
- What is Linear Regression?
- Isn’t Linear Regression from Statistics?
- Linear Regression Model Representation
- Performance of Regression
- Polynomial Regression
- Underfitting and Overfitting
- Implementing Linear Regression in Python
- Linear Regression in R
- Advantages of Using Linear Regression
- Linear Regression - Learning the Model
- Preparing Data for Linear Regression
- Our Machine Learning Courses
What is Linear Regression?
Linear Regression is the basic form of regression analysis. It assumes that there is a linear relationship between the dependent variable and the predictor(s). In regression, we try to calculate the best fit line, which describes the relationship between the predictors and predictive/dependent variables.
There are four assumptions associated with a linear regression model:
- Linearity: The relationship between independent variables and the mean of the dependent variable is linear.
- Homoscedasticity: The variance of residuals should be equal.
- Independence: Observations are independent of each other.
- Normality: The dependent variable is normally distributed for any fixed value of an independent variable.
Isn’t Linear Regression from Statistics?
Before we dive into the details of linear regression, you may be asking yourself why we are looking at this algorithm.
Isn’t it a technique from statistics? Machine learning, more specifically the field of predictive modeling, is primarily concerned with minimizing the error of a model or making the most accurate predictions possible at the expense of explainability. In applied machine learning, we will borrow and reuse algorithms from many different fields, including statistics and use them towards these ends.
As such, linear regression was developed in the field of statistics and is studied as a model for understanding the relationship between input and output numerical variables. However, it has been borrowed by machine learning, and it is both a statistical algorithm and a machine learning algorithm.
Linear Regression Model Representation
Linear regression is an attractive model because the representation is so simple.
The representation is a linear equation that combines a specific set of input values (x), the solution to which is the predicted output for that set of input values (y). As such, both the input values (x) and the output value are numeric.
The linear equation assigns one scale factor to each input value or column, called a coefficient and represented by the capital Greek letter Beta (B). One additional coefficient is added, giving the line an additional degree of freedom (e.g., moving up and down on a two-dimensional plot) and is often called the intercept or the bias coefficient.
For example, in a simple regression problem (a single x and a single y), the form of the model would be:
Y= β0 + β1x
In higher dimensions, the line is called a plane or a hyper-plane when we have more than one input (x). The representation, therefore, is in the form of the equation and the specific values used for the coefficients (e.g., β0and β1 in the above example).
Performance of Regression
The regression model’s performance can be evaluated using various metrics like MAE, MAPE, RMSE, R-squared, etc.
Mean Absolute Error (MAE)
By using MAE, we calculate the average absolute difference between the actual values and the predicted values.
Mean Absolute Percentage Error (MAPE)
MAPE is defined as the average of the absolute deviation of the predicted value from the actual value. It is the average of the ratio of the absolute difference between actual & predicted values and actual values.
Root Mean Square Error (RMSE)
RMSE calculates the square root average of the sum of the squared difference between the actual and the predicted values.
R-squared values
R-square value depicts the percentage of the variation in the dependent variable explained by the independent variable in the model.
RSS = Residual sum of squares: It measures the difference between the expected and the actual output. A small RSS indicates a tight fit of the model to the data. It is also defined as follows:
TSS = Total sum of squares: It is the sum of data points’ errors from the response variable’s mean.
R2 value ranges from 0 to 1. The higher the R-square value better the model. The value of R2 increases if we add more variables to the model, irrespective of whether the variable contributes to the model or not. This is the disadvantage of using R2.
Adjusted R-squared values
The Adjusted R2 value fixes the disadvantage of R2. The adjusted R2 value will improve only if the added variable contributes significantly to the model, and the adjusted R2 value adds a penalty to the model.
where R2 is the R-square value, n = the total number of observations, and k = the total number of variables used in the model, if we increase the number of variables, the denominator becomes smaller, and the overall ratio will be high. Subtracting from 1 will reduce the overall Adjusted R2. So to increase the Adjusted R2, the contribution of additive features to the model should be significantly high.
Simple Linear Regression Example
For the given equation for the Linear Regression,
If there is only 1 predictor available, then it is known as Simple Linear Regression.
While executing the prediction, there is an error term that is associated with the equation.
The SLR model aims to find the estimated values of β1 & β0 by keeping the error term (ε) minimum.
Multiple Linear Regression Example
Contributed by: Rakesh Lakalla
LinkedIn profile: https://www.linkedin.com/in/lakkalarakesh/
For the given equation of Linear Regression,

if there is more than 1 predictor available, then it is known as Multiple Linear Regression.
The equation for MLR will be:

β1 = coefficient for X1 variable
β2 = coefficient for X2 variable
β3 = coefficient for X3 variable and so on…
β0 is the intercept (constant term). While making the prediction, there is an error term that is associated with the equation.

The goal of the MLR model is to find the estimated values of β0, β1, β2, β3… by keeping the error term (i) minimum.
Broadly speaking, supervised machine learning algorithms are classified into two types-
- Regression: Used to predict a continuous variable
- Classification: Used to predict discrete variable
In this post, we will discuss one of the regression techniques, “Multiple Linear Regression,” and its implementation using Python.
Linear regression is one of the statistical methods of predictive analytics to predict the target variable (dependent variable). When we have one independent variable, we call it Simple Linear Regression. If the number of independent variables is more than one, we call it Multiple Linear Regression.
Assumptions for Multiple Linear Regression
- Linearity: There should be a linear relationship between dependent and independent variables, as shown in the below example graph.
2. Multicollinearity: There should not be a high correlation between two or more independent variables. Multicollinearity can be checked using a correlation matrix, Tolerance and Variance Influencing Factor (VIF).
3. Homoscedasticity: If Variance of errors is constant across independent variables, then it is called Homoscedasticity. The residuals should be homoscedastic. Standardized residuals versus predicted values are used to check homoscedasticity, as shown in the below figure. Breusch-Pagan and White tests are the famous tests used to check Homoscedasticity. Q-Q plots are also used to check homoscedasticity.
4. Multivariate Normality: Residuals should be normally distributed.
5. Categorical Data: Any categorical data present should be converted into dummy variables.
6. Minimum records: There should be at least 20 records of independent variables.
A mathematical formulation of Multiple Linear Regression
In Linear Regression, we try to find a linear relationship between independent and dependent variables by using a linear equation on the data.
The equation for a linear line is-
Y=mx + c
Where m is slope and c is the intercept.
In Linear Regression, we are actually trying to predict the best m and c values for dependent variable Y and independent variable x. We fit as many lines and take the best line that gives the least possible error. We use the corresponding m and c values to predict the y value.
The same concept can be used in multiple Linear Regression where we have multiple independent variables, x1, x2, x3…xn.
Now the equation changes to-
Y=M1X1 + M2X2 + M3M3 + …MnXn+C
The above equation is not a line but a plane of multi-dimensions.
Model Evaluation:
A model can be evaluated by using the below methods-
- Mean absolute error: It is the mean of absolute values of the errors, formulated as-
- Mean squared error: It is the mean of the square of errors.
- Root mean squared error: It is just the square root of MSE.
Applications
- The effect of the independent variable on the dependent variable can be calculated.
- Used to predict trends.
- Used to find how much change can be expected in a dependent variable with change in an independent variable.
Polynomial Regression
Polynomial regression is a non-linear regression. In Polynomial regression, the relationship of the dependent variable is fitted to the nth degree of the independent variable.
Equation of polynomial regression:
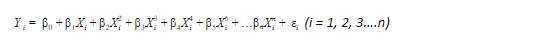
Underfitting and Overfitting
When we fit a model, we try to find the optimized, best-fit line, which can describe the impact of the change in the independent variable on the change in the dependent variable by keeping the error term minimum. While fitting the model, there can be 2 events that will lead to the bad performance of the model. These events are
Underfitting
Underfitting is the condition where the model cannot fit the data well enough. The under-fitted model leads to low accuracy of the model. Therefore, the model is unable to capture the relationship, trend, or pattern in the training data. Underfitting of the model could be avoided by using more data or by optimizing the parameters of the model.
Overfitting
Overfitting is the opposite case of underfitting, i.e., when the model predicts very well on training data and is not able to predict well on test data or validation data. The main reason for overfitting could be that the model is memorizing the training data and is unable to generalize it on a test/unseen dataset. Overfitting can be reduced by making feature selection or by using regularisation techniques.
The above graphs depict the 3 cases of the model performance.
Implementing Linear Regression in Python
Contributed by: Ms. Manorama Yadav
LinkedIn: https://www.linkedin.com/in/manorama-3110/
Dataset Introduction
The data concerns city-cycle fuel consumption in miles per gallon(mpg) to be predicted. There are a total of 392 rows, 5 independent variables, and 1 dependent variable. All 5 predictors are continuous variables.
Attribute Information:
- mpg: continuous (Dependent Variable)
- cylinders: multi-valued discrete
- displacement: Continuous
- horsepower: continuous
- weight: Continuous
- acceleration: Continuous
The objective of the problem statement is to predict the miles per gallon using the Linear Regression model.
Python Packages for Linear Regression
Import the necessary Python package to perform various steps like data reading, plotting the data, and performing linear regression. Import the following packages:

Read the data
Download the data and save it in the data directory of the project folder.
Simple Linear Regression With scikit-learn
Simple Linear regression has only 1 predictor variable and 1 dependent variable. From the above dataset, let’s consider the effect of horsepower on the ‘mpg’ of the vehicle.
Let’s take a look at what the data looks like:
From the above graph, we can infer a negative linear relationship between horsepower and miles per gallon (mpg). With horsepower increasing, mpg is decreasing.
Now, let’s perform the Simple linear regression.
From the output of the above SLR model, the equation of the best fit line of the model is
mpg = 39.94 + (-0.16)*(horsepower)
By comparing the above equation to the SLR model equation Yi= βiXi + β0 , β0=39.94, β1=-0.16
Now, check for the model relevancy by looking at its R2 and RMSE Values
R2 and RMSE (Root mean square) values are 0.6059 and 4.89, respectively. It means that 60% of the variance in mpg is explained by horsepower. For a simple linear regression model, this result is okay but not so good since there could be an effect of other variables like cylinders, acceleration, etc. RMSE value is also very less.
Let’s check how the line fits the data.
From the graph, we can infer that the best fit line is able to explain the effect of horsepower on mpg.
Multiple Linear Regression With scikit-learn
Since the data is already loaded in the system, we will start performing multiple linear regression.
The actual data has 5 independent variables and 1 dependent variable (mpg)
The best fit line for Multiple Linear Regression is
Y = 46.26 + -0.4cylinders + -8.313e-05displacement + -0.045horsepower + -0.01weight + -0.03acceleration
By comparing the best fit line equation with
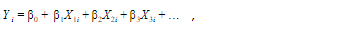
β0 (Intercept)= 46.25, β1 = -0.4, β2 = -8.313e-05, β3= -0.045, β4= 0.01, β5 = -0.03
Now, let’s check the R2 and RMSE values.
R2 and RMSE (Root mean square) values are 0.707 and 4.21, respectively. It means that ~71% of the variance in mpg is explained by all the predictors. This depicts a good model. Both values are less than the results of Simple Linear Regression, which means that adding more variables to the model will help in good model performance. However, the more the value of R2 and the least RMSE, the better the model will be.
Multiple Linear Regression- Implementation using Python
Let us take a small data set and try out a building model using python.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
data=pd.read_csv("Consumer.csv")
data.head()
The above figure shows the top 5 rows of the data. We are actually trying to predict the Amount charged (dependent variable) based on the other two independent variables, Income and Household Size. We first check for our assumptions in our data set.
- Check for Linearity
plt.figure(figsize=(14,5))
plt.subplot(1,2,1)
plt.scatter(data['AmountCharged'], data['Income'])
plt.xlabel('AmountCharged')
plt.ylabel('Income')
plt.subplot(1,2,2)
plt.scatter(data['AmountCharged'], data['HouseholdSize'])
plt.xlabel('AmountCharged')
plt.ylabel('HouseholdSize')
plt.show()
We can see from the above graph, there exists a linear relationship between the Amount Charged and Income, Household Size.
2. Check for Multicollinearity
sns.scatterplot(data['Income'],data['HouseholdSize'])
There exists no collinearity between Income and HouseholdSize from the above graph.
We split our data to train and test in a ratio of 80:20, respectively, using the function train_test_split
X = pd.DataFrame(np.c_[data['Income'], data['HouseholdSize']], columns=['Income','HouseholdSize'])
y=data['AmountCharged']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=9)
3. Check for Homoscedasticity
First, we need to calculate residuals-
resi=y_test-prediction
Polynomial Regression With scikit-learn
For Polynomial regression, we will use the same data that we used for Simple Linear Regression.
The graph shows that the relationship between horsepower and miles per gallon is not perfectly linear. It’s a little bit curved.
Graph for the Best fit line for Simple Linear Regression as per below:
From the plot, we can infer that the best fit line is able to explain the effect of the independent variable, however, this does not apply to most of the data points.
Let’s try polynomial regression on the above dataset. Let’s fit degree = 2
Now, visualize the Polynomial Regression results
From the graph, the best fit line looks better than the Simple Linear Regression.
Let’s find out the model performance by calculating mean absolute Error, Mean squared error, and Root mean square.
Simple Linear Regression Model Performance:
Polynomial Regression (degree = 2) Model Performance:
From the above results, we can see that Error-values are less in Polynomial regression but there is not much improvement. We can increase the polynomial degree and experiment with the model performance.
Advanced Linear Regression with statsmodels
There are many ways to perform regression in python.
- scikit Learn
- statsmodels
In the MLR in the python section explained above, we have performed MLR using the scikit learn library. Now, let’s perform MLR using the statsmodels library.
Import the below-required libraries
Now, perform Multiple Linear Regression using statsmodels
From the above results, R2 and Adjusted R2 are 0.708 and 0.704, respectively. All the independent variables explain almost 71% of the variation in the dependent variables. The value of R2 is the same as the result of the scikit learn library.
By looking at the p-value for the independent variables, intercept, horsepower, and weight are important variables since the p-value is less than 0.05 (significance level). We can try to perform MLR by removing other variables which are not contributing to the model and selecting the best model.
Now, let’s check the model performance by calculating the RMSE value:
Linear Regression in R
Contributed by: By Mr. Abhay Poddar
To see an example of Linear Regression in R, we will choose the CARS, which is an inbuilt dataset in R. Typing CARS in the R Console can access the dataset. We can observe that the dataset has 50 observations and 2 variables, namely distance and speed. The objective here is to predict the distance traveled by a car when the speed of the car is known. Also, we need to establish a linear relationship between them with the help of an arithmetic equation. Before getting into modeling, it is always advisable to do an Exploratory Data Analysis, which helps us to understand the data and the variables.
Exploratory Data Analysis
This paper aims to build a Linear Regression Model that can help predict distance. The following are the basic visualizations that will help us understand more about the data and the variables:
- Scatter Plot – To help establish whether there exists a linear relationship between distance and speed.
- Box Plot – To check whether there are any outliers in the dataset.
- Density Plot – To check the distribution of the variables; ideally, it should be normally distributed.
Below are the steps to make these graphs in R.
Scatter Plots to visualize Relationship
A Scatter Diagram plots the pairs of numerical data with one variable on each axis, and helps establish the relationship between the independent and dependent variables.
Steps in R
If we carefully observe the scatter plot, we can see that the variables are correlated as they fall along the line/curve. The higher the correlation, the nearer the points, will be to the line/curve.
As discussed earlier, the Scatter Plot shows a linear and positive relationship between Distance and Speed. Thus, it fulfills one of the assumptions of Linear Regression i.e., there should be a positive and linear relationship between dependent and independent variables.
Check for Outliers using Boxplots.
A boxplot is also called a box and whisker plot that is used in statistics to represent the five number summaries. It is used to check whether the distribution is skewed or whether there are any outliers in the dataset.
Wikipedia defines ‘Outliers’ as an observation point that is distant from other observations in the dataset.
Now, let’s plot the Boxplot to check for outliers.
After observing the Boxplots for both Speed and Distance, we can say that there are no outliers in Speed, and there seems to be a single outlier in Distance. Thus, there is no need for the treatment of outliers.
Checking distribution of Data using Density Plots
One of the key assumptions to performing Linear Regression is that the data should be normally distributed. This can be done with the help of Density Plots. A Density Plot helps us visualize the distribution of a numeric variable over a period of time.
After looking at the Density Plots, we can conclude that the data set is more or less normally distributed.
Linear Regression Modelling
Now, let’s get into the building of the Linear Regression Model. But before that, there is one check we need to perform, which is ‘Correlation Computation’. The Correlation Coefficients help us to check how strong is the relationship between the dependent and independent variables. The value of the Correlation Coefficient ranges from -1 to 1.
A Correlation of 1 indicates a perfect positive relationship. It means if one variable’s value increases, the other variable’s value also increases.
A Correlation of -1 indicates a perfect negative relationship. It means if the value of variable x increases, the value of variable y decreases.
A Correlation of 0 indicates there is no relationship between the variables.
The output of the above R Code is 0.8068949. It shows that the correlation between speed and distance is 0.8, which is close to 1, stating a positive and strong correlation.
The linear regression model in R is built with the help of the lm() function.
The formula uses two main parameters:
Data – variable containing the dataset.
Formula – an object of the class formula.
The results show us the intercept and beta coefficient of the variable speed.
From the output above,
a) We can write the regression equation as distance = -17.579 + 3.932 (speed).
Model Diagnostics
Just building the model and using it for prediction is the job half done. Before using the model, we need to ensure that the model is statistically significant. This means:
- To check if there is a statistically significant relationship between the dependent and independent variables.
- The model that we built fits the data very well.
We do this by a statistical summary of the model using the summary() function in R.
The summary output shows the following:
- Call – The function call used to compute the regression model.
- Residuals – Distribution of residuals, which generally has a mean of 0. Thus, the median should not be far from 0, and the minimum and maximum should be equal in absolute value.
- Coefficients – It shows the regression beta coefficients and their statistical significance.
- Residual stand effort (RSE), R – Square, and F –Statistic – These are the metrics to check how well the model fits our data.
Detecting t-statistics and P-Value
T-Statistic and associated p-values are very important metrics while checking model fitment.
The t-statistics tests whether there is a statistically significant relationship between the independent and dependent variables. This means whether the beta coefficient of the independent variable is significantly different from 0. So, the higher the t-value, the better.
Whenever there is a p-value, there is always a null as well as an alternate hypothesis associated with it. The p-value helps us to test for the null hypothesis, i.e., the coefficients are equal to 0. A low p-value means we can reject the null hypothesis.
The statistical hypotheses are as follows:
Null Hypothesis (H0) – Coefficients are equal to zero.
Alternate Hypothesis (H1) – Coefficients are not equal to zero.
As discussed earlier, when the p-value < 0.05, we can safely reject the null hypothesis.
In our case, since the p-value is less than 0.05, we can reject the null hypothesis and conclude that the model is highly significant. This means there is a significant association between the independent and dependent variables.
R – Squared and Adjusted R – Squared
R – Squared (R2) is a basic metric which tells us how much variance has been explained by the model. It ranges from 0 to 1. In Linear Regression, if we keep adding new variables, the value of R – Square will keep increasing irrespective of whether the variable is significant. This is where Adjusted R – Square comes to help. Adjusted R – Square helps us to calculate R – Square from only those variables whose addition to the model is significant. So, while performing Linear Regression, it is always preferable to look at Adjusted R – Square rather than just R – Square.
- An Adjusted R – Square value close to 1 indicates that the regression model has explained a large proportion of variability.
- A number close to 0 indicates that the regression model did not explain too much variability.
In our output, Adjusted R Square value is 0.6438, which is closer to 1, thus indicating that our model has been able to explain the variability.
AIC and BIC
AIC and BIC are widely used metrics for model selection. AIC stands for Akaike Information Criterion, and BIC stands for Bayesian Information Criterion. These help us to check the goodness of fit for our model. For model comparison model with the lowest AIC and BIC is preferred.
Which Regression Model is the best fit for the data?
There are number of metrics that help us decide the best fit model for our data, but the most widely used are given below:
| Statistics | Criterion |
| R – Squared | Higher the better |
| Adjusted R – Squared | Higher the better |
| t-statistic | Higher the t-values lower the p-value |
| f-statistic | Higher the better |
| AIC | Lower the better |
| BIC | Lower the better |
| Mean Standard Error (MSE) | Lower the better |
Predicting Linear Models
Now we know how to build a Linear Regression Model In R using the full dataset. But this approach does not tell us how well the model will perform and fit new data.
Thus, to solve this problem, the general practice in the industry is to split the data into the Train and Test datasets in the ratio of 80:20 (Train 80% and Test 20%). With the help of this method, we can now get the values for the test dataset and compare them with the values from the actual dataset.
Splitting the Data
We do this with the help of the sample() function in R.
Building the model on Train Data and Predict on Test Data
Model Diagnostics
If we look at the p-value, since it is less than 0.05, we can conclude that the model is significant. Also, if we compare the Adjusted R – Squared value with the original dataset, it is close to it, thus validating that the model is significant.
K – Fold Cross-Validation
Now, we have seen that the model performs well on the test dataset as well. But this does not guarantee that the model will be a good fit in the future as well. The reason is that there might be a case that a few data points in the dataset might not be representative of the whole population. Thus, we need to check the model performance as much as possible. One way to ensure this is to check whether the model performs well on train and test data chunks. This can be done with the help of K – Fold Cross-validation.
The procedure of K – Fold Cross-validation is given below:
- The random shuffling of the dataset.
- Splitting of data into k folds/sections/groups.
- For each fold/section/group:
- Make the fold/section/group the test data.
- Take the rest data as train data.
- Run the model on train data and evaluate the test data.
- Keep the evaluation score and discard the model.
After performing the K – Fold Cross-validation, we can observe that the R – Square value is close to the original data, as well, as MAE is 12%, which helps us conclude that model is a good fit.
Advantages of Using Linear Regression
- The linear Regression method is very easy to use. If the relationship between the variables (independent and dependent) is known, we can easily implement the regression method accordingly (Linear Regression for linear relationship).
- Linear Regression provides the significance level of each attribute contributing to the prediction of the dependent variable. With this data, we can choose between the variables which are highly contributing/ important variables.
- After performing linear regression, we get the best fit line, which is used in prediction, which we can use according to the business requirement.
Limitations of Linear Regression
The main limitation of linear regression is that its performance is not up to the mark in the case of a nonlinear relationship. Linear regression can be affected by the presence of outliers in the dataset. The presence of high correlation among the variables also leads to the poor performance of the linear regression model.
Linear Regression Examples
- Linear Regression can be used for product sales prediction to optimize inventory management.
- It can be used in the Insurance domain, for example, to predict the insurance premium based on various features.
- Monitoring website click count on a daily basis using linear regression could help in optimizing the website efficiency etc.
- Feature selection is one of the applications of Linear Regression.
Linear Regression – Learning the Model
- Simple Linear Regression
With simple linear regression, when we have a single input, we can use statistics to estimate the coefficients.
This requires that you calculate statistical properties from the data, such as mean, standard deviation, correlation, and covariance. All of the data must be available to traverse and calculate statistics.
- Ordinary Least Squares
When we have more than one input, we can use Ordinary Least Squares to estimate the values of the coefficients.
The Ordinary Least Squares procedure seeks to minimize the sum of the squared residuals. This means that given a regression line through the data, we calculate the distance from each data point to the regression line, square it, and sum all of the squared errors together. This is the quantity that ordinary least squares seek to minimize.
- Gradient Descent
This operation is called Gradient Descent and works by starting with random values for each coefficient. The sum of the squared errors is calculated for each pair of input and output values. A learning rate is used as a scale factor, and the coefficients are updated in the direction of minimizing the error. The process is repeated until a minimum sum squared error is achieved or no further improvement is possible.
When using this method, you must select a learning rate (alpha) parameter that determines the size of the improvement step to take on each iteration of the procedure.
- Regularization
There are extensions to the training of the linear model called regularization methods. These seek to minimize the sum of the squared error of the model on the training data (using ordinary least squares) and also to reduce the complexity of the model (like the number or absolute size of the sum of all coefficients in the model).
Two popular examples of regularization procedures for linear regression are:
– Lasso Regression: where Ordinary Least Squares are modified also to minimize the absolute sum of the coefficients (called L1 regularization).
– Ridge Regression: where Ordinary Least Squares are modified also to minimize the squared absolute sum of the coefficients (called L2 regularization).
Preparing Data for Linear Regression
Linear regression has been studied at great length, and there is a lot of literature on how your data must be structured to best use the model. In practice, you can use these rules more like rules of thumb when using Ordinary Least Squares Regression, the most common implementation of linear regression.
Try different preparations of your data using these heuristics and see what works best for your problem.
- Linear Assumption
- Noise Removal
- Remove Collinearity
- Gaussian Distributions
Summary
In this post, you discovered the linear regression algorithm for machine learning.
You covered a lot of ground, including:
- The common names used when describing linear regression models.
- The representation used by the model.
- Learning algorithms are used to estimate the coefficients in the model.
- Rules of thumb to consider when preparing data for use with linear regression.
Try out linear regression and get comfortable with it. If you are planning a career in Machine Learning, here are some Must-Haves On Your Resume and the most common interview questions to prepare.
Find Machine Learning Course in Top Indian Cities
Chennai | Bangalore | Hyderabad | Pune | Mumbai | Delhi NCROur Machine Learning Courses
Explore our Machine Learning and AI courses, designed for comprehensive learning and skill development.
| Program Name | Duration |
|---|---|
| MIT No code AI and Machine Learning Course | 12 Weeks |
| MIT Data Science and Machine Learning Course | 12 Weeks |
| Data Science and Machine Learning Course | 12 Weeks |




