Every machine learning engineer works with statistics and data analysis while building any model and a statistician makes no sense until he knows Bayes theorem. We will be discussing an algorithm which is based on Bayes theorem and is one of the most adopted algorithms when it comes to text mining. We are talking about Naïve Bayes. Naïve Bayes is one such algorithm which is supervised and depends on the probabilities of the events to occur. Naïve Bayes is considered has naïve because of the independence of one attribute in a class with respect to others. In simple words, it does not hold any dependence with two attributes having the same class. Before explaining further, an example is always a better choice. Let us take a few apples which are red and have an average diameter of 5 inches. Now if a Naïve Bayes predicts the probability of a red fruit having 4 inches being an apple, then it holds no dependency between color and diameter. Before trying to deep dive in Naïve Bayes, it is essential to learn the fundamentals.
Post Graduate Program in Data Science with Generative AI: Applications to Business
Learn how to turn data into strategy in this UT Data Science and Business Analytics Course — now with a focus on Generative AI. Gain practical experience through 7 hands-on projects over a 7-month duration.
Probability Fundamentals
Now we have at least an idea on how a Naïve Bayes algorithm works. Probability of an event is defined as the ratio of the number of trails of the occurrence of an event to the total number of trails. For example, if we randomly pick 10 balls from a bag which contains both red and blue balls and 4 out of 10 are found to be red balls, then the probability of red balls is 4/10 or 0.4. However, the total probability of all the outcomes should sum up to 100 percent. Now let us understand the concept of joint and conditional probability.
Joint Probability
Joint probability can be defined as a chance or likelihood that two events will happen at the same time although they remain independent on each other. This also implies that the outcome of one event cannot influence the outcome of others. Let us explain with an example.
Let us assume we are building an email classification model and we are considering that the word ‘lottery’ present in any message is spam. It is also possible that all the messages with the word ‘lottery’ are not spam nor all the messages which are spam contain the word ‘lottery’. Let us explain with a Venn diagram for much better interpretation.
Now from the Venn diagram, let us assume 10 percent of all emails are spam and 5 percent are the emails that contain the word ‘lottery’. Now if we have to calculate the joint probability of both that is, probability of the message being spam and the word ‘lottery’ occurring in a message, we can do the following.
p(spam ∩lottery) = p(spam) * p(lottery) = 0.1 * 0.05 = 0.005
Now we can say that of all the messages, 5 percent are spam having the word ‘lottery’. This much is enough for now. There is a lot left.
Conditional Probability
Conditional probability is actually what we are looking for. Naïve Bayes which works on Bayes theorem is totally based on conditional probability which is the probability of the outcome of an event given that another event has already occurred. If A and B are two events, then the conditional probability of both the events is given by
Now if we again consider the email classification example, considering prior probability of the message being a spam and the marginal likelihood of the word ‘lottery’ occurring in all messages, then the conditional probability can be calculated as
Assumptions
Naïve Bayes only assumes one fact that one event in a class should be independent of another event belonging to the same class. The algorithm also assumes that the predictors have an equal effect on the outcomes or responses in the data.
Types of Naïve Bayes
There are three types of Naïve Bayes classifier
- Multinomial Naïve Bayes
It is completely used for text documents where the text belongs to a class. The attributes required for this classification are basically the frequency of the words that are converted from the text document.
2. Bernoulli Naïve Bayes
This type of algorithm is useful in data having binary features. The features can be of value yes or not, granted or not granted, useful or useless, etc.
3. Gaussian Naïve Bayes
It is a simple algorithm which is used when the features are continuous in nature. The features present in the data happen to follow a Gaussian distribution.
Master AI with Microsoft AI Professional Program
Gain industry-ready AI skills through real-world projects and earn a Microsoft-recognized certification to elevate your tech career.
Advantages and Disadvantages
Naïve Bayes algorithm is very easy to implement when it comes to text data. Besides discussing the concept, let us walk through some of its advantages.
- It is super friendly with text mining
- Convergence is quicker than models like logistic regression that are discriminative in nature
- It performs well even when the data does not follow the assumptions it holds.
The only disadvantage of this algorithm is that it fails to find a relationship between features. Even when the features have a strong relationship with each other, then definitely Naïve Bayes is a bad choice. Another thing to keep in mind is it allots zero probability to the outcome when the predictor category is not present in the training data.
Applications.
- For social media marketing
In the world of social media, millions of text data is generated every second and Naïve Bayes is great in classifying text data. Suppose if we have to detect a fake twitter user based on his tweets or age of the account or profile information, then Naïve Bayes can be helpful. Also it can give relief to many service providers by detecting frauds and spammers who are looting customers by claiming their name.
The above image tells us a word cloud of tweets made by two twitter users and in this data, Naïve Bayes classifier works well and can predict classes such as gender of the user, character, mindset, etc. On such factors, twitter can react depending on their set of rules.
2. For media marketing
In the film industry, reviews and word of mouth play a very important role for movies and shows. Naïve Bayes model can predict the verdict based on them. Also, Naïve Bayes can be used in journalism sectors where millions of text data are generated every minute.
The above image tells us the audience reactions of movies and their ratings. The data is completely textual and in this case, Naïve Bayes can predict any unseen movie rating based on the frequency of the words used in reactions.
3. For product management
Even product reviews can be a concern to companies and sellers where marketing involves a lot of stakes. Naïve Bayes can classify the quality of the product based on such criteria. Also it can be a mitigation measure and high sigh of relief for such company owners.
The representation contains reviews of a restaurant where some people are loving it and some are not. For such cases, Naïve Bayes can be a choice for the owner.
Case Study in Python
Enough of theory and intuition. Time for coding.
We will be performing a Naïve Bayes Classifier using Python. The model will be built on a social network data which contains information such as UserId, gender, age, estimated price and whether they purchased or not.
Initially, we will import the libraries for data manipulation and visualization.

Now let us import the dataset and see what it contains. We will also remove unnecessary columns which we will not include while building the model.


Now we will split the data for training and testing. The split ratio depends on the size of the data. Though our data size is normal so we will split 75% data for training and rest for testing. Of course that makes 25%.

We will also perform standardization of the data to reduce the variance and increase the accuracy. As a part of preprocessing, it is always necessary to standardize the features if it contains too much numeric values because they have tendency to have much variation which cannot be left unconsidered.

Now it is time to fit our classifier. In this case, we will be using Gaussian Naïve Bayes. Why? Let’s not jump back to fundamentals. It simply contains numeric values so no need of Multinomial or a Bernoulli classifier.

The model is built on training data. Now it is time to see the result on our test data.
#Predicting the Test set results
y_pred = classifier.predict(X_test)
Now we will evaluate the model to judge how well it is performing.


The confusion matrix seems to be quite good. We just need to focus on the diagonal that is True and False positive rates.
report= classification_report(y_test, y_pred)
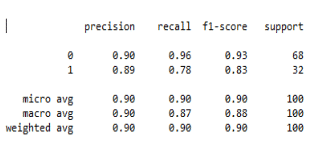
Now we can finally tell that the model is superb in classifying classes as the class 1 were usually less still it did not fail to surprise us.
Now it is time to visualize the data.

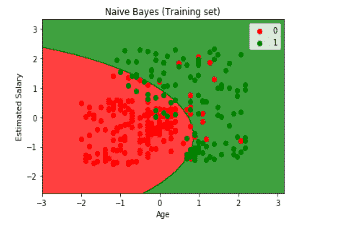
Now let us see how the predictions of test data looks like

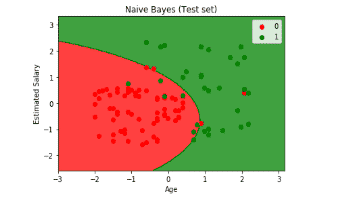
From both the visualization, we can confirm that the model is superb and we did not waste our time.
As we have got an idea on how to deal with data that contains numeric values but we still did not see how to perform text analysis using Python. In this case, we will be using Multinomial Naïve Bayes classifier.
The data we will be using will be the movie reviews data and it contains labels such as positive and negative. Let us take care of the libraries as usual
import numpy as np
import pandas as pd
Now let us jump into the data
Now we will see if the data contains any missing values and we will try to remove it.

As we see the empty values are removed and we have got a new size. Now it is time for preprocessing. We will convert text into numeric vectors to meet the assumptions of Naïve Bayes classifier which considers only numeric data.
Technically, we're dealing with "whitespace only" strings. If the original .tsv file had contained empty strings, pandas .read_csv() would have assigned NaN values to those cells by default.
In order to detect these strings we need to iterate over each row in the DataFrame. The .itertuples() pandas method is a good tool for this as it provides access to every field. For brevity we'll assign the names i, lb and rv to the index, label and review columns.
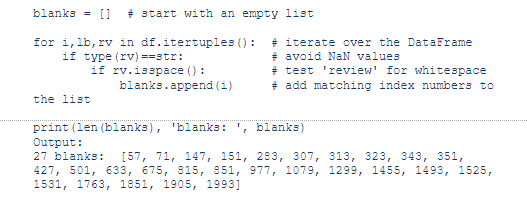
Next we'll pass our list of index numbers to the .drop() method, and set inplace=True to make the change permanent.

Great! We dropped 62 records from the original 2000. Let's continue with the analysis.
Now let us check how imbalanced is our data.

So here we see our labels of the data are balanced. Now we will directly go for splitting and train our model using Multinomial Naïve Bayes classifier
Now for training and fitting the model, we will have to vectorize all the text data. So we will do all the three things using a pipeline to save our time.

Now let us see other evaluation measures such as precision, recall and F1 score.
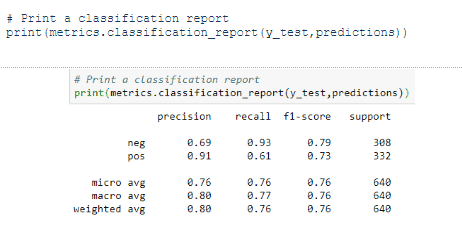
So the model predicted positive labels much better than negative labels.
Case Study in R
We have already learnt how to implement a Naïve Bayes classifier using Python. But the data scientists out there are eager to know how to implement the same using R. We will not let them down. We will build a model using the same data and also make a comparison which library is giving us better results.
First we read the data
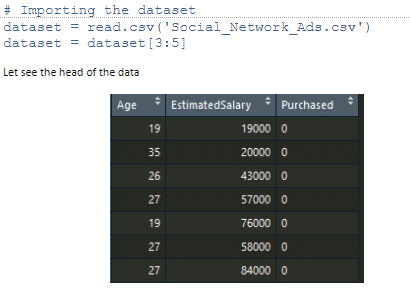
No we change the class column to factor

Now we will perform splitting and again the ratio will be same as we used in Python to justify the final accuracy of both the models. We will set a particular seed so we make sure that you get the same result as we do. That is what seeding does in case you do not know.

Now we will perform standardization

Now will fit the model and we will be implementing Naïve Bayes Classifier from e1071 package in R.

As we know, the model has been built and now we will predict on our test data.

We have made predictions and here we are to make a comparison by looking into the confusion matrix.
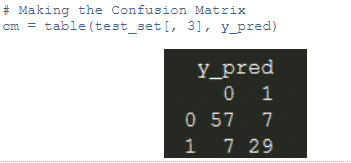
As we see, the miss classification of the classes is higher compared to the model built in Python. So Python wins here. But still it depends on the data and the model that we build.
Now let us make some visualization for both training and testing data to get a clear idea how the model actually worked.

Now we will visualize the predictions made for test data.

So this is where hands-on using Python and R ends. And hopefully, Naïve Bayes concept along with doubts also end here.
If the data contains text information as the features, then Naïve Bayes is the best option. Besides keeping drawbacks away, Naïve Bayes also performs well in data containing numeric and binary values but there are many other algorithms to give a try. Also before going for text analysis, it is advisable to go through text preprocessing concepts such as lemmatization, stemming, vectorization, POS tagging, stopword removal, etc which play a crucial role in text mining.
Great Learning's PG Program on Artificial Intelligence and Machine Learning help you upskill to build a career in this domain.