Research: Activity & Emotion Detection of Recognized kidsin CCTV Video for Day Care Using SlowFast & CNN
For working parents a real-life challenge faced is to keep track of their child activities in playschool and creche. Despite having CCTV surveillance available to parents, monitoring 8-10 hours videos on a day-to-day basis is not possible, hence CCTV videos, which carry millions of information, get unnoticed by parents and day-cares. The aim of project was to process CCTV videos to identify the child, detect their respective expressions as well as planned/unplanned activities throughout the day. We have considered angry, disgust, scared, happy, sad, surprised, neutral expressions of kids to be monitored on daily basis. The various activities performed at daycare like playing, drawing, rhyming, dancing along with not so usual activities like slapping, falling, pushing would also be monitored on kids. It can be further extended to create a 8-10 minutes glimpse/summary in form of video/timeline of children’s entire day activities and inform their respective parents. This can improvise the overall experience of the daycare for parents.
For working parents a real-life challenge faced is to keep track of their child activities in playschool and creche. Despite having CCTV surveillance available to parents, monitoring 8-10 hours videos on a day-to-day basis is not possible, hence CCTV videos, which carry millions of information, get unnoticed by parents and day-cares. The proposed solution gives a summary about the kid's activities at a day care. It will not only impact the overall engagement of Parents, Kids and Day-cares/Schools but also will improve the quality and trust among them along with saving time. Knowing that a kid is active/happy/sad would also help daycares in taking care of them in a personalized way.

Our use-case consists of 3 different problems Recognition of the kids, Expression of kids and Activity of kids, so we could define a kid's profile for each day in day care. For recognition we experimented over several models available like Siamese [8], Yolo [11] and found them working for single person recognition in a frame but not with group.
Next, we tried Haar cascade-based models and found this works well with frontal images and did not give promising accuracy with our experimental frames. We ended up with a network architecture which is based on ResNet-34 from the Deep Residual Learning for Image Recognition [27].
For expression detection, we considered FER-2013 dataset and models with Xception CNN & Haar feature-based cascade classifiers. For activity detection [9], we considered a few known action datasets like UCF101, Kinetics 600[24] and AVA [2] and discovered their pros and cons. UCF101 do not contain kid's images and the action categories did not match to common activities in a day care. Kinetics 600[25] dataset had a great match with our use case, but the dataset had a single caption per frame[19].
We, however, needed to caption each kid's activity. AVA fulfils this constraint for us. The AVA dataset densely annotates 80 atomic visual actions in 430 15-minute movie clips, where actions are localized [2] in space and time, resulting in multiple action labels per human. For activity captioning, we used SlowFast [5] model trained over AVA dataset. However, there is no single model or architecture as of today which could give the desired solution.
We explored various models that were among the best in industry to perform facial recognition along with expressions. We also looked for any existing model which could track individuals' activities from CCTV videos. We collected several daycare CCTV videos from source and after thoroughly analyzing them, we identified activities which were of concern at daycare. We asked for daily schedule of activities and started looking for any existing dataset that contains most of them. Kinetic and AVA datasets had most of the activities of our concern.
A. Training Data
We prepared our dataset by taking videos of the most common scenarios at daycare. We wrote a code to randomly select a few frames and considered them as input to all the models. A collection of 3 sample videos (30 seconds each) was taken into account, out of which total 20 random frames were selected at a gap of 2-3 seconds (with the help of random frame selector code) for our experiment. The 3 algorithms associated with face, expression and activity detection were made to run on below set of 20 input frames.

B. Ground Truth Labelling
To measure the result, we had created ground truths for recognition, expression and activity as shown in Table I. There were 9 activities prominently visible in our daycare sample, out of 80 that are available in AVA dataset. For expressions, we have considered 7 expressions.

C. Predictions
We divided our problem into 3 sub problems viz. facial recognition, expression detection and activity detection.
1. Face Recognition: For Facial recognition, we created 128-d embeddings of each face from the training dataset and compared it with the facial embeddings in the testing image.
We then calculated the Euclidean distance between the known embeddings and the calculated embeddings and used a simple k-NN model along with votes to make final face classification.

The face recognition network architecture is based on ResNet-34 with fewer layers and the number of filters reduced by half from the Deep Residual Learning for Image Recognition paper by He et al. The face recognition module uses dlib and imutils library. We matched each face in the input image (encoding) to our known encoding's dataset (stored in the pickle file). If Euclidean distance is below some tolerance (the smaller the tolerance, the stricter our facial recognition system will be) then we return True, indicating the faces match. Otherwise, if the distance is above the tolerance threshold, we return False as the faces do not match.
2. Expression Recognition: Our final expression detection algorithm is a two-step process. In the first step, front faces are extracted from group photos using HAAR cascade classifier and in the second step we are using an Xception CNN model to detect one of the 7 natural expressions of the subject (angry, disgust, scared, happy, sad, surprised, neutral).

The Model was trained with FER 2013 data set. Average accuracy achieved was 73.44%. Images are categorized based on the emotion shown in the facial expressions (angry, disgust, scared, happy, sad, surprised, neutral).


3. Activity Recognition: We found AVA dataset most suitable for our use-case because of the following reasons: Annotations were already provided for each individual per video clip. The AVA dataset densely annotates 80 atomic visual actions in 430 movie clips (15-minute each), where actions are localized in space and time, resulting in 1.62M action labels with multiple labels per human occurring frequently, which in our use-case was needed. AVA provides audiovisual annotations of video with improved understanding of human activity. Each of the video clips has been exhaustively annotated and together they represent a rich variety of scenes, recording conditions, and expressions of human activity. The AVA dataset is focused on spatiotemporal localization of human actions. The data is taken from 437 movies. Spatiotemporal labels are provided for one frame per second, with every person annotated with a bounding box and (possibly multiple) actions.

We explored the state-of-the-art action recognition algorithm SlowFast Networks. It uses ResNet-50 as the backbone of the network. We used the SlowFast pretrained model with 32 frames which are processed at sampling rate of 2 fps and 101 deep layered ResNet model. SlowFast networks for video recognition involves a Slow pathway, operating at low frame rate, to capture spatial semantics and a Fast pathway, operating at high frame rate, to capture motion at fine temporal resolution. The Fast pathway can be made very lightweight by reducing its channel capacity, yet can learn useful temporal information for video recognition.

The result table below in Table II is the output for the ensemble model wherein predictions for each of the 3 categories are documented of each frame. Each row in the below table represents the number of children detected, ground truth as well as prediction on a frame for face recognition, expression detection and activity recognition. For e.g., if we take V1_Frame350 from the result table in Table II, then following are the metrics using Table I ground truth references:
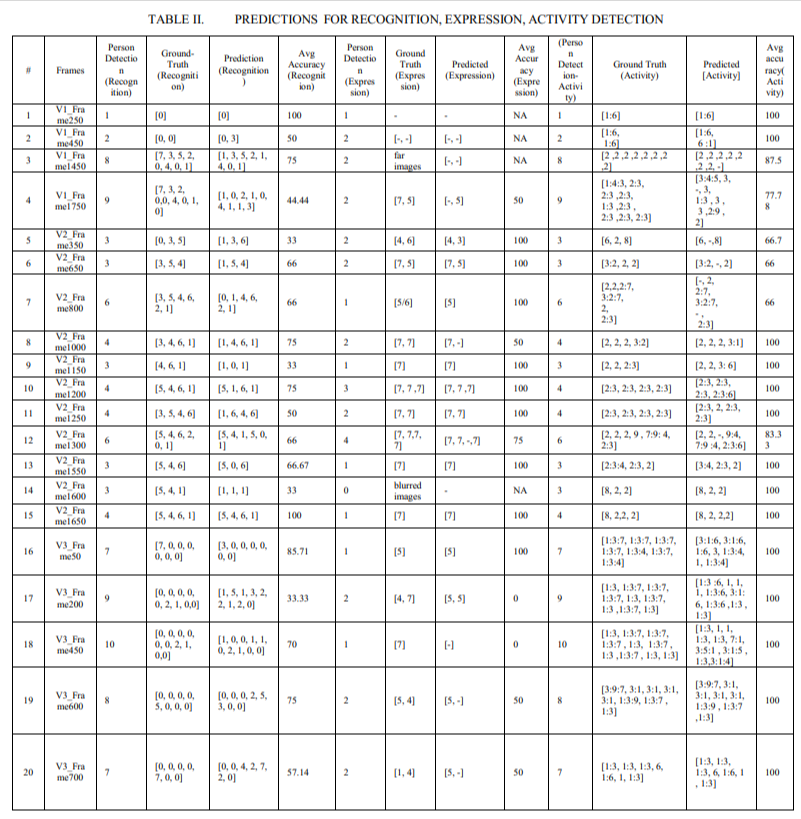
A. Face Recognition: Person Detected: 3, Ground Truth: [0,3,5], Prediction: [1,3,6], Accuracy: 33% (as out of 3 children only one child was recognized correctly).
B. Expression Detection: Person Detected: 2, Ground Truth: [4,6], Prediction: [4,3], Accuracy: 50% (as out of 2 children only one child's expression was recognized correctly).
C. Activity Recognition: Person Detected: 3, Ground Truth: [6,2,8], Prediction: [6,-,8], Accuracy: 66.7% (as out of 3 children, 2 child's activity was recognized correctly).
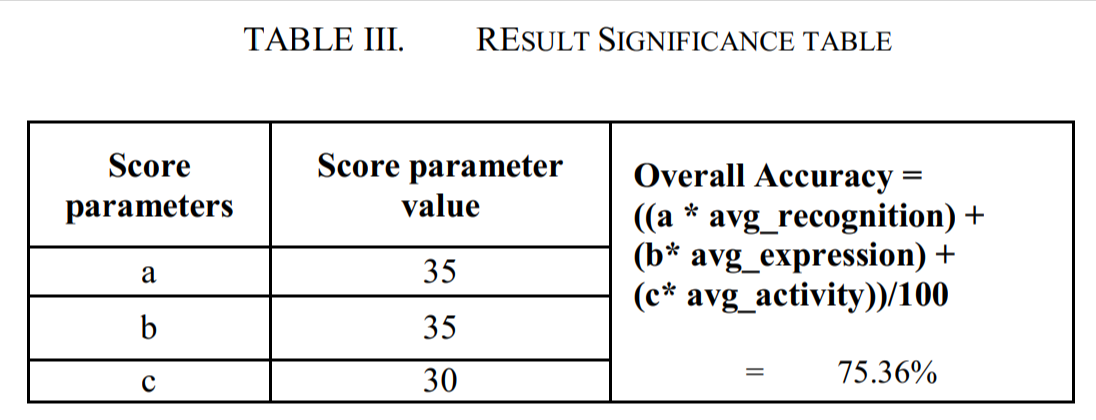
Based upon our use-case, different weightages have been assigned with each task as per their importance. In TABLE III, [a, b, c] signifies the importance of facial recognition, expression detection and activity detection of kids respectively. The below table documents the weights for each task and based upon that calculates the overall mean accuracy for the ensemble model which comes out to be 75.36%.
The further plan is to synchronize these models in a way that a single run gives one output having all 3 detections in one frame. We want to move this existing model running in batch to real time. We could use the output of this model as an input to a sequence-based NLP model and generate relevant summarization text for each kid by combining the results of recognition, expression and activity. For e.g. [Madhav, Happy, Sit] the output could be Madhav is happily sitting in class.
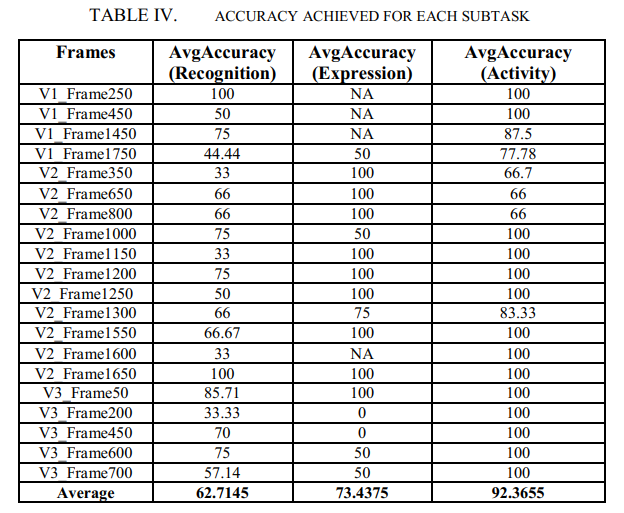
We achieved an average accuracy of 92.36% as shown in Table IV. In our proposed approach, using existing models we got 76.5% accuracy which can be further improved to approx 90% with good quality frontal images data.
The further plan is to synchronize these models in a way that a single run gives one output having all 3 detections in one frame.
1. We could plan to move this existing model running in batch to real time.
2. We could use the output of this model as an input to a sequence-based NLP model and generate relevant summarization text for each kid by combining the results of recognition, expression and activity. For e.g. [Madhav, Happy, Sit] the output could be Madhav is happily sitting in class.
3. Solution can send real-time alerts to Day-care management & Parents in case of any inappropriate things are taking place or any kid is absent, or teachers are engaged with phones, or they are not attentive at any time etc.
As per our research there is no existing model which targets all 3 tasks together i.e. face recognition, expression and activity detection for kids in day-care. Hence this can be considered as the benchmark accuracy for such an ensemble model which caters this unique use-case
REFERENCES
- Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik and Kaiming He, "SlowFast Networks for Video Recognition," Facebook AI Research (FAIR), arXiv:1812.03982v3 [cs.CV], 29 Oct 2019.
- C. Gu et al., "AVA: A video dataset of spatiotemporally localized atomic visual actions," Proc. CVPR, 2018.
- Navneet Dalal and Bill Triggs, "Histograms of Oriented Gradients for Human Detection," INRIA Rhone-Alpes, France.
- Vahid Kazemi and Josephine Sullivan, "One Millisecond Face Alignment with an Ensemble of Regression Trees," KTH Royal Institute of Technology, Sweden.
- C. Feichtenhofer et al., "SlowFast networks for video recognition in ActivityNet challenge 2019."
- Ashwin Geet D'Sa and Dr. B.G. Prasad, "An IoT Based Framework For Activity Recognition Using Deep Learning Technique," Jun. 2019.
- Octavio Arriaga et al., "Real-time Convolutional Neural Networks for Emotion and Gender Classification," Oct. 2017.
- Yujia Zhang et al., "Motion-patch-based Siamese CNNs for human activity recognition in videos," Jan. 2020.
- Guilhem Cheron, Ivan Laptev, Cordelia Schmid, "P-CNN: Pose-based CNN Features for Action Recognition," 2015.
- P. Khorrami et al., "How deep neural networks can improve emotion recognition on video data," IEEE ICIP, 2016.
- W. Yang and Z. Jiachun, "Real-time face detection based on YOLO," 2018.
- M. S. Howlader et al., "Detection of Human Actions in Library Using YOLO V3," Dec. 2018.
- Srinath Shiv Kumar et al., "Deep Learning-Based Automated Detection of Sewer Defects in CCTV Videos."
- J. Redmon and A. Farhadi, "YOLO9000: Better, Faster, Stronger," IEEE CVPR, 2017.
- D. K. Appana et al., "Video-based smoke detection using spatial-temporal analyses," Information Sciences, 2017.
- M. Hendri, "Design of smoke and fire detection system using image processing," Thesis, 2018.
- R. Girshick et al., "Rich feature hierarchies for accurate object detection," CVPR, 2014.
- R. Huang et al., "YOLO-LITE: A real-time object detection algorithm optimized for non-GPU computers," IEEE Big Data, 2018.
- S. Shinde et al., "YOLO based human action recognition and localization," Procedia Computer Science, 2018.
- G. Li et al., "A new method of image detection for small datasets under YOLO framework."
- Paul Ekman et al., "Universals and cultural differences in judgments of facial expressions," Journal of Personality and Social Psychology, 1987.
- Paul Ekman, "Strong evidence for universals in facial expressions," 1994.
- ActivityNet-Challenge, 2019 evaluation documentation.
- J. Carreira et al., "A short note about Kinetics-600," arXiv:1808.01340, 2018.
- J. Carreira et al., "A short note on the Kinetics-700 human action dataset," arXiv:1907.06987, 2019.
- C. Gu et al., "AVA dataset of atomic visual actions," CVPR, 2018.
- K. He et al., "Deep residual learning for image recognition," CVPR, 2016.
- A. Diba et al., "Spatio-temporal channel correlation networks for action classification," ECCV, 2018.
- Yuxin Wu et al., "Detectron2," 2019.
- Kensho Hara et al., "Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs," 2017.
- Kaiming He et al., "Deep Residual Learning for Image Recognition," 2015.


