- What is OpenCV?
- What is Computer Vision?
- How does a computer read an image?
- OpenCV Tutorial Video
- OpenCV installation
- Read & Save Images
- Basic Operation On images
- OpenCV Resize Image
- OpenCV Image Rotation
- OpenCV Drawing Functions
- OpenCV Blob Detection
- Canny Edge Detection
- OpenCV Image Smoothing
- OpenCV Image Threshold
- OpenCV Contours
- OpenCV Mouse Event
- OpenCV Template Matching
- OpenCV Video Capture
- Face Detection Using OpenCV
- Car detection with OpenCV
- Face Recognition Using OpenCV
- Wrapping Up
- FAQs of OpenCV In Python
OpenCV is a widely acclaimed open-source library that provides an extensive suite of computer vision and image processing functions.
It offers a vast array of tools and techniques that empower developers to build cutting-edge applications in fields like robotics, augmented reality, facial recognition, object detection, and much more. With its powerful capabilities and user-friendly interface, OpenCV has become a go-to choice for developers worldwide.
In this tutorial, we will start from the basics and gradually delve into more advanced topics. We will cover everything you need to know to become proficient in OpenCV, regardless of your prior experience with computer vision.
Whether you're a beginner taking your first steps or an experienced developer looking to deepen your understanding, this guide will provide clear explanations, practical examples, and hands-on exercises to sharpen your skills.
What is OpenCV?
OpenCV is an open-source software library for computer vision and machine learning.
The OpenCV full form is Open Source Computer Vision Library. It was created to provide a shared infrastructure for applications for computer vision and to speed up the use of machine perception in consumer products. OpenCV, as a BSD-licensed software, makes it simple for companies to use and change the code.
Gary Bradsky invented OpenCV in 1999 and soon the first release came in 2000. This library is based on optimised C / C++ and supports Java and Python along with C++ through an interface.
The library has more than 2500 optimised algorithms, including an extensive collection of computer vision and machine learning algorithms, both classic and state-of-the-art.
Using OpenCV it becomes easy to do complex tasks such as identify and recognise faces, identify objects, classify human actions in videos, track camera movements, track moving objects, extract 3D object models, generate 3D point clouds from stereo cameras, stitch images together to generate an entire scene with a high resolution image and many more.
Let's get started!
Transform healthcare with AI. Apply now for Johns Hopkins AI in Healthcare Program and enhance patient outcomes with cutting-edge skills
What is Computer Vision?
The term Computer Vision (CV) is used and heard very often in artificial intelligence (AI) and deep learning (DL) applications. The term essentially means giving a computer the ability to see the world as we humans do.
- Computer Vision is a field of study which enables computers to replicate the human visual system. As already mentioned above, It’s a subset of artificial intelligence which collects information from digital images or videos and processes them to define the attributes.
- The entire process involves image acquiring, screening, analysing, identifying and extracting information. This extensive processing helps computers to understand any visual content and act on it accordingly.
- Computer vision projects translate digital visual content into explicit descriptions to gather multi-dimensional data. This data is then turned into a computer-readable language to aid the decision-making process.
- The main objective of this branch of artificial intelligence is to teach machines to collect information from pixels.
How does a computer read an image?
A digital image is an image composed of picture elements, also known as pixels, each with finite, discrete quantities of numeric representation for its intensity or grey level. So the computer sees an image as numerical values of these pixels and in order to recognise a certain image, it has to recognise the patterns and regularities in this numerical data.
Here is a hypothetical example of how pixels form an image. The darker pixels are represented by a number closer to the zero and lighter pixels are represented by numbers approaching one. All other colours are represented by the numbers between 0 and 1.
But usually, you will find that for any colour image, there are 3 primary channels – Red, green and blue and the value of each channel varies from 0-255.
In more simpler terms we can say that a digital image is actually formed by the combination of three basic colour channels Red, green, and blue whereas for a grayscale image we have only one channel whose values also vary from 0-255.
OpenCV Tutorial Video
OpenCV installation
There are many ways in which you can install OpenCV on your computer. Here are some:
Install using Anaconda
Anaconda is a conditional free and open-source distribution of the Python and R programming languages for scientific computing, that aims to simplify package management and deployment. You can download it from here and install it.
After successfully installing anaconda, just go to the anaconda prompt and use this command to install OpenCV:
conda install -c conda-forge opencv
After this command is successfully executed, OpenCV will be available on your computer.Now let us see some other ways to install OpenCV
For Windows
You can use pip to install OpenCV on windows. Pip is a de facto standard package-management system used to install and manage software packages written in Python and it usually comes in installed when you install Python.
If you do not have Python installed, I would suggest download it from here. Use this command in the command prompt to install OpenCV:
pip install opencv-python
After installing it,do check if it is installed successfully.For that just go to the command prompt and type ‘python’ and hit enter.You should see some message like this:
If this is not the message you see, I suggest reinstalling python into your system. Next type import cv2 and if there is no error then it is installed successfully.
For Mac
You can use homebrew to install OpenCV as it makes it really easy and you just have to use this command for installing:
brew install opencv
Now that you have installed the OpenCV onto your system, let's see how it works.
Read & Save Images
Now for OpenCV to work on any image, it must be able to read it. Here we will see how to read a file and save it after we are done with it. Let’s see how to do it:
Imread function in OpenCV
We use the imread function to read images. Here is the syntax of this function:
cv2.imread(path, flag)
The path parameter takes a string representing the path of the image to be read.The file should be in the working directory or we must give the full path to the image.
The other parameter is the flag which is used to specify how our image should be read. Here are possible values that it takes and their working:
cv2.IMREAD_COLOR: It specifies to convert the image to the 3 channel BGR
colour image. Any transparency of image will be neglected. It is the default
flag. Alternatively, we can passinteger value 1 for this flag.
cv2.IMREAD_GRAYSCALE: It specifies to convert an image to thesingle channel
grayscale image. Alternatively, we can pass integer value 0 for this flag.
cv2.IMREAD_UNCHANGED: It specifies to load an image as such including alpha
channel.Alternatively, we can pass integer value -1 for this flag.
Usually the method imread() returns an image that is loaded from the specified file but in case the image cannot be read because of unsupported file format, missing file, unsupported or invalid format, it just returns a matrix. Here is a example in which we read an image from my storage.
#importing the opencv module
import cv2
# using imread('path') and 1 denotes read as color image
img = cv2.imread('dog.jpg',1)
#This is using for display the image
cv2.imshow('image',img)
cv2.waitKey() # This is necessary to be required so that the image doesn't close immediately.
#It will run continuously until the key press.
cv2.destroyAllWindows()
Imwrite function in OpenCV
We can use OpenCV’s imwrite() function to save an image in a storage device and the file extension defines the image format as shown in the example below. The syntax is the following:
cv2.imwrite(filename, image)
Parameters:
filename: A string representing the file name. The filename must include image format.
image: It is the image that is to be saved.
Here is an example in which we use this function:
import cv2
# read image
img = cv2.imread(r'C:UsersMirzadog.jpeg', 1)
# save image
status = cv2.imwrite(r'C:UsersMirzadog.jpeg',img)
print("Image written sucess? : ", status)
If the file is successfully written then this function returns True and thus it is important to store the outcome of this function.In the example above,we have done the same and used the ‘status’ variable to know if the file is written successfully.
Basic Operation On images
In this section,we are going to discuss some of the basic operations that we can do on the images once we have successfully read them.The operations we are going to do here ae:
- Access pixel values and modify them
- Access image properties
- Set a Region of Interest (ROI)
- Split and merge image channels
Access pixel values and modify them
So there are basically two ways to access a pixel value in an Image and modify them. First let us see how we can access a particular pixel value of an image.
import numpy as np
import cv2 as cv
img = cv.imread(r'C:UsersMirzadog.jpeg')
px = img[100,100]
print( px )
Output:
[157 166 200]
Now as you can see we got a list containing 3 values.As we know OpenCV stores the color image as BGR color image,so the first value in the list is the value of the blue channel of this particular pixel, and the rest are values for green and red channels.
We can also access only one of the channels as shown below:
# accessing only blue pixel
blue = img[100,100,0]
print( blue )
Output:
157
To modify the values, we just need to access the pixel and then overwrite it with a value as shown below:
img[100,100] = [255,255,255]
print( img[100,100] )
Output:
[255 255 255]
This method to access and modify the pixel values is slow so you should make use of NumPy library as it is optimized for fast array calculations. For accessing individual pixel values, the Numpy array methods, array.item() and array.itemset() are considered better as they always return a scalar.
However, if you want to access all the B,G,R values, you will need to call array.item() separately for each value as shown below:
# accessing RED value
img.item(10,10,2)
>>59
# modifying RED value
img.itemset((10,10,2),100)
img.item(10,10,2)
>>100
Access Image properties
What do we mean by image properties here? Often it is important to know the size(total number of pixels in the image), number of rows, columns, and channels.We can access the later three by using the shape() method as shown below:
print( img.shape )
>>(342, 548, 3)
print( img.size )
>>562248
So here we have three numbers in the returned tuple, these are number of rows, number of columns and number of channels respectively. Incase an image is grayscale, the tuple returned contains only the number of rows and columns.
Often a large number of errors in OpenCV-Python code are caused by invalid datatype so img.dtype which returns the image datatype is very important while debugging.
Here is an example:
print( img.dtype )
>>uint8
Image ROI(Region of interest)
Often you may come across some images where you are only interested in a specific region. Say you want to detect eyes in an image, will you search the entire image, possibly not as that may not fetch accurate results. But we know that eyes are a part of face, so it is better to detect a face first ,thus here the face is our ROI. You may want to have a look at the article Face detection using Viola-Jones algorithm where we detect the faces and then find eyes in the area we found faces.
Splitting and Merging Image Channels
We can also split the channels from an image and then work on each channel separately. Or sometimes you may need to merge them back together, here is how we do it:
But this method is painfully slow, so we can also use the Numpy to do the same, here is how:
b,g,r = cv.split(img)
img = cv.merge((b,g,r))
b = img[:,:,0]
g = img[:,:,1]
r = img[:,:,2]
Now suppose you want to just set all the values in the red channel to zero, here is how to do that:
#sets all values in red channel as zero
img[:,:,2] = 0
OpenCV Resize Image
Usually when working on images, we often need to resize the images according to certain requirements.
Mostly you will do such operation in Machine learning and deep learning as it reduces the time of training of a neural network. As the number of pixels in an image increases, the more is the number of input nodes that in turn increases the complexity of the model. We use an inbuilt resize() method to resize an image.
Syntax:
cv2.resize(s, size,fx,fy,interpolation)
Parameters:
s - input image (required).
size - desired size for the output image after resizing (required)
fx - Scale factor along the horizontal axis.(optional)
fy - Scale factor along the vertical axis.
Interpolation(optional) - This flag uses following methods:
Interpolation(optional) - This flag uses following methods:
INTER_NEAREST – a nearest-neighbor interpolation
INTER_LINEAR – a bilinear interpolation (used by default)
INTER_AREA – resampling using pixel area relation. It may be a preferred method for image decimation, as it gives moire’-free results. But when the image is zoomed, it is similar to the INTER_NEAREST method.
INTER_CUBIC – a bicubic interpolation over 4×4 pixel neighborhood
INTER_LANCZOS4 – a Lanczos interpolation over 8×8 pixel neighborhood
Here is an example of how we can use this method:
import cv2
import numpy as np
#importing the opencv module
import cv2
# using imread('path') and 1 denotes read as color image
img = cv2.imread('dog.jpg',1)
print(img.shape)
img_resized=cv2.resize(img, (780, 540),
interpolation = cv2.INTER_NEAREST)
cv2.imshow("Resized",img_resized)
cv2.waitKey(0)
cv2.destroyAllWindows()
Output:


OpenCV Image Rotation
We may need to rotate an image in some of the cases and we can do it easily by using OpenCV .We use cv2.rotate() method to rotate a 2D array in multiples of 90 degrees. Here is the syntax:
cv2.rotate( src, rotateCode[, dst] )
Parameters:
src: It is the image to be rotated.
rotateCode: It is an enum to specify how to rotate the array.Here are some of the possible values :
cv2.cv2.ROTATE_90_CLOCKWISE
cv2.ROTATE_180
cv2.ROTATE_90_COUNTERCLOCKWISE
Here is an example using this function.
import cv2
import numpy as np
#importing the opencv module
import cv2
# using imread('path') and 1 denotes read as color image
img = cv2.imread('dog.jpg',1)
print(img.shape)
image = cv2.rotate(img, cv2.ROTATE_90_COUNTERCLOCKWISE)
cv2.imshow("Rotated",image)
cv2.waitKey()
cv2.destroyAllWindows()
Output:

Now what if we want to rotate the image by a certain angle.We can use another method for that.First calculate the affine matrix that does the affine transformation (linear mapping of pixels) by using the getRotationMatrix2D method,next we warp the input image with the affine matrix using warpAffine method.
Here is the syntax of these functions:
cv2.getRotationMatrix2D(center, angle, scale)
cv2.warpAffine(Img, M, (W, H))
center: center of the image (the point about which rotation has to happen)
angle: angle by which image has to be rotated in the anti-clockwise direction.
scale: scales the image by the value provided,1.0 means the shape is preserved.
H:height of image
W: width of the image.
M: affine matrix returned by cv2.getRotationMatrix2D
Img: image to be rotated.
Here is an example in which we rotate an image by various angles.
import cv2
import numpy as np
#importing the opencv module
import cv2
# using imread('path') and 1 denotes read as color image
img = cv2.imread('dog.jpg',1)
# get image height, width
(h, w) = img.shape[:2]
# calculate the center of the image
center = (w / 2, h / 2)
scale = 1.0
# Perform the counter clockwise rotation holding at the center
# 45 degrees
M = cv2.getRotationMatrix2D(center, 45, scale)
print(M)
rotated45 = cv2.warpAffine(img, M, (h, w))
# 110 degrees
M = cv2.getRotationMatrix2D(center,110, scale)
rotated110 = cv2.warpAffine(img, M, (w, h))
# 150 degrees
M = cv2.getRotationMatrix2D(center, 150, scale)
rotated150 = cv2.warpAffine(img, M, (h, w))
cv2.imshow('Original Image',img)
cv2.waitKey(0) # waits until a key is pressed
cv2.destroyAllWindows() # destroys the window showing image
cv2.imshow('Image rotated by 45 degrees',rotated45)
cv2.waitKey(0) # waits until a key is pressed
cv2.destroyAllWindows() # destroys the window showing image
cv2.imshow('Image rotated by 110 degrees',rotated110)
cv2.waitKey(0) # waits until a key is pressed
cv2.destroyAllWindows() # destroys the window showing image
cv2.imshow('Image rotated by 150 degrees',rotated150)
cv2.waitKey(0) # waits until a key is pressed
cv2.destroyAllWindows() # destroys the window showing image
Output



OpenCV Drawing Functions
We may require to draw certain shapes on an image such as circle, rectangle, ellipse, polylines, convex, etc. and we can easily do this using OpenCV. It is often used when we want to highlight any object in the input image for example in case of face detection, we might want to highlight the face with a rectangle.
Here we will learn about the drawing functions such as circle, rectangle, lines, polylines and also see how to write text on an image.
Drawing circle:
We use the method to circle to draw a circle in an image. Here is the syntax and parameters:
cv2.circle(image, center_coordinates, radius, color, thickness)
Parameters:
image: It is the input image on which a circle is to be drawn.
center_coordinates: It is the center coordinates of the circle. The coordinates are represented as tuples of two values i.e. (X coordinate value, Y coordinate value).
radius: It is the radius of the circle.
color: It is the color of the border line of the circle to be drawn. We can pass a tuple For in BGR, eg: (255, 0, 0) for blue color.
thickness: It is the thickness of the circle border line in px. Thickness of -1 px will fill the circle shape by the specified color.
Return Value: It returns an image.
Here are the few of the examples:
import numpy as np
import cv2
img = cv2.imread(r'C:UsersMirzadog.jpeg', 1)
cv2.circle(img,(80,80), 55, (255,0,0), -1)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Drawing Rectangle
In a similar we can draw a rectangle. Here is the the syntax for this function:
cv2.rectangle(image, start_point, end_point, color, thickness)
Parameters:
image: It is the input image on which rectangle is to be drawn.
start_point: It is the starting coordinates(top left vertex) of the rectangle. The coordinates are represented as tuples of two values i.e. (X coordinate value, Y coordinate value).
end_point: It is the ending coordinates(bottom right) of the rectangle. The coordinates are represented as tuples of two values i.e. (X coordinate value, Y coordinate value).
color: It is the color of the border line of the rectangle to be drawn. We can pass a tuple For in BGR, eg: (255, 0, 0) for blue color.
thickness: It is the thickness of the rectangle border line in px. Thickness of -1 px will fill the rectangle shape by the specified color.
Return Value: It returns an image.
Here is an example of this function:
import numpy as np
import cv2
img = cv2.imread(r'C:UsersMirzadog.jpeg', 1)
cv2.rectangle(img,(15,25),(200,150),(0,255,255),15)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Drawing Lines
Here is the syntax of the line method using which we can make lines on an image.
cv2.line(image, start_point, end_point, color, thickness)
Parameters:
image: It is the input image on which line is to be drawn.
start_point: It is the starting coordinates of the line. The coordinates are represented as tuples of two values i.e. (X coordinate value, Y coordinate value).
end_point: It is the ending coordinates of the line. The coordinates are represented as tuples of two values i.e. (X coordinate value, Y coordinate value).
color: It is the color of the line to be drawn. We can pass a tuple For in BGR, eg: (255, 0, 0) for blue color.
thickness: It is the thickness of the line in px.
Return Value: It returns an image.
Here is an example:
import numpy as np
import cv2
img = cv2.imread(r'C:UsersMirzadog.jpeg', 1)
#defining points for polylines
pts = np.array([[100,50],[200,300],[700,200],[500,100]], np.int32)
# pts = pts.reshape((-1,1,2))
cv2.polylines(img, [pts], True, (0,255,255), 3)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Drawing Polylines
We can draw the polylines using the polylines() method on the image. And these can be used to draw polygonal curves on the image. The syntax is given below:
cv2.polyLine(image, arr, is_closed, color, thickness)
Parameters:
img - It represents an image.
arr -represents the coordinates of vertices into an array of shape nx1x2 where n is number of vertices and it should be of type int32.
is_Closed - It is a flag that indicates whether the drawn polylines are closed or not.
color - Color of polylines. We can pass a tuple For in BGR, eg: (255, 0, 0) for blue color.
thickness - It represents the Thickness of the polyline's edges.
Here is an example:
import numpy as np
import cv2
img = cv2.imread(r'C:UsersMirzadog.jpeg', 1)
#defining points for polylines
pts = np.array([[100,50],[200,300],[700,200],[500,100]], np.int32)
# pts = pts.reshape((-1,1,2))
cv2.polylines(img, [pts], True, (0,255,255), 3)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Write text on an image
We can write text on the image by using the putText() method. The syntax is given below.
cv2.putText(img, text, org, font,fontScale color)
Parameters:
img: It represents the input image on which we have to write text
text: The text which we want to write on the image.
org: It denotes the Bottom-left corner of the text string on the image. So it is used to set the location of text on the image
font: the font of text. Here is the list of supported fonts.
fontScale: The scale of the font by which you can increase or decrease size
color: Represents the color. We can pass a tuple For in BGR, eg: (255, 0, 0) for blue color.
Here is an example:
import numpy as np
import cv2
font = cv2.FONT_HERSHEY_SIMPLEX
mg = cv2.imread(r'C:UsersMirzadog.jpeg', 1)
cv2.putText(img,'Dog',(10,500), font, 1,(255,255,255),2)
#Display the image
cv2.imshow("image",img)
cv2.waitKey(0)
OpenCV Blob Detection
Blob stands for Binary Large Object where the term "Large" focuses on the object of a specific size, and that other "small" binary objects are usually considered as noise.
In simpler terms, a Blob is a group of connected pixels which we can find in an image and all of these pixels have some common property. In the image below, the coloured connected regions are blobs, and the goal of blob detection is to identify and mark these regions( marked by red circle).
Using OpenCV’s SimpleBlobDetector method, we can easily find blobs in our images.But how does this method work?Let us see this in detail:
- Thresholding :First the algorithm converts the source images to several binary images by applying thresholding with various thresholds.We define two threshold values,viz- minThreshold (inclusive) to maxThreshold (exclusive) and start from threshold value equal to minThreshold.Then it is incremented by thresholdStep until we reach maxThreshold,so the first threshold is minThreshold, the second is minThreshold + thresholdStep and so on.
- Grouping : In each binary image, we have a curve joining all the continuous points (along the boundary), having the same color or intensity.
- Merging : The centers of the binary blobs in the binary images are computed, and blobs located closer than minDistBetweenBlobs(minimum distance between two blobs) are merged.
- Center & Radius Calculation : The centers and radii of the new merged blobs are computed and returned.
This class can perform several filtrations of returned blobs by setting filterBy* to True to turn on corresponding filtration. Available filtrations are as following:
- By color. We define a parameter blobColor to filter the blobs of colours we are interested in. Set blobColor equal to zero to extract dark blobs and to extract light blobs,set it to 255. This filter compares the intensity of a binary image at the center of a blob to blobColor and filters accordingly.
- By area. By using this filter the extracted blobs have an area between minArea (inclusive) and maxArea (exclusive).
- By circularity. By using this filter the extracted blobs have circularity between minCircularity (inclusive) and maxCircularity (exclusive).
- By ratio of the minimum inertia to maximum inertia.By using this filter the extracted blobs have this ratio between minInertiaRatio (inclusive) and maxInertiaRatio (exclusive).
- By convexity.By using this filter the extracted blobs have convexity (area / area of blob convex hull) between minConvexity (inclusive) and maxConvexity (exclusive).
By default, the values of these parameters are tuned to extract dark circular blobs.
Here is an example of how to use simple SimpleBlobDetector()
import cv2
import numpy as np;
img = cv2.imread(r"pic1.jpeg", cv2.IMREAD_GRAYSCALE)
# Set up the detector with default parameters.
detector = cv2.SimpleBlobDetector()
# Detecting blobs.
keypoints = detector.detect(img)
# Draw detected blobs as red circles.
# cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS ensures the size of the circle corresponds to the size of blob
im_with_keypoints = cv2.drawKeypoints(img, keypoints, np.array([]), (0, 0, 255),
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# Show keypoints
cv2.imshow("Keypoints", im_with_keypoints)
cv2.waitKey(0)
Now here is an example in which we use the filters mentioned above:
import cv2
import numpy as np;
# Read image
im = cv2.imread("blob.jpg")
# Setup SimpleBlobDetector parameters.
params = cv2.SimpleBlobDetector_Params()
# Change thresholds
params.minThreshold = 10
params.maxThreshold = 200
# Filter by Area.
params.filterByArea = True
params.minArea = 1500
# Filter by Circularity
params.filterByCircularity = True
params.minCircularity = 0.1
# Filter by Convexity
params.filterByConvexity = True
params.minConvexity = 0.87
# Filter by Inertia
params.filterByInertia = True
params.minInertiaRatio = 0.01
# Create a detector with the parameters
detector = cv2.SimpleBlobDetector(params)
# Detect blobs.
keypoints = detector.detect(im)
# Draw detected blobs as red circles.
# cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS ensures
# the size of the circle corresponds to the size of blob
im_with_keypoints = cv2.drawKeypoints(im, keypoints, np.array([]), (0,0,255), cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# Show blobs
cv2.imshow("Keypoints", im_with_keypoints)
cv2.waitKey(0)
Canny Edge Detection
Edge detection is an image processing technique used for finding the boundaries of objects within images. Here we will use a popular edge detection algorithm Canny Edge Detection, developed by John F. Canny. In OpenCV, we have Canny() method to implement this algorithm. Here is the syntax:
edges = cv2.Canny(img, minVal, maxVal, apertureSize, L2gradient)
Parameters -
img: input image whose edges we want to detect.
minVal: Minimum intensity gradient (required)
maxVal: Maximum intensity gradient (required)
L2gradient: is a flag with default value =False, indicating the default L1 norm is enough to calculate the image gradient magnitude, if its is set as True a more accurate L2 norm is used to calculate the image gradient magnitude but it is computationally more expensive.
aperture: aperture size for the Sobel operator.
As we can see we have two threshold values, minVal and maxVal. Any edges with intensity gradient more than maxVal are sure to be edges.also those edges with intensity gradient less than minVal are sure to be non-edges and are discarded.
The edges which lie between these two thresholds are classified edges or non-edges based on their connectivity with the ‘sure edges’. If they are connected to "sure-edge" pixels, they are considered to be part of edges. Otherwise, they are also discarded as non-edges.
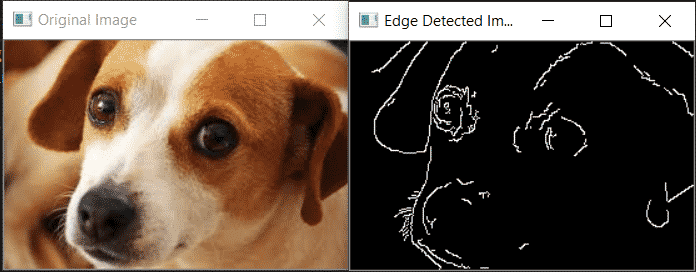
Here is an example:
import cv2
img = cv2.imread('dog.jpg')
edges = cv2.Canny(img,200,300,True)
cv2.imshow("Edge Detected Image", edges)
cv2.imshow("Original Image", img)
cv2.waitKey(0) # waits until a key is pressed
cv2.destroyAllWindows() # destroys the window showing image
Now we can also do this in real-time, here is how:
# import libraries of python OpenCV
import cv2
# import Numpy by alias name np
import numpy as np
# capture frames from a camera
cap = cv2.VideoCapture(0)
# loop runs if capturing has been initialized
while (1):
# reads frames from a camera
ret, frame = cap.read()
# Display an original image
cv2.imshow('Original', frame)
# discovers edges in the input image image and
# marks them in the output map edges
edges = cv2.Canny(frame, 100, 200,True)
# Display edges in a frame
cv2.imshow('Edges', edges)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Close the window
cap.release()
# De-allocate any associated memory usage
cv2.destroyAllWindows()
OpenCV Image Smoothing
Image smoothing is an image processing technique used for removing the noise in an image.Blurring(smoothing) removes low-intensity edges and is also beneficial in hiding the details; for example, blurring is required in many cases, such as hiding any confidential information in an image.OpenCV provides mainly the following type of blurring techniques.
Here are a few of the methods that we are going to use for smoothing an image:
- OpenCV averaging
- OpenCV median Blur
- OpenCV Gaussian Blur
- OpenCV Bilateral Filter
OpenCV averaging
In this technique, we normalize the image with a box filter. It calculates the average of all the pixels which are under the kernel area(box filter) and replaces the value of the pixel at the center of the box filter with the calculated average. OpenCV provides the cv2.blur() to perform this operation. The syntax of cv2.blur() function is as follows.
cv2.blur(src, ksize,anchor, borderType)
Parameters:
src: It is the image which is to be blurred.
ksize: A tuple representing the blurring kernel size.
anchor: It is a variable of type integer representing anchor point and it’s default value Point is (-1, -1) which means that the anchor is at the kernel center.
borderType: It represents the type of border to be used for the output.
Here is an example:
import cv2
img = cv2.imread('dog.jpg')
cv2.imshow('Original Image',img)
cv2.imshow('cv2.blur output', cv2.blur(img, (3,3)))
cv2.waitKey(0)
cv2.destroyAllWindows()

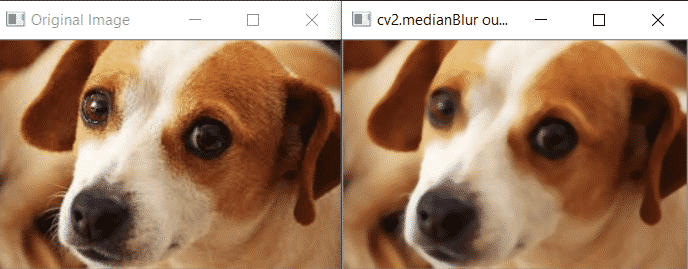
OpenCV median Blur
In this technique, the median of all the pixels under the kernel window is computed and the central pixel is replaced with this median value. It has one advantage over the Gaussian and box filters, that being the filtered value for the central element is always replaced by some pixel value in the image which is not the case in case of either Gaussian or box filters. OpenCV provides a function medianBlur() that can be used to easily implement this kind of smoothing. Here is the syntax:
cv2.medianBlur(src, dst, ksize)
Parameters:
src- It represents the source (input image).
dst - It represents the destination (output image).
ksize - It represents the size of the kernel.
Consider the following example:
import cv2
img = cv2.imread('dog.jpg')
cv2.imshow('Original Image',img)
cv2.imshow('cv2.medianBlur output', cv2.medianBlur(img,5))
cv2.waitKey(0)
cv2.destroyAllWindows()
OpenCV Gaussian Blur
In this technique, a Gaussian function(kernel) instead of a box filter to blur the image. The width and height of the kernel needs to be specified and they should be positive and odd. We also have to specify the standard deviation in the directions X and Y and are represented by sigmaX and sigmaY respectively. If both sigmaX and sigmaY are given as zeros, they are calculated from the kernel size and if we only specify sigmaX, sigmaY is set to the same value. Gaussian blurring is highly effective when removing Gaussian noise from an image. In OpenCV we have a function GaussianBlur() to implement this technique easily. Here is the syntax:
GaussianBlur(src, dst, ksize, sigmaX,sigmaY)
Parameters:
src − Input image which is to be blurred
dst − output image of the same size and type as src.
ksize − A Size object representing the size of the kernel.
sigmaX − A variable of the type double representing the Gaussian kernel standard deviation in X direction.
sigmaY − A variable of the type double representing the Gaussian kernel standard deviation in Y direction.
Here is an example:
import cv2
img = cv2.imread('dog.jpg')
cv2.imshow('Original Image',img)
cv2.imshow('cv2.GaussianBlur output', cv2.GaussianBlur(img, (5, 5), cv2.BORDER_DEFAULT))
cv2.waitKey(0)
cv2.destroyAllWindows()
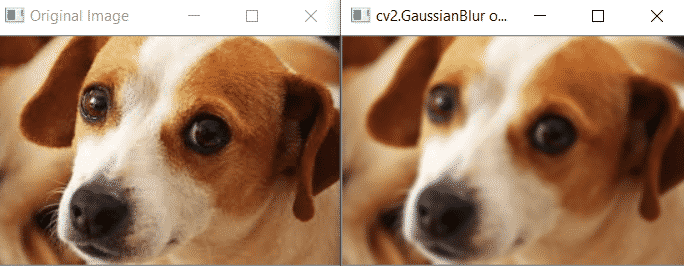
OpenCV Bilateral Filter
This method of noise removal is highly effective but is slower compared to other filters. The Gaussian filter blurred the edges too and that is not what we want, but this filter makes sure that only those pixels with similar intensities to the central pixel are considered for blurring, thus preserving the edges since pixels at edges will have large intensity variation. In OpenCV we have cv.bilateralFilter() method that can implement this filter. Here is the syntax:
cv2.bilateralFilter(src, dst, d, sigmaColor,sigmaSpace, borderType)
Parameters:
src Source 8-bit or floating-point, 1-channel or 3-channel image.
dst Destination image of the same size and type as src .
d Diameter of each pixel neighborhood that is used during filtering. If it is non-positive, it is computed from sigmaSpace.
sigmaColor Filter sigma in the color space. A larger value of the parameter means that farther colors within the pixel neighborhood (see sigmaSpace) will be mixed together, resulting in larger areas of semi-equal color.
sigmaSpace Filter sigma in the coordinate space. A larger value of the parameter means that farther pixels will influence each other as long as their colors are close enough (see sigmaColor ). When d>0, it specifies the neighborhood size regardless of sigmaSpace. Otherwise, d is proportional to sigmaSpace.
borderType border mode used to extrapolate pixels outside of the image, see the BorderTypes available here.
Here is an example:
import cv2
img = cv2.imread('dog.jpg')
cv2.imshow('Original Image',img)
cv2.imshow('bilateral Image', cv2.bilateralFilter(img,9,75,75))
cv2.waitKey(0)
cv2.destroyAllWindows()

OpenCV Image Threshold
Thresholding is a popular segmentation technique, used for separating an object considered as a foreground from its background.In this technique we assign pixel values in relation to the threshold value provided.This technique of thresholding is done on grayscale images,so initially, the image has to be converted in grayscale color space.Here we will discuss two different approaches taken when performing thresholding on an image:
- Simple Thresholding
- Adaptive Thresholding
Simple Thresholding:
In this basic Thresholding technique, for every pixel, the same threshold value is applied. If the pixel value is smaller than the threshold, it is set to a certain value(usually zero) , otherwise, it is set to another value(usually maximum value) .There are various variations of this technique as shown below.
In OpenCV, we use cv2.threshold function to implement it. Here is the syntax:
cv2.threshold(source, thresholdValue, maxVal, thresholdingTechnique)
Parameters:
-> source: Input Image array (must be in Grayscale).
-> thresholdValue: Value of Threshold below and above which pixel values will change accordingly.
-> maxVal: Maximum value that can be assigned to a pixel.
-> thresholdingTechnique: The type of thresholding to be applied.Here are various types of thresholding we can use
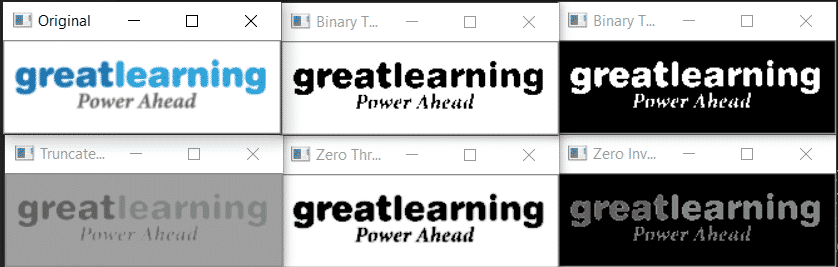
cv2.THRESH_BINARY: If the pixel intensity is greater than the threshold, the pixel value is set to 255(white), else it is set to 0 (black).
cv2.THRESH_BINARY_INV: Inverted or Opposite case of cv2.THRESH_BINARY.If the pixel intensity is greater than the threshold, the pixel value is set to 0(black), else it is set to 255 (white).
cv.THRESH_TRUNC: If the pixel intensity is greater than the threshold,the pixel values are set to be the same as the threshold. All other values remain the same.
cv.THRESH_TOZERO: Pixel intensity is set to 0, for all the pixels intensity, less than the threshold value.All other pixel values remain same
cv.THRESH_TOZERO_INV: Inverted or Opposite case of cv2.THRESH_TOZERO.
Here is an example:
import cv2
import numpy as np
# path to input image is specified and
# image is loaded with imread command
image = cv2.imread('gl.png')
# to convert the image in grayscale
img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
threshold=160
ret, thresh1 = cv2.threshold(img, threshold, 255, cv2.THRESH_BINARY)
ret, thresh2 = cv2.threshold(img, threshold, 255, cv2.THRESH_BINARY_INV)
ret, thresh3 = cv2.threshold(img, threshold, 255, cv2.THRESH_TRUNC)
ret, thresh4 = cv2.threshold(img, threshold, 255, cv2.THRESH_TOZERO)
ret, thresh5 = cv2.threshold(img, threshold, 255, cv2.THRESH_TOZERO_INV)
# the window showing output images
# with the corresponding thresholding
# techniques applied to the input images
cv2.imshow('Original',image)
cv2.imshow('Binary Threshold', thresh1)
cv2.imshow('Binary Threshold Inverted', thresh2)
cv2.imshow('Truncated Threshold', thresh3)
cv2.imshow('Zero Threshold', thresh4)
cv2.imshow('Zero Inverted', thresh5)
# De-allocate any associated memory usage
cv2.waitKey(0)
cv2.destroyAllWindows()
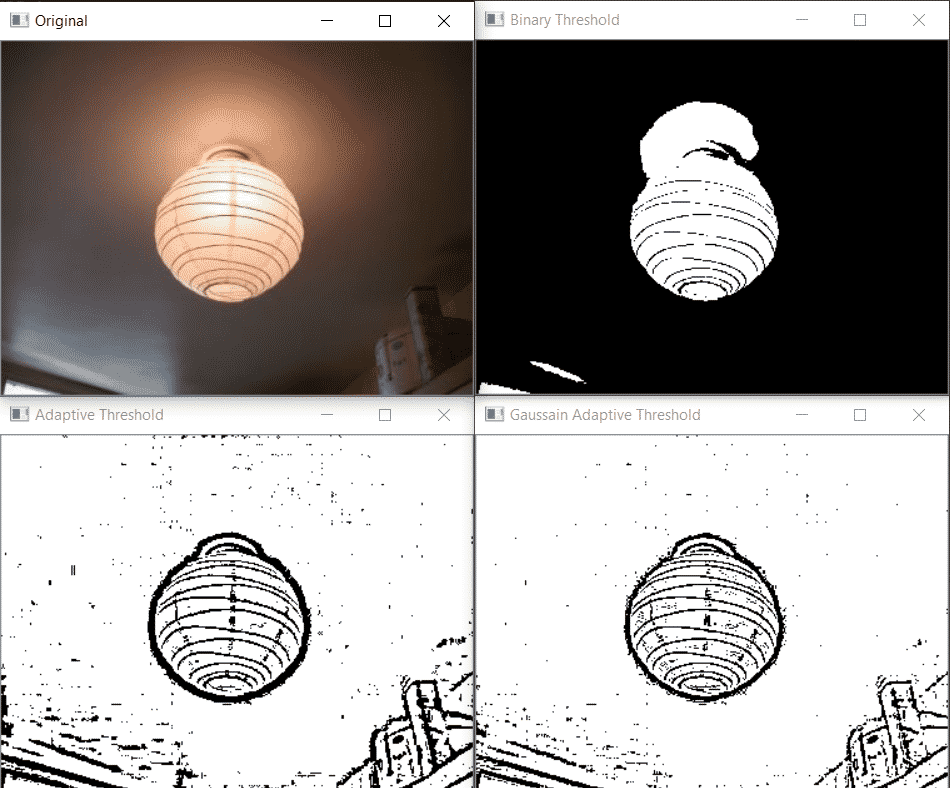
Adaptive Thresholding:
In simple thresholding, the threshold value was global which means it was same for all the pixels in the image. But this may not be the best approach for thresholding as the different image sections can have different lightings. Thus we need Adaptive thresholding, which is the method where the threshold value is calculated for smaller regions and therefore, there will be different threshold values for different regions. In OpenCV we have adaptiveThreshold() function to implement this type of thresholding. Here is the syntax of this function:
adaptiveThreshold(src, dst, maxValue, adaptiveMethod, thresholdType, blockSize, C)
This method accepts the following parameters −
src − An object of the class Mat representing the source (input) image.
dst − An object of the class Mat representing the destination (output) image.
maxValue − A variable of double type representing the value that is to be given if pixel value is more than the threshold value.
adaptiveMethod − A variable of integer the type representing the adaptive method to be used. This will be either of the following two values:
cv.ADAPTIVE_THRESH_MEAN_C: The threshold value is the mean of the neighbourhood area minus the constant C.
cv.ADAPTIVE_THRESH_GAUSSIAN_C: The threshold value is a gaussian-weighted sum of the neighbourhood values minus the constant C.
thresholdType − A variable of integer type representing the type of threshold to be used.
blockSize − A variable of the integer type representing size of the pixelneighborhood used to calculate the threshold value.
C − A variable of double type representing the constant used in the both methods (subtracted from the mean or weighted mean).
Here is an example:
import cv2
import numpy as np
# path to input image is specified and
# image is loaded with imread command
image = cv2.imread('lamp.jpg')
# to convert the image in grayscale
img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
ret, th1 = cv2.threshold(img,160, 255, cv2.THRESH_BINARY)
th2 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY,11,2)
th3 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY,11,2)
cv2.imshow('Original',image)
cv2.imshow('Binary Threshold', th1)
cv2.imshow('Adaptive Threshold', th2)
cv2.imshow('Gaussain Adaptive Threshold', th3)
# De-allocate any associated memory usage
cv2.waitKey(0)
cv2.destroyAllWindows()
OpenCV Contours
So what are contours? A Contour is a curve joining all the continuous points having the same color or intensity (along the boundary).So the counters are useful especially when we want to find out a shape of some object or incase of object detection and recognition.
Finding contours is like finding white object from black background, so remember, the object to be found should be white and background should be black. Thus, for better accuracy, we should use binary images and before finding contours, apply thresholding as we discussed in the last section.
In OpenCV, we use two functions, one to find contours and other to draw contours. We use findContours() function to find contours and drawCounter() to draw one. Here is the syntax of these functions.
image, contours, hierarchy=cv.findContours(img, mode, method,contours, hierarchy,offset)
This function returns three objects:
Img:The input image in which we have to find contours
Contours: It contains detected contours and contour is stored as a vector of points
Hierarchy:Optional output vector, containing information about the image topology. It has as many elements as the number of contours. For each i-th contour contours[i], the elements hierarchy[i][0] , hierarchy[i][1] , hierarchy[i][2] , and hierarchy[i][3] are set to 0-based indices in contours of the next and previous contours at the same hierarchical level, the first child contour and the parent contour, respectively. If for the contour i there are no next, previous, parent, or nested contours, the corresponding elements of hierarchy[i] will be negative.
Parameters of this function:
mode: Contour retrieval mode, see RetrievalModes
method:Contour approximation method, see ContourApproximationModes
offset : Optional offset by which every contour point is shifted. This is useful if the contours are extracted from the image ROI and then they should be analyzed in the whole image context.
Here is the syntax of drawCounter():
cv.drawContours(image, contours, contourIdx, color, thickness, lineType, hierarchy, maxLevel, offset)
Parameters
Image: Input image.
contours: All the input contours. Each contour is stored as a point vector.
contourIdx: Parameter indicating a contour to draw. If it is negative, all the contours are drawn.
color: Color of the contours.
thickness: Thickness of lines the contours are drawn with. If it is negative (for example, thickness=FILLED ), the contour interiors are drawn.
lineType: Line connectivity. See LineTypes
hierarchy: Optional information about hierarchy. It is only needed if you want to draw only some of the contours (see maxLevel ).
maxLevel: Maximal level for drawn contours. If it is 0, only the specified contour is drawn. If it is 1, the function draws the contour(s) and all the nested contours. If it is 2, the function draws the contours, all the nested contours, all the nested-to-nested contours, and so on. This parameter is only taken into account when there is hierarchy available.
offset: Optional contour shift parameter. Shift all the drawn contours by the specified offset=(dx,dy).
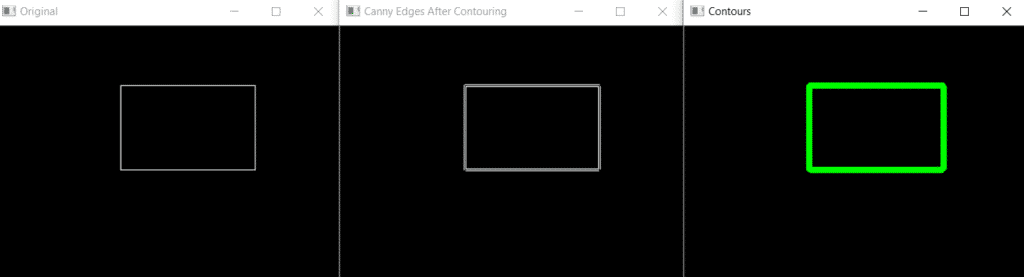
Here is an example using these functions:
import cv2
import numpy as np
# Let's load a simple image with 3 black squares
image = cv2.imread('contor.png',1)
# Find Canny edges
edged = cv2.Canny(image, 30, 200)
cv2.waitKey(0)
# Finding Contours
# Use a copy of the image e.g. edged.copy()
# since findContours alters the image
contours, hierarchy = cv2.findContours(edged,
cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
cv2.imshow('Original', image)
cv2.imshow('Canny Edges After Contouring', edged)
cv2.drawContours(image, contours, -1, (0, 255, 0), 3)
cv2.imshow('Contours', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
OpenCV Mouse Event
OpenCV also provides the functionality to control and manage different types of mouse events and gives us the flexibility to manage them. As we know there can be different types of mouse events such as double_click, left button click, right button click, etc.
For managing these events, we need to design callback functions for each of these mouse click events while the window or frame is opened by OpenCV.The callback function gives us flexibility to implement what type of functionality you want with a particular mouse click event.
Mouse as a Paint Brush
Using OpenCV in python , we have an option to use the mouse as a paint brush or a drawing tool. Whenever any mouse event occurs on the window screen, it gives us the coordinates (x,y) for that particular mouse event. Now that we have the coordinates of the point we are interested in, we can draw anything we desire, be it a circle or a rectangle or a simple line. First let us see the available mouse events, to get the list of all these events, run the code below:
import cv2
mouse_events = [j for j in dir(cv2) if 'EVENT' in j]
print(mouse_events)
Output:
['EVENT_FLAG_ALTKEY', 'EVENT_FLAG_CTRLKEY', 'EVENT_FLAG_LBUTTON', 'EVENT_FLAG_MBUTTON', 'EVENT_FLAG_RBUTTON', 'EVENT_FLAG_SHIFTKEY', 'EVENT_LBUTTONDBLCLK', 'EVENT_LBUTTONDOWN', 'EVENT_LBUTTONUP', 'EVENT_MBUTTONDBLCLK', 'EVENT_MBUTTONDOWN', 'EVENT_MBUTTONUP', 'EVENT_MOUSEHWHEEL', 'EVENT_MOUSEMOVE', 'EVENT_MOUSEWHEEL', 'EVENT_RBUTTONDBLCLK', 'EVENT_RBUTTONDOWN', 'EVENT_RBUTTONUP']
Draw Circle
To draw anything on the window screen, we first need to create a mouse callback function by using the cv2.setMouseCallback() function. It has a specific format that remains the same everywhere. Our mouse callback function is facilitated by drawing a circle using double-click. Here is the code:
import cv2
import numpy as np
# Creating mouse callback function
def draw_circle(event,x,y,flags,param):
if(event == cv2.EVENT_LBUTTONDBLCLK):
cv2.circle(img,(x,y),50,(123,125, 200),-1)
# Creating a black image, a window and bind the function to window
img = np.zeros((512,512,3), np.uint8)
cv2.namedWindow('image')
cv2.setMouseCallback('image',draw_circle)
while(1):
cv2.imshow('image',img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()

OpenCV Template Matching
Template Matching is a method used for finding the location of a template image in a larger image. In OpenCV, we use a function cv.matchTemplate() for template matching. It simply slides the template image over the larger input image (as in 2D convolution) and compares the template image with the patch of input image under the template image. It returns a grayscale image, where each pixel denotes how much does the neighbourhood of that pixel match with the template. There are several comparison methods that can be implemented in OpenCV.
If input image is of size (WxH) and template image is of size (wxh), output image will have a size of (W-w+1, H-h+1).Upon getting results, the best matches can be found as global minimums (when TM_SQDIFF was used) or maximums (when TM_CCORR or TM_CCOEFF was used) using the minMaxLoc function. Take it as the top-left corner of the rectangle and take (w,h) as width and height of the rectangle. That rectangle is your region of template.
Here is the syntax of cv.matchTemplate():
cv.matchTemplate(image, templ, method,mask)
Parameters:
image: Image where the search is running. It must be 8-bit or 32-bit floating-point.
templ: Searched template. It must be not greater than the source image and have the same data type.
result Map of comparison results. It must be single-channel 32-bit floating-point. If image is W×H and templ is w×h , then result is (W−w+1)×(H−h+1) .
method: Parameter specifying the comparison method, see TemplateMatchModes
mask: Optional
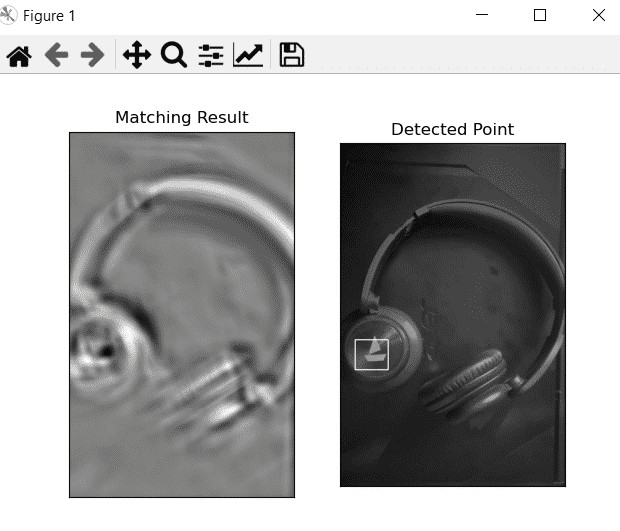
Here is an example in which we take this image as the template image:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('headphone1.jpeg',0)
img2 = img.copy()
template = cv.imread('logo1.jpeg',0)
w, h = template.shape[::-1]
# All the 6 methods for comparison in a list
# Apply template Matching
res = cv.matchTemplate(img,template,eval('cv.TM_CCOEFF'))
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv.rectangle(img,top_left, bottom_right, 255, 2)
plt.subplot(121),plt.imshow(res,cmap = 'gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img,cmap = 'gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.show()
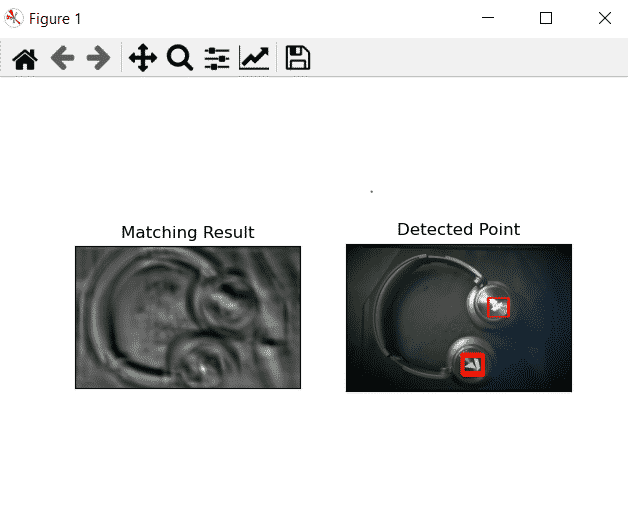
Template Matching with Multiple Objects
In the above example, we searched for template images that occurred only once in the image. Suppose a particular object occurs multiple times in a particular image. In this scenario, we will use the thresholding as cv2.minMaxLoc() just gives the location of one template image and it won't give all locations of the template images. Consider the following example.
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img2=cv.imread('headohone2.jpeg',1)
img_gray = cv.imread('headohone2.jpeg',0)
template = cv.imread('logo1.jpeg',0)
w, h = template.shape[::-1]
res = cv.matchTemplate(img_gray,template,eval('cv.TM_CCOEFF_NORMED'))
print(res)
threshold = 0.52
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):
cv.rectangle(img2, pt, (pt[0] + w, pt[1] + h), (255,0,0), 1)
plt.subplot(121),plt.imshow(res,cmap = 'gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img2,cmap = 'gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.show()
OpenCV Video Capture
OpenCV can also be used for video processing. With OpenCV, we can capture a video from the camera and it also lets us create a video capture object which is helpful to capture videos through webcam and then you may perform desired operations on that video. Besides this you can also play and perform operation on a video file and save them.
Capture Video from Camera
Often, we have to capture a live stream with a camera. Using OpenCV’s very simple interface, we can easily do it. Here is a simple task to get started. In this task we will capture a video from the camera ( in-built webcam of my laptop) and display it as a grayscale video.
In OpenCV we need to create a VideoCapture object to capture a video. We pass either the device index or the name of a video file as its arguments. Device index is just the number to specify the camera in case we have multiple webcams available. Normally one has only a single camera connected (as in my case), so simply pass 0.After this we start to capture each frame using a loop and process it accordingly. At the end, we just break from the loop and release the capture.
import numpy as np
import cv2
capture = cv2.VideoCapture(0)
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
# Our operations on the frame come here
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Display the resulting frame
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
capture.release()
cv2.destroyAllWindows()
capture.read() returns a bool (True/False) and the frame which webcam is currently reading. If the frame is read correctly, it will be True. So you can check the end of the video by checking this return value.
Playing Video from file
Playing a video using OpenCV in python is very similar to capturing live feed from a webcam as we saw in the last section.We just have to change the camera index with the video file name. But sometimes the video file may be corrupt or couldn't be read properly,so we use isOpened() method of VideoCapture object to make sure that the video is read successfully. Also, while displaying the frame, we should use appropriate time for cv2.waitKey(),as for too less, video will be very fast and for too high values, video will be slow.
import numpy as np
import cv2
cap = cv2.VideoCapture('vtest.avi')
while(cap.isOpened()):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
Saving a Video
Saving an image after processing it using OpenCV is quite simple and we saw how to do it using cv2.imwrite() function. But for a video, after processing it frame-by-frame a little more work is required to save it.
Here to save a video we create a VideoWriter object in addition to VideoCapture Object. The syntax of VideoWriter is given below:
cv2.VideoWriter(filename,fourcc,fps,frameSize,isColor)
Parameters:
filename: The output file name (eg: bday.avi).
fourcc: specify the FourCC code. FourCC is a 4-byte code used to specify the video codec. The list of available codes can be found in fourcc.org. It is platform dependent. Following codecs works fine for me.
In Fedora: DIVX, XVID, MJPG, X264, WMV1, WMV2. (XVID is more preferable. MJPG results in high size video. X264 gives very small size video)
In Windows: DIVX (More to be tested and added)
In OSX : (I don’t have access to OSX. Can some one fill this?)
FourCC code is passed as cv2.VideoWriter_fourcc('M','J','P','G') or cv2.VideoWriter_fourcc(*'MJPG) for MJPG.
fps: number of frames per second (fps)
frameSize: size of frame.
isColor: It is a flag value. If it is True, encoders expect a color frame, otherwise it works with grayscale frames.
Here is a code that captures frames from a Camera, flip each one in a vertical direction and save it.
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
# Define the codec and create VideoWriter object
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi',fourcc, 20.0, (640,480))
while(cap.isOpened()):
ret, frame = cap.read()
if ret==True:
frame = cv2.flip(frame,0)
# write the flipped frame
out.write(frame)
cv2.imshow('frame',frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
break
# Release everything if job is finished
cap.release()
out.release()
cv2.destroyAllWindows()
Face Detection Using OpenCV
Using OpenCV, complex tasks such as face detection becomes easy to implement and since pre-trained models that are capable of detecting faces, noses, and eyes are included in the OpenCV package, we don't need to train any classifier. Here is an article on Face detection using Viola-Jones algorithm that explains how we can detect faces using OpenCV.You will also go through the concept of cascading classifier in this article that is also used in our next section i.e. car detection using OpenCV
Car detection with OpenCV
You may have seen in the article Face detection using Face Recognition Using Python and OpenCV Viola-Jones algorithm that we used pre-trained models to detect faces and eyes. Similarly, we also have a pre-trained model that can detect cars. All we have to do is to use this model to erect cars and then mark the cars with rectangles.
# OpenCV Python program to detect cars in video frame
# import libraries of python OpenCV
import cv2
# capture frames from a video
cap = cv2.VideoCapture('video.avi')
# Trained XML classifiers describes some features of some object we want to detect
car_cascade = cv2.CascadeClassifier('cars.xml')
# loop runs if capturing has been initialized.
while True:
# reads frames from a video
ret, frames = cap.read()
# convert to gray scale of each frames
gray = cv2.cvtColor(frames, cv2.COLOR_BGR2GRAY)
# Detects cars of different sizes in the input image
cars = car_cascade.detectMultiScale(gray, 1.1, 1)
# To draw a rectangle in each cars
for (x,y,w,h) in cars:
cv2.rectangle(frames,(x,y),(x+w,y+h),(0,0,255),2)
# Display frames in a window
cv2.imshow('video2', frames)
# Wait for Esc key to stop
if cv2.waitKey(33) == 27:
break
# De-allocate any associated memory usage
cv2.destroyAllWindows()
Face Recognition Using OpenCV
Face recognition, as the names suggest includes detecting faces and then label them with the name of the person. It is a bit more complex than the last two examples. Here we have to use some libraries outside of OpenCV. I would highly recommend going through the article Face Recognition Using Python and OpenCV to understand face recognition works and how to implement it using OpenCV.
Wrapping Up
In conclusion, this OpenCV tutorial has provided a comprehensive guide to learning OpenCV in Python, equipping you with essential skills for image processing and computer vision tasks.
If you're interested in expanding your Python proficiency, consider exploring Great Learning's Free Python courses. Designed to cater to beginners and advanced learners alike, these courses offer structured learning paths to master Python programming.
Additionally, our Software Development Course provides in-depth training in software engineering principles and practices, ideal for those aspiring to build a career in software development.
With an industry-relevant curriculum and hands-on projects, our courses empower you to excel in the dynamic technology field with the most demanded skills and expertise.
FAQs of OpenCV In Python
A.OpenCV in python is an open-source computer vision and machine learning software library. It was built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in commercial products. Being a BSD-licensed product, OpenCV makes it easy for businesses to utilize and modify the code.
A: To install OpenCV 3.0 and Python 3.4+ on Ubuntu, you need to follow the steps mentioned below:
Start with installing prerequisites
Now Setup Python (Part 1)
Setup Python (Part 2)
Now you need to build and install OpenCV 3.0 with Python 3.4+ bindings
Sym-link OpenCV 3.0
The last step includes testing out the OpenCV 3.0 and Python 3.4+ install.
A: To start learning OpenCV, you can refer to the tutorials offered by Great Learning. You will not only learn the basics and also get a good idea of the overall OpenCV.
A: The full form for OpenCV is Open Source Computer Vision Library.
A: OpenCV is a vast open-source library that is used for machine learning, computer vision, and image processing. At present, it plays a key role in real-time. Using OpenCV helps in processing images as well as videos to classify faces, objects, or even handwriting of humans.
A: Earlier OpenCV was not one of the easiest things to learn. However, these days it has been simplified. You can go through the easy-to-learn tutorials to understand OpenCV.
A: It totally depends on the stage of a project. If you are prototyping, Python is more useful. If it is for the purpose of production, C++ is better. However, you also need to know that Python is slower than C++.
A: Learning OpenCV is certainly worth it, and you should start learning OpenCV with Python. This programming language is easier to learn and faster to prototype the Computer Vision algorithms.
A: It is a library; therefore you first need to know how to use a library. The next thing is learning the fundamentals of image processing. You also need to have in-depth knowledge of classes and inheritance in C++.
A: First fire up your Python and follow the commands mentioned below:
Importing cv2 # import the opencv library, and
cv2. __version__ #. This will help in printing the version of your opencv3.