
The acceleration of text-to-video artificial intelligence throughout 2025 and 2026 marks a decisive shift in digital media production.
Rather than merely visualizing text, modern architectures demonstrate a complete convergence of video generation, audio synthesis, and physical simulation.
As platforms evolve from single-clip generators to comprehensive production engines, the technical barrier to cinematic creation continues to collapse.
For technology leaders, digital creators, and forward-looking professionals, mastering individual software interfaces is no longer an adequate strategy. Understanding the underlying agentic AI systems that drive these platforms has become an urgent professional requirement.
In this blog, we will dissect the current state of video generation models and explain why structured education in AI provides a critical competitive advantage.
How Text-to-Video AI Is Developing?

1. Stronger Motion Continuity & Lifelike Output
Text-to-video AI in 2025–2026 is achieving unprecedented visual realism and motion stability through the following advancements:
- Improved temporal consistency: Successive frames now maintain precise architectural and structural integrity, preventing the morphing artifacts that plagued earlier generations of models.
- Realistic physics simulation: Systems generate accurate gravitational reactions and material physics, ensuring falling debris, splashing liquids, and object collisions behave with mathematical precision.
- Facial micro-expressions: Generation algorithms map subtle muscular shifts on human faces, delivering emotional authenticity instead of robotic stiffness.
- Reduced frame instability: Flickering backgrounds and jittery edges have been largely eliminated, enabling professional-grade visual stability suitable for commercial production.
- Cinematic-quality movement: Smooth camera tracking and intentional subject motion replace the chaotic movement patterns of earlier tools.
- Use case: A film studio can generate high-quality pre-visualization (previs) sequences for action scenes, complete with realistic explosions, facial reactions, and stable camera movement before committing to expensive on-set production.

2. Simulation-Driven Intelligence
Modern systems are increasingly powered by simulation-based logic that grounds visuals in physical and environmental realism:
- Physics-aware modeling: Advanced architectures calculate how light, shadow, and mass interact in 3D space before rendering a 2D frame.
- Environmental interaction: Subjects displace water, cast proportionate shadows, and interact naturally with digital surroundings instead of appearing layered over static backgrounds.
- Context-aware scene generation: AI infers environmental details such as weather conditions or background activity without requiring explicit prompts for every element.
- Object behavior understanding: Generative AI models recognize cause and effect, such as a dropped glass shattering or footsteps creating ripples in water.
- Use case: An architecture firm can generate immersive walkthrough videos of proposed buildings, where lighting shifts realistically throughout the day and environmental elements respond naturally to weather simulations.

3. Unified Sound and Visual Creation
Multimodal integration is redefining content generation by merging audio and visual production into a single workflow:
- Native audio generation: Models synthesize soundscapes concurrently with video rendering, removing the need for separate audio engineering.
- Synchronized dialogue: Generated speech aligns precisely with facial movements and phonetic timing.
- Ambient sound integration: Contextual background noise, urban traffic, wind, and rustling leaves are embedded naturally based on the visual setting.
- Voice–lip alignment: Spoken syllables and lip articulation operate seamlessly, transforming silent clips into complete audiovisual media.
- Use case: A marketing team can create fully produced product explainer videos, including narration, dialogue, and background ambiance, without hiring separate voice artists or sound designers.

As video generation evolves from simple task execution to intelligent, goal-driven behavior, the industry is shifting toward Agentic AI systems that can plan, adapt, and act with minimal oversight.
To lead in this new era of digital autonomy, professionals need more than creative intuition; they require a strong technical foundation to design systems that reason and operate independently.
Addressing this need, Johns Hopkins University offers a 16-week online Certificate Program in Agentic AI that bridges the gap between using AI tools and building autonomous AI ecosystems, equipping learners with the expertise to develop systems that drive real-world organizational outcomes.
Certificate Program in Agentic AI
Learn the architecture of intelligent agentic systems. Build agents that perceive, plan, learn, and act using Python-based projects and cutting-edge agentic architectures.
How This Program Empowers You?
- Build Autonomous Systems: Learn to design agents capable of perceiving, reasoning, and acting independently to solve complex, multi-step challenges.
- Master Advanced Architectures: Gain expertise in symbolic reasoning, Belief-Desire-Intention (BDI) models, and Reinforcement Learning to enhance adaptability and decision-making.
- Coordinate Multi-Agent Ecosystems: Understand how multiple agents collaborate using frameworks such as the Model Context Protocol (MCP) and principles of Game Theory to scale intelligent operations.
- Apply Agentic RAG: Move beyond traditional retrieval methods by building systems that synthesize, refine, and validate information iteratively for higher accuracy.
- Navigate Ethics and Safety: Address alignment challenges and mitigate risks in autonomous systems through Responsible AI principles and governance frameworks.
Even without a prior technical background, the program includes a structured Python pre-work module to build the necessary foundation, ensuring you are fully prepared to succeed in an AI-powered future.
4. Longer, Directed Storytelling
Text-to-video AI is transitioning from short experimental clips to structured, cinematic narratives:
- Extended scene continuity: Continuous sequences exceeding 60 seconds maintain environmental coherence and character placement.
- Directed camera movement: Granular control over panning, tilting, tracking, and dolly zooms enables deliberate cinematographic framing.
- Multi-shot coherence: Smooth transitions between wide establishing shots and tight close-ups preserve visual consistency.
- Use case: Independent creators can produce short films or episodic web series entirely through AI, maintaining narrative consistency across multiple scenes without traditional production crews.

5. Persistent Character Identity
Character consistency across scenes has evolved into a core capability of modern text-to-video systems, eliminating one of the biggest limitations of earlier models:
- Cross-scene identity locking: Facial structure, body proportions, hairstyles, clothing, and defining attributes remain stable even as characters move across different environments, lighting conditions, or camera angles.
- Narrative memory retention: The model preserves contextual details established earlier in the storyline, such as accessories, injuries, emotional states, or objects being carried,d ensuring continuity throughout scene transitions.
- Stylistic continuity: Lighting schemes, color grading, costume design, and overall directorial tone remain consistent across the project, preventing visual drift and maintaining a unified cinematic identity.
- Use case: Brands can create a recurring AI-generated mascot or spokesperson who appears consistently across advertisements, social media campaigns, and explainer videos, building long-term brand recognition.

6. Instant Iteration & Interactive Control
The newest generation of platforms emphasizes creative agility, allowing creators to refine and direct outputs with precision rather than relying on static one-shot prompts:
- Real-time prompt refinement: Users can modify descriptive inputs during generation to immediately correct inconsistencies, adjust tone, or enhance visual detail without restarting the entire sequence.
- Style modification: Lighting conditions, textures, color palettes, and visual aesthetics can be altered dynamically while preserving the core scene composition and character positioning.
- Selective scene regeneration: Specific frames or segments can be re-rendered independently, ensuring targeted improvements without disrupting surrounding footage or narrative flow.
- User-driven direction: Interfaces increasingly resemble professional 3D production environments, offering interactive control over camera movement, framing, spatial layout, and environmental elements.
- Use case: Advertising agencies can rapidly test multiple creative variations of the same campaign, changing tone, lighting, or messaging in minutes before selecting the highest-performing version for launch.

This shift transforms text-to-video AI from a passive generation tool into an adaptive creative system that supports rapid experimentation and production-level workflows.
Major Example
A defining example of recent progress in text-to-video AI is Seedance 2.0, launched by ByteDance in February 2025 as a major upgrade to its generative video model.

The platform is positioned as a strong competitor to leading Western systems such as OpenAI’s Sora 2 and Google’s Veo. Unlike earlier models that rely mainly on text prompts, Seedance 2.0 introduces multimodal generation with advanced creative controls:
- Multimodal Directional Control: Combines text prompts with up to 9 reference images, 3 choreography video clips, and MP3 files for synchronized audio-visual output.
- High-quality video output: Generates cinematic clips between 4 –15 seconds at up to 2K resolution.
- Faster performance: Operates approximately 30% faster than its predecessor.
- Improved motion handling: Accurately renders complex physical movements, including martial arts sequences.
- Stronger character consistency: Maintains stable identity across multiple shots.
- Watermark-free output: Delivers clean, production-ready videos.
- Professional editing tools: Includes a Universal @-tag system for locking visual elements, Scene Extension for seamless shot additions, and Targeted Editing for modifying specific segments without regenerating the full video.
- Current availability: Accessible to select beta users on Jimeng AI, with planned integration into Dreamina.
Overall, Seedance 2.0 highlights the rapid pace of AI video innovation in China, even as geopolitical and regulatory factors may influence its potential expansion into the US market.
How an AI Agent Program Helps You Build Job-Ready Expertise?
This changing shift in AI platforms presents a stark reality: mastering software interfaces offers only a temporary advantage. To maintain professional relevance, technological leaders must pivot from operating applications to architecting autonomous solutions.
A structured learning path, such as the 8-week Certificate Program in Generative AI & Agents Fundamentals from Johns Hopkins University, bridges this gap by assuming no prior technical or programming background while providing a comprehensive foundation in applied AI.
Certificate Program in Generative AI & Agents Fundamentals
A program focused on the foundational concepts of Generative AI and AI agents. It covers topics like NLP, Prompt Engineering, and Responsible AI, with practical applications for various industries.
Understanding agentic systems where AI operates autonomously to achieve complex objectives is the strategic differentiator that builds job-ready expertise and insulates careers against automated obsolescence. Here is how it helps
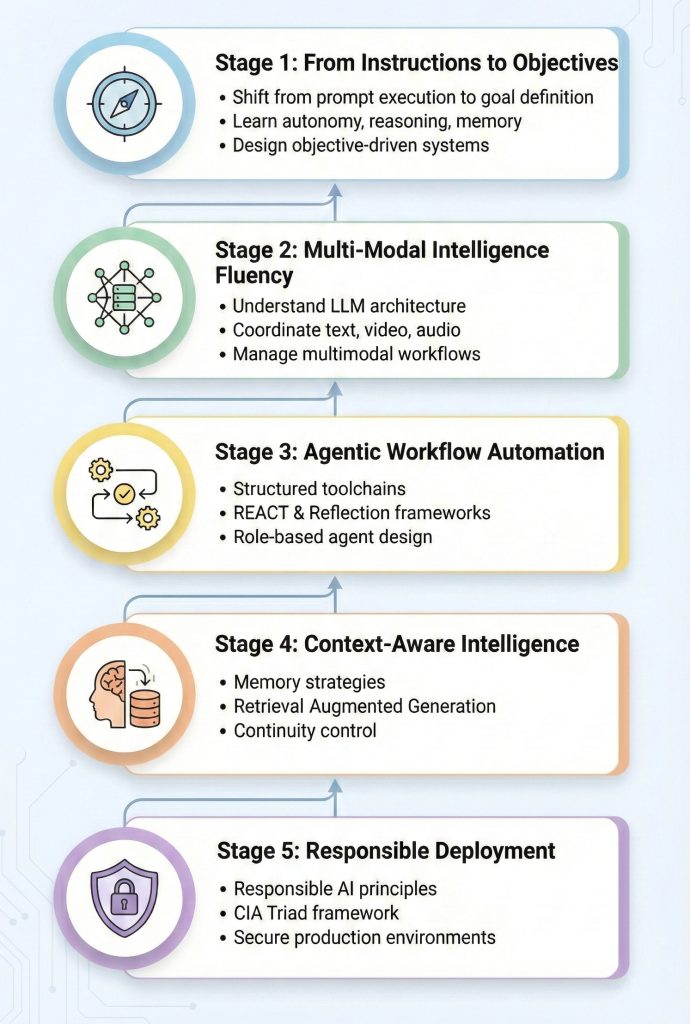
1. From Instructions to Objectives
Text-to-Video AI is shifting from executing single prompts to achieving complex creative goals. Instead of telling the system what to generate frame by frame, professionals must define objectives such as “Create a cinematic 30-second product launch sequence with emotional progression and synchronized narration.
An AI Agent course teaches how agentic systems move from instruction-based interaction to goal-driven intelligence. Learners understand core components such as environment, autonomy, reasoning, memory, and tool usage.
2. Fluency in Multi-Modal Intelligence
Modern Text-to-Video systems combine text reasoning, video synthesis, audio generation, and contextual memory in a single workflow. To manage such systems, professionals must understand how generative AI and NLP function at a foundational level.
The program builds fluency in Large Language Model (LLM) architecture and generative mechanics, ensuring learners understand how multimodal systems coordinate different data types.
3. Automation with Integrated Toolchains
Text-to-Video production increasingly involves working on multiple AI tools, script generators, visual engines, sound models, and editing modules into a unified workflow.
The course trains learners to design structured agentic workflows by defining agent roles, managing prompts, and controlling tool access. Modern frameworks such as REACT and Reflection are introduced to improve task-specific agent design.
4. Context-Aware Intelligence
Advanced Text-to-Video systems require memory and contextual awareness to maintain continuity across scenes. Without this, characters, lighting, or narrative tone may reset with each new input.
The program emphasizes memory strategies and advanced techniques like Retrieval-Augmented Generation (RAG) to ensure outputs remain accurate, relevant, and consistent.
5. Industry-Ready and Responsible Deployment
As Text-to-Video AI becomes commercially viable, professionals must also understand responsible AI practices and security risks. Production environments require safe deployment, data protection, and ethical safeguards.
The curriculum covers Responsible AI principles, major LLM vulnerabilities, and security frameworks such as the CIA Triad (Confidentiality, Integrity, Availability).
Text-to-Video AI is no longer just about generating clips; it is about managing intelligent systems that plan, create, adapt, and optimize content autonomously. An AI Agent course provides the structured foundation needed to design, control, and deploy these systems effectively.
Capabilities You Develop
1. Core Agentic Concepts
Professionals master the principles of autonomous decision-making, enabling AI systems to operate independently within complex video production pipelines rather than relying on constant human intervention.
2. Architecture & Modeling
Learners understand how to structure AI frameworks that ensure stable interaction between large language models and video diffusion models, reducing breakdowns in multimodal workflows.
3. Reasoning Techniques
The program teaches AI reasoning strategies that help systems logically determine event sequences critical for maintaining narrative flow in long-form Text-to-Video generation.
4. Data Integration
Practitioners learn to integrate external datasets and APIs into AI workflows, allowing generated videos to adapt dynamically to real-time information.
5. Machine Learning Paradigms
Understanding ML algorithms, such as supervised, unsupervised, and reinforcement learning, enables professionals to fine-tune enterprise AI systems for specific brand styles or visual aesthetics.
6. Advanced AI Systems
Learners gain the ability to manage complex frameworks where specialized AI components handle tasks such as color grading, dialogue generation, sound design, and visual rendering simultaneously.
7. Ethics & Safety Implementation
The curriculum emphasizes responsible AI deployment by implementing safeguards against copyright violations, bias, misinformation, and malicious use in automated media generation.
8. Advanced Prompt Engineering
Learners develop the ability to craft structured, machine-readable instructions that consistently produce accurate visual and audio outputs across different AI models.
9. Agentic Workflow Design
The program trains professionals to build end-to-end automated pipelines that reduce manual editing while increasing scalability and efficiency.
10. Strategic AI Optimization
Beyond technical skills, learners develop strategic thinking to identify which production tasks can be optimized through AI agents to maximize operational efficiency.
By mastering these capabilities, professionals move beyond executing predefined tasks to designing intelligent systems that operate independently and at scale.
This shift positions them for the demands of the 2026 workforce, where value lies in building and optimizing AI-driven solutions.
As a result, they enhance their long-term career relevance and future-proof themselves in an increasingly automated economy.
Conclusion
Text-to-Video AI is evolving into a sophisticated, autonomous production ecosystem where success depends on more than creative prompting.
As multimodal intelligence, contextual memory, and system-level automation become standard, professionals must move beyond using tools to understand and design the AI systems behind them.
An AI Agent program provides the structured foundation to build this expertise, positioning individuals to stay relevant, competitive, and future-ready in the rapidly advancing AI-driven economy.








