Introduction
Label encoding is a technique used in machine learning and data analysis to convert categorical variables into numerical format. It is particularly useful when working with algorithms that require numerical input, as most machine learning models can only operate on numerical data. In this explanation, we'll explore how label encoding works and how to implement it in Python.
Let's consider a simple example with a dataset containing information about different types of fruits, where the "Fruit" column has categorical values such as "Apple," "Orange," and "Banana." Label encoding assigns a unique numerical label to each distinct category, transforming the categorical data into numerical representation.
In this course, you will learn the fundamentals of Python: from basic syntax to mastering data structures, loops, and functions. You will also explore OOP concepts and objects to build robust programs.
To perform label encoding in Python, we can use the scikit-learn library, which provides a range of preprocessing utilities, including the LabelEncoder class. Here's a step-by-step guide:
- Import the necessary libraries:
pythonCopy codefrom sklearn.preprocessing import LabelEncoder
- Create an instance of the LabelEncoder class:
pythonCopy codelabel_encoder = LabelEncoder()
- Fit the label encoder to the categorical data:
pythonCopy codelabel_encoder.fit(categorical_data)
Here, categorical_data refers to the column or array containing the categorical values you want to encode.
- Transform the categorical data into numerical labels:
pythonCopy codeencoded_data = label_encoder.transform(categorical_data)
pythonCopy codeencoded_data = label_encoder.transform(categorical_data)
The transform method takes the original categorical data and returns an array with the corresponding numerical labels.
- If needed, you can also reverse the encoding to obtain the original categorical values using the
inverse_transformmethod:
pythonCopy codeoriginal_data = label_encoder.inverse_transform(encoded_data)
Label encoding can also be applied to multiple columns or features simultaneously. You can repeat steps 3-5 for each categorical column you want to encode.
It is important to note that label encoding introduces an arbitrary order to the categorical values, which may lead to incorrect assumptions by the model. To avoid this issue, you can consider using one-hot encoding or other methods such as ordinal encoding, which provide more appropriate representations for categorical data.
Label encoding is a simple and effective way to convert categorical variables into numerical form. By using the LabelEncoder class from scikit-learn, you can easily encode your categorical data and prepare it for further analysis or input into machine learning algorithms.
Now, let us first briefly understand what data types are and its scale. It is important to know this for us to proceed with categorical variable encoding. Data can be classified into three types, namely, structured data, semi-structured, and unstructured data.
Structured data denotes that the data represented is in matrix form with rows and columns. The data can be stored in database SQL in a table, CSV with delimiter separated, or excel with rows and columns.
The data which is not in matrix form can be classified into semi-Structured data (data in XML, JSON format) or unstructured data (emails, images, log data, videos, and textual data).
Let us say, for given data science or machine learning business problem if we are dealing with only structured data and the data collected is a combination of both Categorical variables and Continuous variables, most of the machine learning algorithms will not understand, or not be able to deal with categorical variables. Meaning, that machine learning algorithms will perform better in terms of accuracy and other performance metrics when the data is represented as a number instead of categorical to a model for training and testing.
Deep learning techniques such as the Artificial Neural network expect data to be numerical. Thus, categorical data must be encoded to numbers before we can use it to fit and evaluate a model.
Few ML algorithms such as Tree-based (Decision Tree, Random Forest ) do a better job in handling categorical variables. The best practice in any data science project is to transform categorical data into a numeric value.
Now, our objective is clear. Before building any statistical models, machine learning, or deep learning models, we need to transform or encode categorical data to numeric values. Before we get there, we will understand different types of categorical data as below.
MIT Professional Education's Data Science Course
Gain the expertise top companies seek and open doors to Data Science jobs.
Nominal Scale
The nominal scale refers to variables that are just named and are used for labeling variables. Note that all of A nominal scale refers to variables that are names. They are used for labeling variables. Note that all of these scales do not overlap with each other, and none of them has any numerical significance.
Below are the examples that are shown for nominal scale data. Once the data is collected, we should usually assign a numerical code to represent a nominal variable.
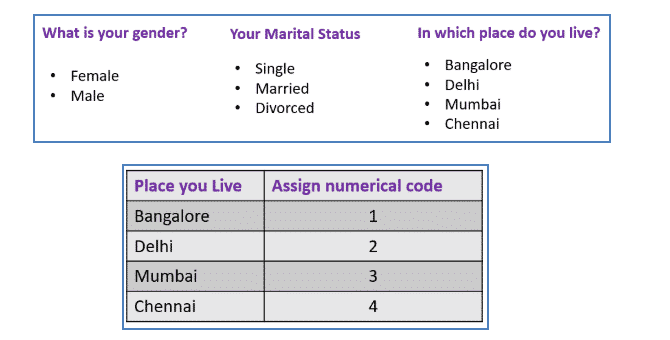
For example, we can assign a numerical code 1 to represent Bangalore, 2 for Delhi, 3 for Mumbai, and 4 for Chennai for a categorical variable- in which place do you live. Important to note that the numerical value assigned does not have any mathematical value attached to them. Meaning, that basic mathematical operations such as addition, subtraction, multiplication, or division are pointless. Bangalore + Delhi or Mumbai/Chennai does not make any sense.
Ordinal Scale
An Ordinal scale is a variable in which the value of the data is captured from an ordered set. For example, customer feedback survey data uses a Likert scale that is finite, as shown below.
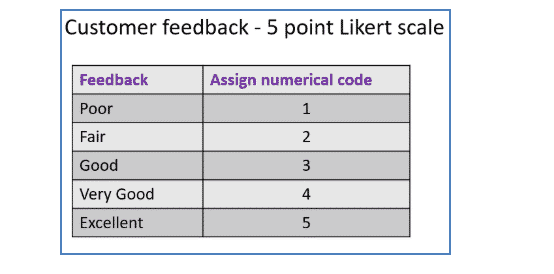
In this case, let’s say the feedback data is collected using a five-point Likert scale. The numerical code 1, is assigned to Poor, 2 for Fair, 3 for Good, 4 for Very Good, and 5 for Excellent. We can observe that 5 is better than 4, and 5 is much better than 3. But if you look at excellent minus good, it is meaningless.
We very well know that most machine learning algorithms work exclusively with numeric data. That is why we need to encode categorical features into a representation compatible with the models. Hence, we will cover some popular encoding approaches:
- Label encoding
- One-hot encoding
- Ordinal Encoding
Label Encoding
In label encoding in Python, we replace the categorical value with a numeric value between 0 and the number of classes minus 1. If the categorical variable value contains 5 distinct classes, we use (0, 1, 2, 3, and 4).
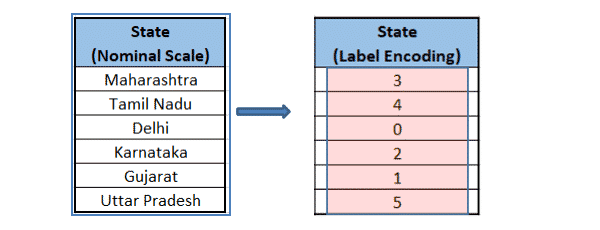
To understand label encoding with an example, let us take COVID-19 cases in India across states. If we observe the below data frame, the State column contains a categorical value that is not very machine-friendly and the rest of the columns contain a numerical value. Let us perform Label encoding for State Column.
From the below image, after label encoding, the numeric value is assigned to each of the categorical values. You might be wondering why the numbering is not in sequence (Top-Down), and the answer is that the numbering is assigned in alphabetical order. Delhi is assigned 0 followed by Gujarat as 1 and so on.
Label Encoding using Python
- Before we proceed with label encoding in Python, let us import important data science libraries such as pandas and NumPy.
- Then, with the help of panda, we will read the Covid19_India data file which is in CSV format and check if the data file is loaded properly. With the help of info(). We can notice that a state datatype is an object. Now we can proceed with LabelEncoding.
Label Encoding can be performed in 2 ways namely:
- LabelEncoder class using scikit-learn library
- Category codes
Approach 1 - scikit-learn library approach
As Label Encoding in Python is part of data preprocessing, hence we will take an help of preprocessing module from sklearn package and import LabelEncoder class as below:
And then:
- Create an instance of LabelEncoder() and store it in labelencoder variable/object
- Apply fit and transform which does the trick to assign numerical value to categorical value and the same is stored in new column called “State_N”
- Note that we have added a new column called “State_N” which contains numerical value associated to categorical value and still the column called State is present in the dataframe. This column needs to be removed before we feed the final preprocess data to machine learning model to learn
Approach 2 – Category Codes
- As you had already observed that "State" column datatype is an object type which is by default hence, need to convert "State" to a category type with the help of pandas
- We can access the codes of the categories by running covid19[“State].cat.codes
One potential issue with label encoding is that most of the time, there is no relationship of any kind between categories, while label encoding introduces a relationship.
In the above six classes’ example for “State” column, the relationship looks as follows: 0 < 1 < 2 < 3 < 4 < 5. It means that numeric values can be misjudged by algorithms as having some sort of order in them. This does not make much sense if the categories are, for example, States.
There is no such relation in the original data with the actual State names, but, by using numerical values as we did, a number-related connection between the encoded data might be made. To overcome this problem, we can use one-hot encoding as explained below.
One-Hot Encoding
In this approach, for each category of a feature, we create a new column (sometimes called a dummy variable) with binary encoding (0 or 1) to denote whether a particular row belongs to this category.
Let us consider the previous State column, and from the below image, we can notice that new columns are created starting from state name Maharashtra till Uttar Pradesh, and there are 6 new columns created. 1 is assigned to a particular row that belongs to this category, and 0 is assigned to the rest of the row that does not belong to this category.
A potential drawback of this method is a significant increase in the dimensionality of the dataset (which is called a Curse of Dimensionality).
Meaning, one-hot encoding is the fact that we are creating additional columns, one for each unique value in the set of the categorical attribute we'd like to encode. So, if we have a categorical attribute that contains, say, 1000 unique values, that one-hot encoding will generate 1,000 additional new attributes and this is not desirable.
To keep it simple, one-hot encoding is quite a powerful tool, but it is only applicable for categorical data that have a low number of unique values.
Creating dummy variables introduces a form of redundancy to the dataset. If a feature has three categories, we only need to have two dummy variables because, if an observation is neither of the two, it must be the third one. This is often referred to as the dummy-variable trap, and it is a best practice to always remove one dummy variable column (known as the reference) from such an encoding.
Data should not get into dummy variable traps that will lead to a problem known as multicollinearity. Multicollinearity occurs where there is a relationship between the independent variables, and it is a major threat to multiple linear regression and logistic regression problems.
To sum up, we should avoid label encoding in Python when it introduces false order to the data, which can, in turn, lead to incorrect conclusions. Tree-based methods (decision trees, Random Forest) can work with categorical data and label encoding. However, for algorithms such as linear regression, models calculating distance metrics between features (k-means clustering, k-Nearest Neighbors) or Artificial Neural Networks (ANN) are one-hot encoding.
One-Hot Encoding using Python
Now, let's see how to apply one-hot encoding in Python. Getting back to our example, in Python, this process can be implemented using 2 approaches as follows:
- scikit-learn library
- Using Pandas
Approach 1 - scikit-learn library approach
- As one-hot encoding is also part of data preprocessing, hence we will take an help of preprocessing module from sklearn package and them import OneHotEncoder class as below
- Instantiate the OneHotEncoder object, note that parameter drop = ‘first’ will handle dummy variable traps
- Perform OneHotEncoding for categorical variable
4. Merge One Hot Encoded Dummy Variables to Actual data frame but do not forget to remove the actual column called “State”
5. From the below output, we can observe, dummy variable trap has been taken care
Approach 2 – Using Pandas: with the help of get_dummies function
- As we all know, one-hot encoding is such a common operation in analytics, that pandas provide a function to get the corresponding new features representing the categorical variable.
- We are considering the same dataframe called “covid19” and imported pandas library which is sufficient to perform one hot encoding
- As you notice below code, this generates a new DataFrame containing five indicator columns, because as explained earlier for modeling we don't need one indicator variable for each category; for a categorical feature with K categories, we need only K-1 indicator variables. In our example, “State_Delhi” was removed
- In the case of 6 categories, we need only five indicator variables to preserve the information (and avoid collinearity). That is why the pd.get_dummies function has another Boolean argument, drop_first=True, which drops the first category
- Since the pd.get_dummies function generates another DataFrame, we need to concatenate (or add) the columns to our original DataFrame and also don’t forget to remove column called “State”
- Here, we use the pd.concat function, indicating with the axis=1 argument that we want to concatenate the columns of the two DataFrames given in the list (which is the first argument of pd.concat). Don’t forget to remove actual “State” column
Ordinal Encoding
An Ordinal Encoder is used to encode categorical features into an ordinal numerical value (ordered set). This approach transforms categorical value into numerical value in ordered sets.
This encoding technique appears almost similar to Label Encoding. But, label encoding would not consider whether a variable is ordinal or not, but in the case of ordinal encoding, it will assign a sequence of numerical values as per the order of data.
Let’s create a sample ordinal categorical data related to the customer feedback survey, and then we will apply the Ordinal Encoder technique. In this case, let’s say the feedback data is collected using a Likert scale in which numerical code 1 is assigned to Poor, 2 for Good, 3 for Very Good, and 4 for Excellent. If you observe, we know that 5 is better than 4, 5 is much better than 3, but taking the difference between 5 and 2 is meaningless (Excellent minus Good is meaningless).
Ordinal Encoding using Python
With the help of Pandas, we will assign customer survey data to a variable called “Customer_Rating” through a dictionary and then we can map each row for the variable as per the dictionary.
That brings us to the end of the blog on Label Encoding in Python. We hope you enjoyed this blog. Also, check out this Free Python for Beginners course to learn the Fundamentals of Python. If you wish to explore more such courses and learn new concepts, join the Great Learning Academy free course today.
Embarking on a journey towards a career in data science opens up a world of limitless possibilities. Whether you’re an aspiring data scientist or someone intrigued by the power of data, understanding the key factors that contribute to success in this field is crucial. The below path will guide you to become a proficient data scientist.