NER, short for, Named Entity Recognition is a standard Natural Language Processing problem which deals with information extraction. The primary objective is to locate and classify named entities in text into predefined categories such as the names of persons, organizations, locations, events, expressions of times, quantities, monetary values, percentages, etc.
To put it simply, NER deals with extracting the real-world entity from the text such as a person, an organization, or an event. Named Entity Recognition is also simply known as entity identification, entity chunking, and entity extraction. They are quite similar to POS(part-of-speech) tags.
NER using NLTK
NLTK is a standard python library with prebuilt functions and utilities for the ease of use and implementation. It is one of the most used libraries for natural language processing and computational linguistics.
Recognizing named entities in a large corpus can be a challenging task, but NLTK has built-in method ‘nltk.ne_chunk()’ that can recognize various entities shown in the table below:
| NE Type | Examples |
| ORGANIZATION | Georgia-Pacific Corp., WHO |
| PERSON | Eddy Bonte, President Obama |
| LOCATION | Murray River, Mount Everest |
| DATE | June, 2008-06-29 |
| TIME | two fifty a.m, 1:30 p.m. |
| MONEY | 175 million Canadian Dollars, GBP 10.40 |
| PERCENT | twenty pct, 18.75 % |
| FACILITY | Washington Monument, Stonehenge |
| GPE | South-East Asia, Midlothian |
Here is an example of how we can recognize named entities using NLTK. I used a sentence out of an article by “Times of India” for the purpose of demonstration
'''Prime Minister Jacinda Ardern has claimed that New Zealand had won a big
battle over the spread of coronavirus. Her words came as the country begins to exit from its lockdown.'''
If the NLTK library is not installed in your machine, type the below code and run in the terminal or command prompt to download it
pip install nltkLet us start by importing important libraries and their submodules.
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
Next, we tokenize this sentence into words by using the method ‘word_tokenize()’.Also, we tag each word with their respective Part-of-Speech tags using the ‘pos_tag()’
sent= '''Prime Minister Jacinda Ardern has claimed that New Zealand had won a big
battle over the spread of coronavirus. Her words came as the country begins to exit from its lockdown.'''
words= word_tokenize(sent)
postags=pos_tag(words)
The next step is to use ne_chunk() to recognize each named entity in the sentence.
ne_tree = nltk.ne_chunk(postags,binary=False)
pprint(ne_tree)Output:
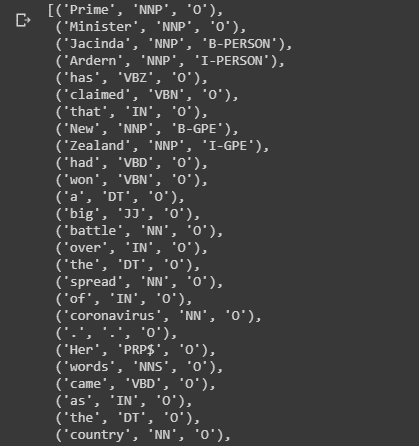
Tree('S', [('Prime', 'NNP'), ('Minister', 'NNP'), Tree('PERSON', [('Jacinda', 'NNP'), ('Ardern', 'NNP')]), ('has', 'VBZ'), ('claimed', 'VBN'), ('that', 'IN'), Tree('GPE', [('New', 'NNP'), ('Zealand', 'NNP')]), ('had', 'VBD'), ('won', 'VBN'), ('a', 'DT'), ('big', 'JJ'), ('battle', 'NN'), ('over', 'IN'), ('the', 'DT'), ('spread', 'NN'), ('of', 'IN'), ('coronavirus', 'NN'), ('.', '.'), ('Her', 'PRP$'), ('words', 'NNS'), ('came', 'VBD'), ('as', 'IN'), ('the', 'DT'), ('country', 'NN'), ('begins', 'VBZ'), ('to', 'TO'), ('exit', 'VB'), ('from', 'IN'), ('its', 'PRP$'), ('lockdown', 'NN'), ('.', '.')])As you can see, Jacinda Ardern is chunked together and classified as a person. Also, note that the binary parameter in the ne_chunck has been set to ‘False’.If this parameter is set to True, the output just points out the named entity as NE instead of the type of named entity as shown below:
ne_tree = nltk.ne_chunk(postags,binary=True)
pprint(ne_tree)Output:
Tree('S', [('Prime', 'NNP'), ('Minister', 'NNP'), Tree('NE', [('Jacinda', 'NNP'), ('Ardern', 'NNP')]), ('has', 'VBZ'), ('claimed', 'VBN'), ('that', 'IN'), Tree('NE', [('New', 'NNP'), ('Zealand', 'NNP')]), ('had', 'VBD'), ('won', 'VBN'), ('a', 'DT'), ('big', 'JJ'), ('battle', 'NN'), ('over', 'IN'), ('the', 'DT'), ('spread', 'NN'), ('of', 'IN'), ('coronavirus', 'NN'), ('.', '.'), ('Her', 'PRP$'), ('words', 'NNS'), ('came', 'VBD'), ('as', 'IN'), ('the', 'DT'), ('country', 'NN'), ('begins', 'VBZ'), ('to', 'TO'), ('exit', 'VB'), ('from', 'IN'), ('its', 'PRP$'), ('lockdown', 'NN'), ('.', '.')])IOB tagging
The IOB format (short for inside, outside, beginning) is a tagging format that is used for tagging tokens in a chunking task such as named-entity recognition. These tags are similar to part-of-speech tags but give us information about the location of the word in the chunk. The IOB Tagging system contains tags of the form:
- B-{CHUNK_TYPE} – for the word in the Beginning chunk
- I-{CHUNK_TYPE} – for words Inside the chunk
- O – Outside any chunk
Here’s how to convert between the nltk.Tree and IOB format for the example we did in the previous section:
from nltk.chunk import tree2conlltags
from pprint import pprint
iob_tagged = tree2conlltags(ne_tree)
pprint(iob_tagged)
Output:
NER using SpaCy
SpaCy is an open-source library for advanced Natural Language Processing written in the Python and Cython. It can be used to build information extraction or natural language understanding systems or to pre-process text for deep learning. Some of the features provided by spaCy are- Tokenization, Parts-of-Speech (PoS) Tagging, Text Classification, and Named Entity Recognition which we are going to use here.
SpaCy provides a default model that can recognize a wide range of named or numerical entities, which include person, organization, language, event, etc. Apart from these default entities, we can also add arbitrary classes to the NER model, by training the model to update it with newer trained examples.
SpaCy’s named entity recognition has been trained on the OntoNotes 5 corpus and it recognizes the following entity types.
First, let us install the SpaCy library using the pip command in the terminal or command prompt as shown below.
pip install spacy
python -m spacy download en_core_web_sm
Next, we import all the necessary libraries
from pprint import pprint
import spacy
from spacy import displacy
nlp = spacy.load('en_core_web_sm')
sentence = '''Prime Minister Jacinda Ardern has claimed that New Zealand had won a big
battle over the spread of coronavirus. Her words came as the country begins to exit from its lockdown.'''
entities= nlp(sentence)
#to print all the entities with iob tags
pprint([ (X, X.ent_iob_, X.ent_type_) for X in entities] )
#to print just named entities use this code
print("Named entities in this text are\n")
for ent in entities.ents:
print(ent.text,ent.label_)
# visualize named entities
displacy.render(entities, style='ent', jupyter=True)
Output:
[(Prime, 'O', ''),
(Minister, 'O', ''),
(Jacinda, 'B', 'PERSON'),
(Ardern, 'I', 'PERSON'),
(has, 'O', ''),
(claimed, 'O', ''),
(that, 'O', ''),
(New, 'B', 'GPE'),
(Zealand, 'I', 'GPE'),
(had, 'O', ''),
(won, 'O', ''),
(a, 'O', ''),
(big, 'O', ''),
(
, 'O', ''),
(battle, 'O', ''),
(over, 'O', ''),
(the, 'O', ''),
(spread, 'O', ''),
(of, 'O', ''),
(coronavirus, 'O', ''),
(., 'O', ''),
(Her, 'O', ''),
(words, 'O', ''),
(came, 'O', ''),
(as, 'O', ''),
(the, 'O', ''),
(country, 'O', ''),
(begins, 'O', ''),
(to, 'O', ''),
(exit, 'O', ''),
(from, 'O', ''),
(its, 'O', ''),
(lockdown, 'O', ''),
(., 'O', '')]
Named entities in this text are
Jacinda Ardern PERSON
New Zealand GPE
But does SpaCy always give us the desired results? Here is an example where SpaCy is not able to properly identify named entity
sentence = '''i use google to search. Google is a large IT company'''
entities= nlp(sentence)
pprint([ (X, X.ent_iob_, X.ent_type_) for X in entities] )
Output:
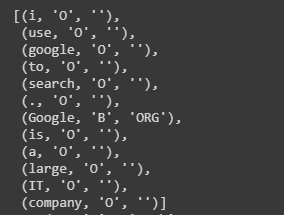
As we can see, SpaCy could not recognize google as a named entity. So should we ignore this problem or do something about it?
Luckily we can also use our own examples to train and modify spaCy’s in-built NER model. There are several ways to do this. The following code from the official website of spacy shows a simple way to feed in new instances and update the model.
import random
from spacy.gold import GoldParse
#the training data with named entity NE needs to be of this format
# ( "training example",[(strat position of NE,end position of NE,"type of NE")] )
train_data = [
("Uber blew through $1 million a week", [(0, 4, 'ORG')]),
("Android Pay expands to Canada", [(0, 11, 'PRODUCT'), (23, 30, 'GPE')]),
("Spotify steps up Asia expansion", [(0, 8, "ORG"), (17, 21, "LOC")]),
("Google Maps launches location sharing", [(0, 11, "PRODUCT")]),
("Google rebrands its business apps", [(0, 6, "ORG")]),
("look what i found on google! 😂", [(21, 27, "PRODUCT")])]
#An optimizer is set to update the model’s weights.
optimizer = nlp.begin_training()
for itn in range(100):
random.shuffle(train_data)
for raw_text, entity_offsets in train_data:
doc = nlp.make_doc(raw_text)
gold = GoldParse(doc, entities=entity_offsets)
nlp.update([doc], [gold], drop=0.25, sgd=optimizer)
#setting drop makes it harder for the model to just memorize the data.
nlp.to_disk("/model")
Now after training the existing model with our new examples and updating the nlp,let us check out if the word google is now recognised as a named entity.Also it is better if our training data is larger in size so that the model can generalize better.
from pprint import pprint
sentence_1 = '''i use google to search. Google is a large IT company'''
sentence_2='''Prime Minister Jacinda Ardern has claimed that New Zealand had won a big
battle over the spread of coronavirus. Her words came as the country begins to exit from its lockdown.'''
entities_1= nlp(sentence_1)
entities_2=nlp(sentence_2)
#to print just named entities use this code
print("Named entities in this text are\n")
for ent in entities_1.ents:
print(ent.text,ent.label_)
for ent in entities_2.ents:
print(ent.text,ent.label_)
Output:

Now as we can see, at the first occurrence of google it is successfully recognised as a product and next time again it is correctly recognised as an organization. Also, there has been no change to the results of the previous sentence we tested.
To further demonstrate the power of SpaCy, we retrieve the named entity from an article and here are the results

Applications of NER
NER, short for, Named Entity Recognition has a wide range of applications in the field of Natural Language Processing and Information Retrieval. Few such examples have been listed below :
Classifying content for news providers: A large amount of online content is generated by the news and publishing houses on a daily basis and managing them correctly can be a challenging task for the human workers. Named Entity Recognition can automatically scan entire articles and help in identifying and retrieving major people, organizations, and places discussed in them. Thus articles are automatically categorized in defined hierarchies and the content is also much easily discovered.
Automatically Summarizing Resumes: You might have come across various tools that scan your resume and retrieve important information such as Name, Address, Qualification, etc from them. The majority of such tools use the NER software which helps it to retrieve such information. Also one of the challenging tasks faced by the HR Departments across companies is to evaluate a gigantic pile of resumes to shortlist candidates. A lot of these resumes are excessively populated in detail, of which, most of the information is irrelevant to the evaluator. Using the NER model, the relevant information to the evaluator can be easily retrieved from them thereby simplifying the effort required in shortlisting candidates among a pile of resumes.
Optimizing Search Engine Algorithms: When designing a search engine algorithm, It would be an inefficient and computational task to search for an entire query across the millions of articles and websites online, an alternate way is to run a NER model on the articles once and store the entities associated with them permanently. Thus for a quick and efficient search, the key tags in the search query can be compared with the tags associated with the website articles
Powering Recommendation systems: NER can be used in developing algorithms for recommender systems that make suggestions based on our search history or on our present activity. This is achieved by extracting the entities associated with the content in our history or previous activity and comparing them with the label assigned to other unseen content. Thus we frequently see the content of our interest.
Simplifying Customer Support: Usually, a company gets tons of customer complaints and feedback on a daily basis, and going through each one of them and recognizing the concerned parties is not an easy task. Using NER we can recognize relevant entities in customer complaints and feedback such as Product specifications, department, or company branch location so that the feedback is classified accordingly and forwarded to the appropriate department responsible for the identified product.
This brings us to the end of this article where we have learned about various ways to detect named entities in the text using NER and its various applications.
If you wish to learn more about Python and the concepts of Machine Learning, upskill with Great Learning’s PG Program Artificial Intelligence and Machine Learning.