By: Prof. Mukesh Rao (Senior Faculty, Academics, Great Learning)
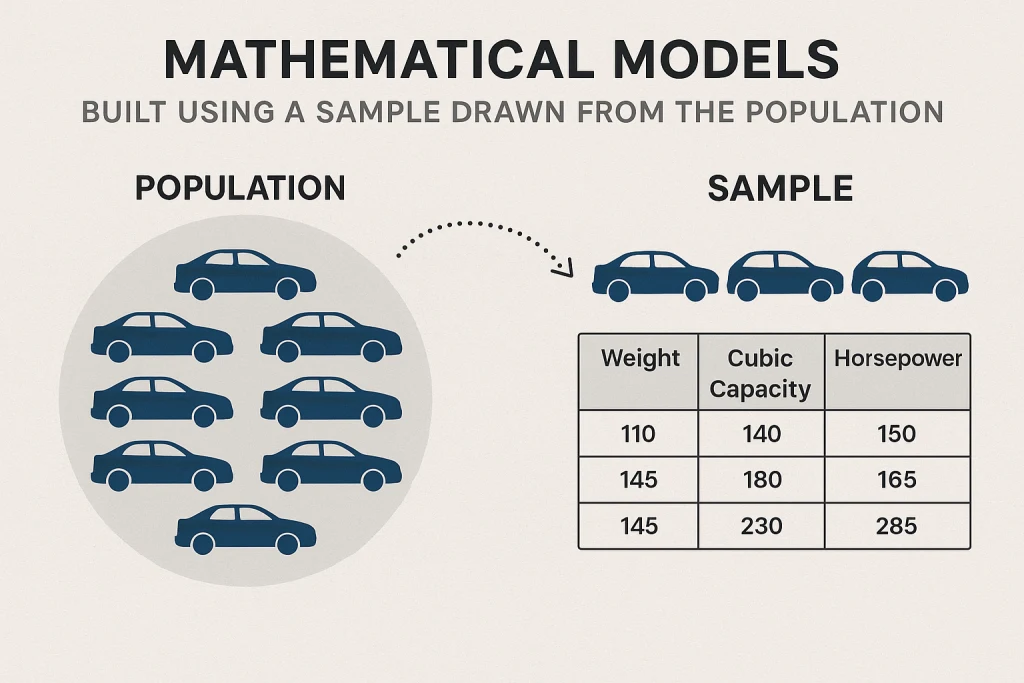
Mathematical models are built using sample data drawn from the population. In the context of data science, the population refers to the production environment where data is being generated continuously. Each data point usually consists of multiple attributes.
For example, in a car manufacturing unit, each car manufactured is a data point with specific attributes, such as weight, cubic capacity, and horsepower. The entire collection of data points representing all cars manufactured to date is the population.
The population data is always growing and dynamic. New data points will continue to be added to the population with every car manufactured, and sometimes new attributes are introduced or old ones become less relevant.
The Concept of Population and Sample
To mathematically model the process generating the data, a sample of data is drawn from the population. The sample may consist of all the attributes or a subset of attributes and data points. The sample is essentially a snapshot of a subset of the population.
The larger the sample size, in terms of both the number of data points and the attributes, the more reliable the model is likely to be. However, it is important to note that the sample can never truly represent the population.
Difference Between Population and Sample
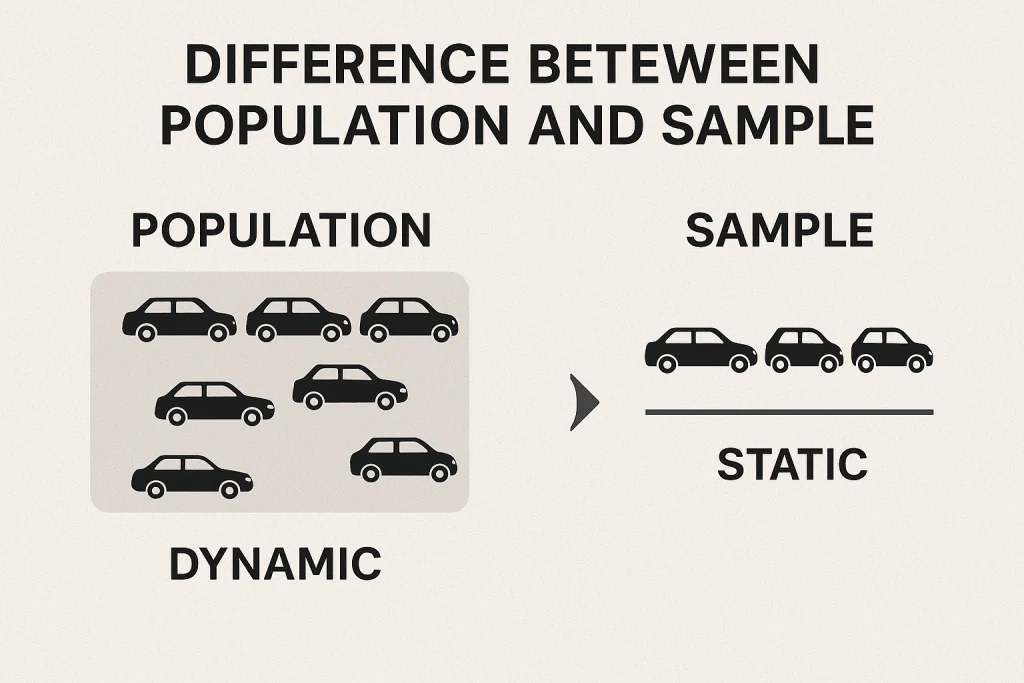
The key difference between a population and a sample is that the population is dynamic, while the sample is static. The population is continually evolving, and new data points with potentially new attributes are added.
On the other hand, the sample is a fixed snapshot of the population at a given point in time. The sample is expected to have the same distribution characteristics as the population because it is drawn from the population.
However, due to the sampling process, there may be slight differences in the distribution characteristics between the sample and the population. These differences are typically insignificant, but it is essential to test for reliability before building any models.
Establishing the Reliability of Sample Data
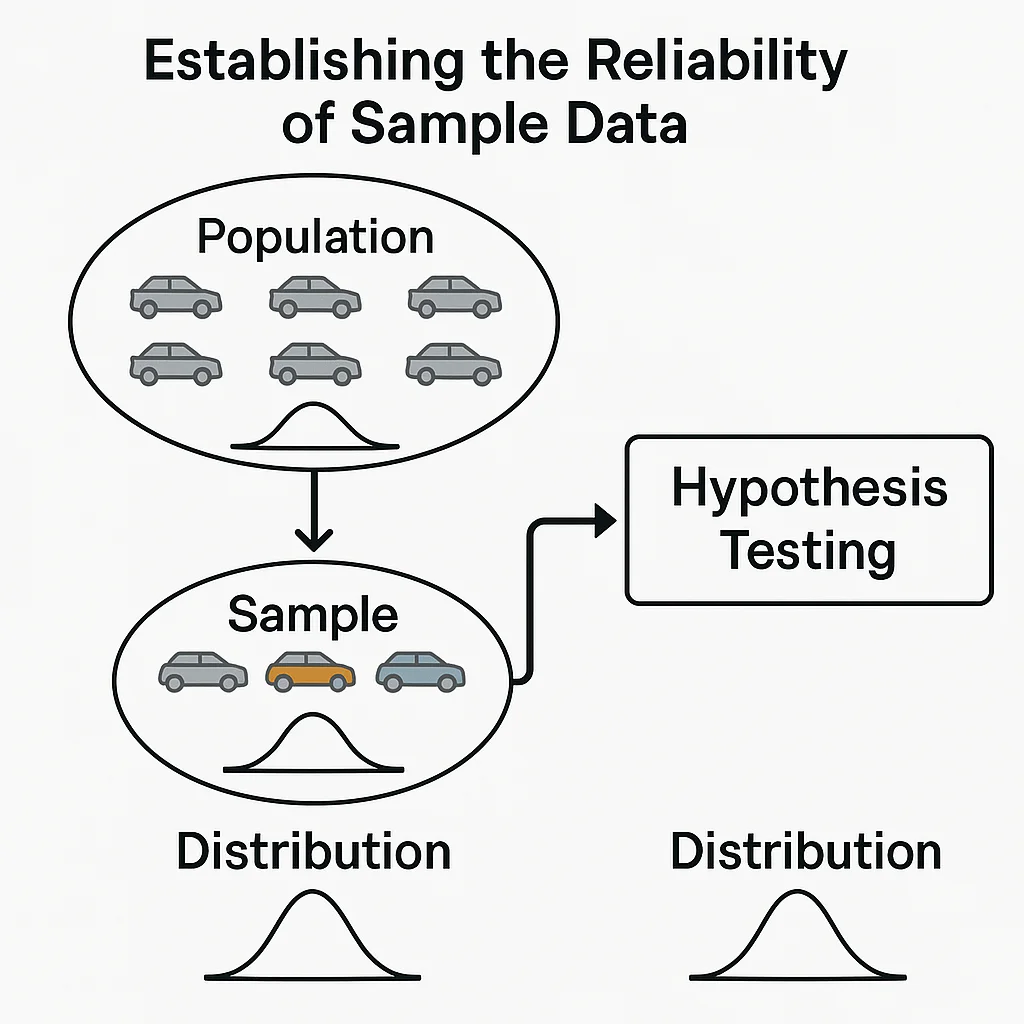
A sample can never fully represent the population, which is why it is necessary to statistically validate that the sample represents the population before using it for model construction. Hypothesis testing helps assess the reliability of the sample by comparing its statistical distribution characteristics to those of the population.
If the sample's distribution characteristics match those of the population, it is considered reliable for modeling purposes. If there are significant differences, the sample may belong to a different process, and the model built on it could fail when applied to the population.
Understanding the difference between population and sample is critical for building accurate statistical models. Since models are based on samples drawn from dynamic populations, it is essential to establish the reliability of the sample before proceeding with the model-building process. Statistical tests, such as hypothesis testing, are crucial to ensure that the sample is an adequate representation of the population.