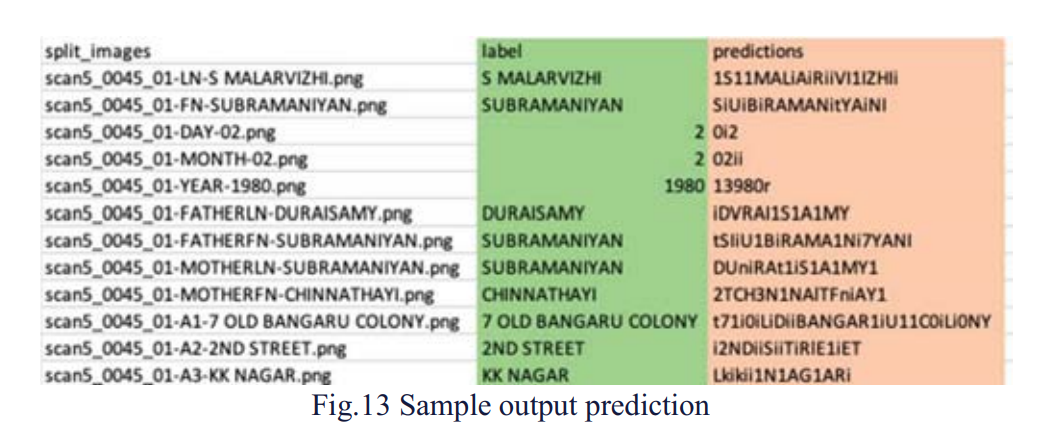
We were able to achieve the same accuracy as that of a similar work done on the forms by Darmatasia and Mohamad Ivan Fanany using CNN as feature extraction and SVM as high-end classifier with an accuracy of 91% on the merger of the numeral and the uppercase characters.
With Sequence to Sequence implementation using LSTM on IAM dataset, the model performance was not up to the expectation owing to the excess space between the characters. If we are able to train the model on more samples with space between the characters, the performance of the model can be improved.
With Simple CNN character classification using EMNIST dataset, the model accuracy was 90%, this was significantly better than the Sequence to Sequence implementation using LSTM on IAM dataset. However, this process involves creating a bounding box for each character. Based on the coordinates of each character, the character image was input to the model to generate the sequence of characters.
The model was trained using EMNIST dataset, it was observed that the model was able to predict the numbers better than the alphabets. If the model is trained with a balanced dataset, then we can improve the model accuracy.
With CNN Alphabet classification with contour detection, OpenCV was used to create contours and the character images were extracted from the sorted contour coordinates and were fed to CNN classification model. Model accuracy was 91%, but without the manual process of adding bounding boxes to characters.
REFERENCES
- T. M. Breuel, A. Ul-Hasan, M. A. Al-Azawi, and F. Shafait, "High-performance OCR for printed English and fraktur using LSTM networks," in 2013 12th International Conference on Document Analysis and Recognition, 2013, pp. 683–687.
- ResearchGate, "Publication resource," [Online]. Available: https://www.researchgate.net/publication/316350087. [Accessed: 09-Nov-2020].
- K. Dutta, P. Krishnan, M. Mathew, and C. V. Jawahar, "Improving CNN-RNN hybrid networks for handwriting recognition," in 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), 2018.
- J. E. M. Adriano et al., "Digital conversion model for hand-filled forms using optical character recognition (OCR)," IOP Conf. Ser. Mater. Sci. Eng., vol. 482, p. 012049, 2019.
- TU Wien Repository, "Handwritten text recognition in historical documents," [Online]. Available: https://repositum.tuwien.at/bitstream/20.500.12708/5409/2/Handwritten%20text%20recognition%20in%20historical%20documents.pdf. [Accessed: 09-Nov-2020].
- H. Scheidl, "An Intuitive Explanation of Connectionist Temporal Classification," Towards Data Science, 10-Jun-2018. [Online]. Available: https://towardsdatascience.com/intuitively-understanding-connectionist-temporal-classification-3797e43a86c. [Accessed: 09-Nov-2020].
- B. Shi, X. Bai, and C. Yao, "An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition," arXiv [cs.CV], 2015.
- H. Scheidl, S. Fiel, and R. Sablatnig, "Word beam search: A connectionist temporal classification decoding algorithm," in 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), 2018.


