
In Data Engineering interviews, you aren't just tested on coding. You are tested on system design, database theory, and distributed computing concepts.
Most candidates fail because they memorize tool names (like "Spark" or "Kafka") without understanding the underlying architecture.
To solve this, we reached out to a Senior Data Engineer to get the exact questions used to screen candidates.
We have categorized these into three distinct buckets:
- The Foundation (SQL & Modeling)
- The Mechanics (Big Data Frameworks)
- The Thinking (Architecture & Scenarios)
But first, let’s look at the strategy to ace the interview based on your experience level.
How to Approach the Interview
Before we dive into the questions, you need to understand how to answer them. The strategy changes depending on your seniority.
For Students & Junior Engineers
The Trap: Trying to learn every tool in the ecosystem. If you list Hadoop, Spark, Flink, Kafka, AWS, and Azure on your resume but can’t explain how they work under the hood, you will fail.
The Win: Deep mastery of SQL and Python. You must understand Data Modeling (Star vs. Snowflake schemas) perfectly. If you hesitate when asked to join two tables, the interview is effectively over.
Tip: Admit what you don’t know. If asked about a tool you haven't used, say: "I haven't used Kafka in production, but I understand it’s a distributed event store used for decoupling systems." This demonstrates architectural maturity.
For Experienced Professionals
The Trap: Being a "Tool Jockey." If an interviewer asks, "How do you handle large datasets?" and you answer, "I use Spark," you have failed. Spark is a tool, not a solution.
The Win: Focus on Trade-offs. Discuss why you chose a specific technology. Discuss Consistency vs. Availability (CAP Theorem). Discuss Cost Optimization vs. Latency.
Tip: Stop quoting syntax. Start talking about Business Value, Data Governance, and Scalability.
Post Graduate Program in Data Science
Master data science skills with a focus on in-demand Gen AI through real-world projects and expert-led learning.
Part 1: SQL & Data Modeling (The Foundation)
These questions are non-negotiable. Whether you are a junior or a lead, you must know these concepts.
1. What is the difference between OLTP and OLAP?
This is the fundamental distinction in database architecture.
- OLTP (Online Transaction Processing): These systems are designed for transactional speed and data integrity. They handle a high volume of small, fast transactions (inserts, updates, deletes).
- Example: A bank ATM system or an e-commerce checkout.
- Structure: Highly normalized (3NF) to avoid redundancy.
- OLAP (Online Analytical Processing): These systems are designed for complex queries and data analysis. They read historical data to find trends.
- Example: A business intelligence dashboard or a Data Warehouse.
- Structure: Denormalized (Star or Snowflake Schema) to optimize read speeds.
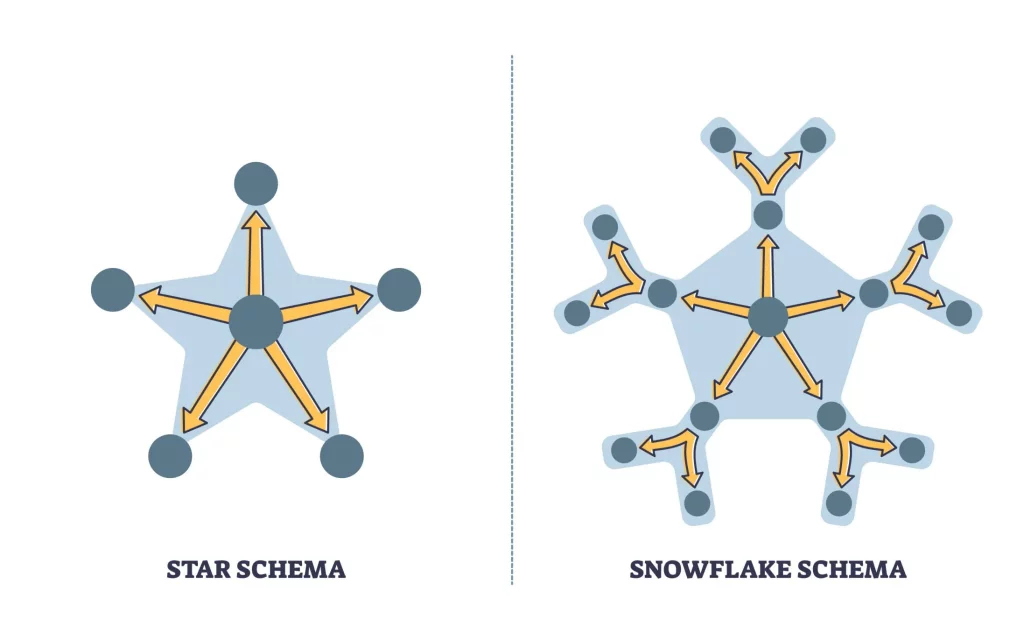
2. Explain Star Schema vs. Snowflake Schema.
Both are dimensional modeling techniques used in data warehousing.
- Star Schema: This consists of a central "Fact Table" (containing metrics) connected directly to "Dimension Tables" (containing attributes). It is simpler and faster for queries because it requires fewer joins.
- Snowflake Schema: This is an extension of the Star Schema where the dimension tables are normalized (broken down into sub-dimensions). It saves storage space but complicates queries due to the increased number of joins.
Modern cloud warehouses (like Snowflake or BigQuery) often prefer Star Schema because storage is cheap, but compute (joins) is expensive.
3. What is the difference between TRUNCATE, DELETE, and DROP?
- DELETE: A DML (Data Manipulation Language) command. It removes rows one by one and logs each deletion. It is slower but can always be rolled back.
- TRUNCATE: A DDL (Data Definition Language) command. It removes all rows by deallocating the data pages. It is extremely fast.
- Note: In some databases (like SQL Server or Postgres), TRUNCATE can be rolled back if inside a transaction, but in others (like Oracle), it cannot. It typically resets identity counters.
- DROP: Removes the entire table structure and data from the database.
Read More about SQL Commands.
4. What are Window Functions?
Window functions perform calculations across a set of table rows that are related to the current row. Unlike GROUP BY functions, window functions do not collapse rows into a single output; they retain the row identity.
Common Use Case: Calculating a running total, a moving average, or ranking items within a category (e.g., RANK() OVER (PARTITION BY department ORDER BY salary DESC)).
5. How do you handle duplicate data in SQL?
There are two main approaches:
- Distinct Selection: Use the DISTINCT keyword if you only need to view unique records.
- Row Number Filtering: For physical removal or complex logic, use ROW_NUMBER() (Syntax varies by database, but the logic follows):
WITH duplicates_cte AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY id ORDER BY updated_at DESC) as rn
FROM customer_logs
)
DELETE FROM duplicates_cte WHERE rn > 1;
-- Note: In MySQL, you would use a DELETE JOIN instead of deleting from the CTE.
6. Explain ACID properties.
ACID ensures database transactions are processed reliably.
- Atomicity: All parts of a transaction succeed, or the entire transaction fails. (All or nothing).
- Consistency: The database moves from one valid state to another valid state. Constraints are enforced.
- Isolation: Concurrent transactions do not interfere with each other.
- Durability: Once a transaction is committed, it remains committed even in the event of a power loss.
7. What is Normalization vs. Denormalization?
- Normalization: The process of organizing data to reduce redundancy and improve integrity (OLTP).
- Denormalization: The process of adding redundant data to speed up complex reads (OLAP).
Rule of Thumb: Use Normalization for write-heavy operational systems. Use Denormalization for read-heavy analytical systems.
8. What is a Surrogate Key vs. a Natural Key?
- Natural Key: A key derived from the data itself that has real-world business meaning (e.g., Email Address, Social Security Number).
- Surrogate Key: A synthetic key generated by the system (e.g., an Auto-incrementing Integer or UUID).
Surrogate keys are generally preferred in Data Warehousing because they insulate the system from changes in business rules (e.g., a user changing their email address).
Part 2: Big Data & Frameworks (The Mechanics)
This section tests your ability to handle data that doesn't fit on a single machine.
9. What is the difference between ETL and ELT?
- ETL (Extract, Transform, Load): Data is transformed before it is loaded into the destination. Used when storage is expensive or the destination cannot handle complex processing.
- ELT (Extract, Load, Transform): Data is loaded into the destination in its raw form and transformed inside the data warehouse.
The Trend: ELT is the modern standard used with cloud warehouses (Redshift, BigQuery, Snowflake) because these tools have massive separation of compute and storage.
10. Explain the 3 Vs of Big Data (and the 4th important one).
- Volume: The size of the data.
- Velocity: The speed at which data is generated and processed.
- Variety: The different types of data (structured, semi-structured, unstructured).
- Veracity: The quality and trustworthiness of the data. Without Veracity, the other three are useless.
11. How does Apache Spark differ from MapReduce?
MapReduce writes intermediate results to the disk, which creates I/O overhead. Apache Spark optimizes for keeping intermediate results in memory (RAM).
While Spark will spill to disk if memory is full, its in-memory architecture makes it up to 100x faster for iterative algorithms (like Machine Learning) where data needs to be processed multiple times.
12. What is an RDD, DataFrame, and Dataset in Spark?
- RDD (Resilient Distributed Dataset): The low-level building block of Spark. It offers control but lacks optimization.
- DataFrame: A distributed collection of data organized into named columns. It uses the Catalyst Optimizer to speed up queries.
- Dataset: Provides the type safety of RDDs with the performance optimizations of DataFrames.
- Note: In PySpark (Python), the Dataset API is not strictly available; you primarily work with DataFrames.
13. How do you handle "Data Skew"?
Data skew happens when one partition has significantly more data than others, causing the entire job to wait for that one "straggler" task to finish.
The Fix:
- Salting: Add a random number (salt) to the skew key to distribute the data more evenly across partitions.
- Broadcast Join: If joining a large skewed table with a small table, broadcast the small table.
14. What is a Broadcast Join?
In a distributed join (Shuffle), data is moved across the network to align keys. This is expensive.
In a Broadcast Join, the smaller table is copied (broadcasted) to every worker node. The large table does not move. This eliminates the network shuffle and drastically improves performance for Large-to-Small table joins.
15. What file format do you prefer and why (Parquet vs. CSV)?
For Big Data, Parquet is superior.
- Columnar Storage: Parquet stores data by column, not row. If you only select 3 columns out of 100, it only reads those 3.
- Compression: Columnar data compresses much better than row-based CSV data.
- Schema: Parquet embeds the schema (types) into the file; CSV does not.
16. What is "Backfilling"?
Backfilling is the process of reprocessing or filling in historical data. This usually happens when you create a new metric and want to calculate it for the past year, or when a bug is fixed and past data needs to be corrected.
17. How do you ensure your pipelines are Idempotent?
Idempotency means that if you run the same pipeline multiple times with the same input, the result remains the same. It prevents duplicate data.
How to achieve it:
- Use INSERT OVERWRITE (if supported) or MERGE statements.
- Use "Upsert" logic (Update if exists, Insert if new) based on a primary key.
- Explicitly delete data for the specific time window before writing new data.
18. Batch vs. Streaming: When to use which?
- Batch Processing: Processing data in chunks at set intervals (e.g., daily). Use this for complex reporting where data freshness (latency) is not critical, but accuracy and completeness are.
- Streaming Processing: Processing data item-by-item as it arrives. Use this for fraud detection or real-time monitoring where low latency is critical.
PGP in Data Science (with Specialization in Gen AI)
Get industry-ready with in-demand skills like Python, SQL, ML, Tableau, and Gen AI to excel in today’s data-driven world.
Part 3: Architecture & System Design (The Thinking)
This is the most critical part of the interview.
Anyone can learn SQL syntax. But only a Senior Engineer understands how to design systems that don't crash at scale.
Here is how to answer the toughest architectural questions.
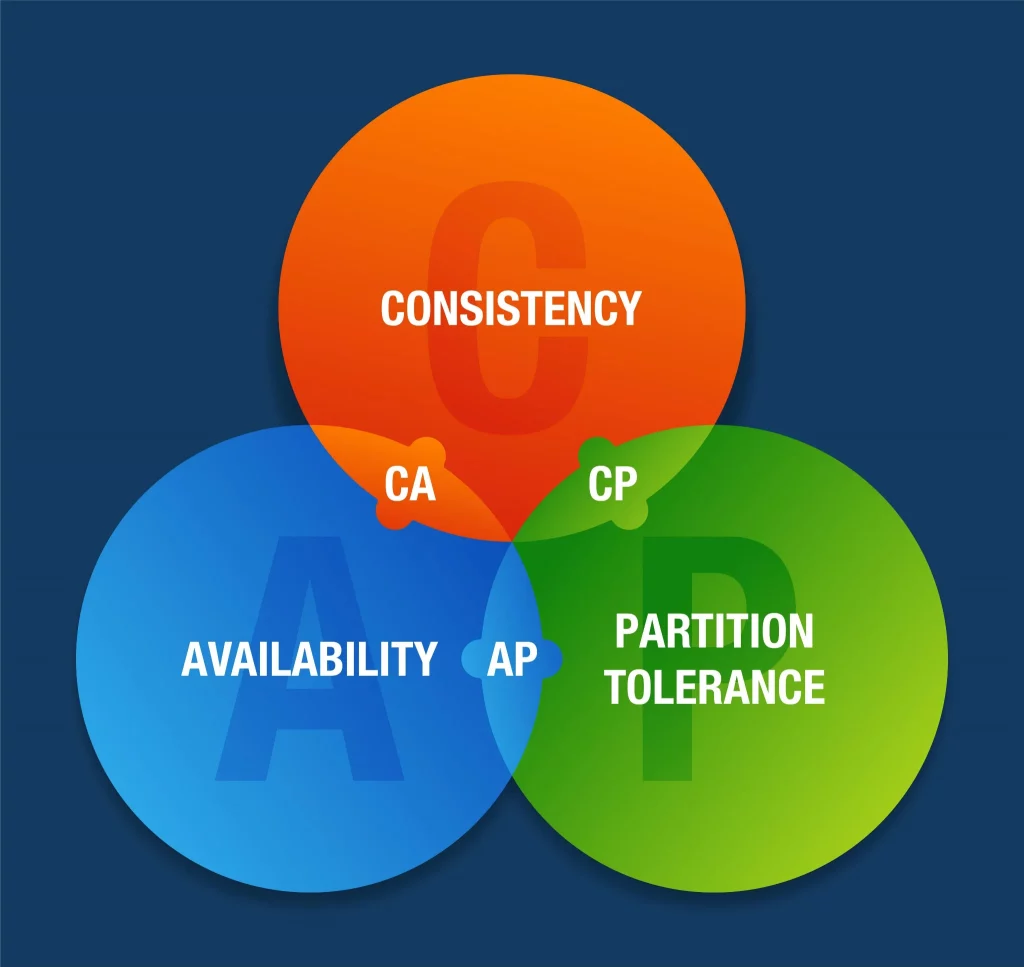
19. Describe the CAP Theorem (and why it matters).
The Interviewer’s Goal: To see if you understand the trade-offs in distributed systems.
The Answer: The CAP theorem states that a distributed data store can only guarantee two of the following three properties simultaneously:
- Consistency (C): Every read receives the most recent write or an error. (Data is instantly the same across all nodes).
- Availability (A): Every request receives a response, without the guarantee that it contains the most recent write. (The system stays up, even if data is slightly stale).
- Partition Tolerance (P): The system continues to operate despite messages being dropped or delayed between nodes.
In the real world of distributed data engineering, Partition Tolerance is not optional. Networks fail. Cables get cut. Therefore, we effectively have to choose between CP (Consistency) and AP (Availability).
- CP Example (Banking): If an ATM loses connection to the main bank server, it refuses the withdrawal. It prioritizes Consistency over Availability.
- AP Example (Social Media): If a server is slow, Instagram will still show you a feed, even if it's 30 seconds old. It prioritizes Availability over Consistency.
20. How do you validate Data Quality?
The Interviewer’s Goal: To see if you wait for a CEO to find a bug, or if you catch it automatically.
The Answer: Data quality isn't a one-time fix; it is a continuous process known as Data Observability. I implement automated checks at three specific stages:
- Volume Checks: Detecting "Silent Failures." (e.g., "We usually get 1 million rows/day. Today we got 500. Alert the team immediately.")
- Schema Validation: Ensuring the source system didn't change a data type (e.g., changing a UserID from Integer to String).
- Distribution/Statistical Checks: Detecting logic errors. (e.g., "The average order value is usually $50. Today it is $5,000. Something is wrong.")
I rely on tools like Great Expectations, dbt tests, or Soda to block bad data before it hits production dashboards.
21. Design a pipeline to ingest data from an API to a Warehouse.
The Interviewer’s Goal: To test your understanding of the ELT (Extract, Load, Transform) pattern.
The Answer: I design pipelines with "Replayability" in mind. Here is the architecture:
- Orchestration (Airflow/Prefect): This triggers the pipeline on a schedule and manages dependencies.
- The "Raw Landing" (S3/GCS): This is crucial. I extract the JSON from the API and dump it untouched into a Data Lake (S3).
- Why? If my transformation logic has a bug, I can fix the code and re-process the raw files without calling the slow API again.
- Loading (Snowflake/BigQuery): I load the raw JSON into a variant/struct column in the warehouse.
- Transformation (dbt): I use SQL to parse the JSON, clean the data, and model it into Fact and Dimension tables for the end users.
22. How do you handle Schema Evolution?
The Interviewer’s Goal: To see how you handle upstream changes breaking your code.
The Answer: When a source system adds, removes, or changes a column, it is the #1 cause of pipeline failure. I handle this in three ways:
- The Technical Fix (Schema Registry): For streaming (Kafka), I use a Schema Registry (like Confluent) which rejects incompatible messages that don't match the agreed-upon format (Protobuf/Avro).
- The Design Fix (Forward Compatibility): I build consumers that are resilient. They explicitly select columns they need (SELECT id, name) rather than using SELECT *, so new columns don't break the code.
- The Organizational Fix: This is the most effective. I implement a "Data Contract" where the software engineering team cannot change the database schema without alerting the data team first.
23. What is a Data Lakehouse?
The Interviewer’s Goal: Do you know the modern data stack?
The Answer: Historically, we had two silos:
- Data Lakes (S3/HDFS): Cheap storage for raw files. Great for AI/ML, but slow for BI queries. No ACID transactions.
- Data Warehouses (Snowflake/Redshift): Fast SQL performance and ACID compliance, but expensive and strictly structured.
A Data Lakehouse (like Databricks Delta Lake or Apache Iceberg) bridges this gap. It adds a metadata layer over the Data Lake files. This allows us to do ACID transactions (Updates/Deletes) and enforce schemas directly on cheap object storage (S3), giving us the "best of both worlds."
24. SQL vs. NoSQL: How do you choose?
The Interviewer’s Goal: Do you understand database modeling?
The Answer: It comes down to the structure of the data and the scaling requirements.
- Choose SQL (Relational - PostgreSQL/MySQL):
- When data integrity is critical (Financial ledgers).
- When the schema is rigid and defined upfront.
- When you need complex JOINS.
- Choose NoSQL (Document/Key-Value - MongoDB/DynamoDB):
- When the data structure is changing constantly (e.g., varied User Profiles).
- When you need massive Write Throughput.
- When you need to scale Horizontally (sharding) rather than Vertically.
25. Explain Partitioning vs. Bucketing.
The Interviewer’s Goal: Do you know how to optimize storage for performance?
The Answer: Both techniques reduce the amount of data we scan, but they work differently:
- Partitioning: Breaks data into folders based on a column (e.g., date=2024-01-01).
- Best for: Low cardinality columns (Year, Month, Country).
- Benefit: "Partition Pruning." The engine skips entire folders it doesn't need.
- Bucketing: Hashes data into a fixed number of files.
- Best for: High cardinality columns (User ID, Product ID).
- Benefit: It helps manage the "Small File Problem" and optimizes joins by keeping similar IDs in the same file.
26. Why do we need an Orchestrator (Airflow/Dagster)?
The Interviewer’s Goal: Why not just use Cron?
The Answer: Cron is fine for a single script, but it fails for Data Pipelines. An orchestrator like Airflow provides:
- Dependency Management: It ensures "Step B" only runs if "Step A" succeeded.
- Backfilling: The ability to easily re-run a pipeline for a specific date range in the past.
- Retries & Alerting: Automatically retrying a failed task (handling transient network glitches) and paging the engineer if it fails permanently.
- Visual DAGs: A UI to visualize the workflow and identify bottlenecks.
27. What is the hardest bug you ever resolved?
The Interviewer’s Goal: Are you persistent? Can you debug complex systems?
The Answer: Advice: Do not say "I missed a semicolon." Pick a logical or architectural bug.
"I once dealt with a pipeline that was randomly failing. After digging into the logs, I found it was a 'Silent Integer Overflow'.
We were using a standard INT for a primary key, and the business grew so fast that we hit the 2.1 billion limit. The database stopped accepting new rows, but didn't throw a clear error.
The Fix: I migrated the column to BIGINT, but I also wrote a 'Proactive Test' in our staging environment to alert us whenever any ID column reaches 80% of its capacity."
28. How do you handle PII (Personally Identifiable Information)?
The Interviewer’s Goal: Do you understand Security and Compliance (GDPR/CCPA)?
The Answer: Handling PII is about defense in depth:
- Least Privilege Access: I use Role-Based Access Control (RBAC). Only the HR team role can query the salary column.
- Encryption: Data is encrypted at rest (on disk) and in transit (TLS/SSL).
- Hashing/Masking: This is key for analytics. I hash email addresses (e.g., SHA256(email)). This allows Data Scientists to join tables on unique users without ever seeing the actual email address, maintaining privacy compliance.
29. Slow Query Optimization strategy?
The Interviewer’s Goal: Can you tune performance?
The Answer: When a query is slow, I follow this checklist:
- The Explain Plan: I look at the execution plan to see if the database is doing a "Full Table Scan."
- Partition Pruning: Are we filtering on the partition key? (e.g., WHERE date = today).
- Exploding Joins: I check if a join is creating a Cartesian product (row duplication) because of non-unique keys.
- Predicate Pushdown: I ensure we filter the data before joining it, not after.
30. Why do you want to be a Data Engineer?
The Interviewer’s Goal: Will you quit in 3 months because the work is hard?
The Answer: "I love the engineering challenge.
Data Scientists build the models, but Data Engineers build the roads those models drive on. I get satisfaction from taking messy, chaotic data and architecting a system that makes it reliable, fast, and usable for the whole company. I enjoy the blend of coding, architecture, and system design."
Master SQL and Database management with this SQL course: Practical training with guided projects, AI support, and expert instructors.
Also Read: How to Become a Data Engineer








