Web scraping is the automated extraction of data from websites. A web scraper is a tool that performs this data extraction. It works by sending requests to web servers, receiving HTML content, and then parsing that content to pull out specific information. Python is a popular choice for web scraping due to its powerful libraries.
You can scrape web data by following a clear process. This approach helps ensure you gather the right information while respecting website guidelines.
In this course, you will learn the fundamentals of Python: from basic syntax to mastering data structures, loops, and functions. You will also explore OOP concepts and objects to build robust programs.
Step 1: Understand Website Structure
Before you write any code, you need to understand the website you plan to scrape.
Inspect the Website's HTML:
Open the website in your browser. Right-click on the element you want to scrape and select "Inspect" or "Inspect Element." This opens your browser's developer tools, showing you the HTML structure of the page.
You will see tags like <div>, <p>, <a>, <span>, and attributes like class and id. Identify the unique tags or attributes that contain the data you need.
Step 2: Set Up Your Python Environment
You need Python installed on your system. Python 3 is the current standard. You also need to install specific libraries for web scraping.
Install Python:
Download and install Python from the official Python website if you do not have it.
Install Required Libraries:
You will use requests to fetch web page content and Beautiful Soup 4 (bs4) to parse the HTML.
Use pip to install these libraries:
pip install requests beautifulsoup4
- requests: This library simplifies sending HTTP requests. You use it to get the raw HTML content of a web page.
- BeautifulSoup: This library helps parse HTML and XML documents. It creates a parse tree that lets you navigate, search, and extract data easily.
Master Data Science with Python Course
Learn Data Science with Python in this comprehensive course! From data wrangling to machine learning, gain the expertise to turn raw data into actionable insights with hands-on practice.
Step 3: Fetch the Web Page Content
You use the requests library to download the HTML content of the target URL.
Send a GET Request:
The requests.get() function sends an HTTP GET request to the specified URL. This fetches the web page.
Here’s how to do it:
import requests
url = "https://quotes.toscrape.com/page/1/" # Example URL for practice
response = requests.get(url)
if response.status_code == 200:
print("Successfully retrieved the page.")
html_content = response.text
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
response.status_code: This checks if the request was successful. A200status code means the request was successful. Codes like404(Not Found) or500(Internal Server Error) indicate problems.response.text: This contains the raw HTML content of the web page as a string.
Step 4: Parse HTML with Beautiful Soup
Once you have the HTML content, you use Beautiful Soup to parse it. This converts the raw HTML string into a structured object that you can easily navigate and search.
Create a Beautiful Soup Object:
Pass the HTML content and a parser (like html.parser) to the BeautifulSoup constructor.
from bs4 import BeautifulSoup
# Assuming html_content is already obtained from Step 3
soup = BeautifulSoup(html_content, 'html.parser')
Find Elements:
Beautiful Soup provides methods to find specific HTML elements:
find(): Returns the first matching element.find_all(): Returns a list of all matching elements.
You can search by tag name, attributes (like class or id), or CSS selectors.
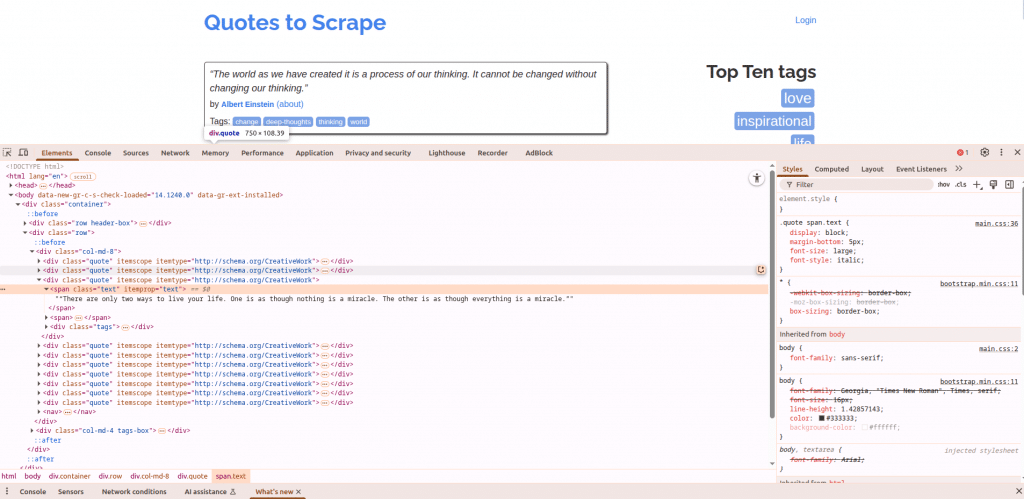
Example: Extracting Quotes from a Page
Let's say you want to scrape quotes and authors from https://quotes.toscrape.com/.
Looking at the HTML structure, you might see:
<div class="quote">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>
by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<a class="tag" href="/tag/change/ability-labels/adults/">change</a>
<a class="tag" href="/tag/deep-thoughts/life/thinking/world/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/"></a>
</div>
</div>
To extract quotes and authors:
quotes = soup.find_all('div', class_='quote')
for quote_div in quotes:
text = quote_div.find('span', class_='text').text.strip()
author = quote_div.find('small', class_='author').text.strip()
print(f"Quote: {text}\nAuthor: {author}\n---")
soup.find_all('div', class_='quote'): Finds all<div>elements with the classquote.quote_div.find('span', class_='text'): Inside each quote div, finds the<span>element with the classtext..text.strip(): Extracts the visible text content and removes leading/trailing whitespace.
Step 5: Store the Scraped Data
After extracting the data, you need to store it. Common formats include CSV files, JSON files, or databases.
Saving to a CSV File:
CSV (Comma Separated Values) is a simple, human-readable format for tabular data.
import csv
# Assuming you have a list of dictionaries, where each dictionary is a quote
# For example:
# scraped_data = [
# {'quote': '...', 'author': '...'},
# {'quote': '...', 'author': '...'}
# ]
# Let's create some sample data for demonstration
scraped_data = []
quotes = soup.find_all('div', class_='quote')
for quote_div in quotes:
text = quote_div.find('span', class_='text').text.strip()
author = quote_div.find('small', class_='author').text.strip()
scraped_data.append({'quote': text, 'author': author})
csv_file = 'quotes.csv'
csv_columns = ['quote', 'author']
try:
with open(csv_file, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=csv_columns)
writer.writeheader()
for data in scraped_data:
writer.writerow(data)
print(f"Data saved to {csv_file}")
except IOError:
print("I/O error while writing to CSV.")
csv.DictWriter: Writes dictionaries to a CSV file.fieldnames: Specifies the column headers.writer.writeheader(): Writes the header row.writer.writerow(data): Writes each row of data.
Saving to a JSON File:
JSON (JavaScript Object Notation) is a lightweight data-interchange format, great for structured data.
import json
# Assuming scraped_data is a list of dictionaries as above
json_file = 'quotes.json'
try:
with open(json_file, 'w', encoding='utf-8') as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=4)
print(f"Data saved to {json_file}")
except IOError:
print("I/O error while writing to JSON.")
json.dump(): Writes the Python object to a JSON file.ensure_ascii=False: Ensures non-ASCII characters are written correctly.indent=4: Formats the JSON output with an indent for readability.
Complete Code Example: Scraping Quotes
Here’s a complete Python script that combines all the steps to scrape quotes and authors from quotes.toscrape.com and save them to a CSV file.
import requests
from bs4 import BeautifulSoup
import csv
def scrape_quotes(url):
"""
Scrapes quotes and authors from a given URL.
"""
response = requests.get(url)
scraped_data = []
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
quotes = soup.find_all('div', class_='quote')
for quote_div in quotes:
try:
text = quote_div.find('span', class_='text').text.strip()
author = quote_div.find('small', class_='author').text.strip()
scraped_data.append({'quote': text, 'author': author})
except AttributeError:
# Handle cases where an element might be missing
print(f"Skipping a quote due to missing data in: {quote_div.prettify()}")
continue
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
return scraped_data
def save_to_csv(data, filename='quotes.csv'):
"""
Saves a list of dictionaries to a CSV file.
"""
if not data:
print("No data to save.")
return
csv_columns = list(data[0].keys()) # Get column names from the first dictionary
try:
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=csv_columns)
writer.writeheader()
for row in data:
writer.writerow(row)
print(f"Data successfully saved to {filename}")
except IOError:
print(f"I/O error while writing to {filename}.")
if __name__ == "__main__":
target_url = "https://quotes.toscrape.com/"
all_quotes = scrape_quotes(target_url)
save_to_csv(all_quotes)
To run this code:
- Save it as a Python file (e.g.,
quote_scraper.py). - Make sure you have
requestsandbeautifulsoup4installed (pip install requests beautifulsoup4). - Run the script from your terminal:
python quote_scraper.py.
This script will create a quotes.csv file in the same directory, containing the scraped quotes and authors.
Best Practices for Web Scraping
To ensure your web scraping is effective and responsible, follow these guidelines:
- Handle Pagination: Many websites display data across multiple pages. You need to identify the URL pattern for pagination (e.g.,
page=1,page=2) and loop through them to scrape all data. - Dynamic Content (JavaScript): If a website loads content using JavaScript after the initial page load,
requestsand Beautiful Soup alone may not be enough. You might need a headless browser like Selenium. Selenium automates a real browser (like Chrome or Firefox) to render JavaScript and interact with elements before scraping the content. - Error Handling and Retries: Websites can have temporary issues or change their structure. Implement
try-exceptblocks to catch errors (e.g., network issues, missing elements). Use exponential backoff for retries, waiting longer after each failed attempt. - User-Agent Rotation: Websites can block requests from a single User-Agent if they detect excessive scraping. Rotate User-Agents to mimic different browsers.
- Proxy Servers: To avoid IP bans, especially for large-scale scraping, use proxy servers to route your requests through different IP addresses.
- Data Cleaning: Scraped data often contains inconsistencies or unwanted characters. Clean and normalize the data before storing or using it.
- Stay Updated: Websites frequently change their structure. Your scraper might break. Regularly check the website and update your scraping script as needed.