The best first search uses the concept of a priority queue and heuristic search. It is a search algorithm that works on a specific rule. The aim is to reach the goal from the initial state via the shortest path.
The best First Search algorithm in artificial intelligence is used for for finding the shortest path from a given starting node to a goal node in a graph.
In this blog, we'll explore what Best First Search Algorithm in AI is and how the algorithm works by expanding the nodes of the graph.
Contributed by: Rana Banerjee
Introduction to search algorithms
Search algorithms are crucial to these AI programs. While commonly associated with games and puzzles, these algorithms are also integral to broader AI applications such as route optimization, action planning, robotics, and more.
Essentially, many AI challenges are search problems where the goal is to find the most efficient path from an initial state to a goal state using specific rules.
There are two main types of search methods:
- Uninformed Search: This method, also known as blind or exhaustive search, does not use additional information and includes techniques like Breadth-First Search and Depth First Search.
- Informed Search: These methods use extra information to decide the next steps. They are more cost-effective and efficient than uninformed methods
Informed search methods are more efficient, low in cost and high in performance as compared to uninformed search methods.
What is Best First Search?
If we consider searching as a form of traversal in a graph, an uninformed search algorithm would blindly traverse to the next node in a given manner without considering the cost associated with that step.
An informed search, like BFS, on the other hand, would use an evaluation function to decide which among the various available nodes is the most promising (or ‘BEST’) before traversing to that node.
BFS uses the concept of a Priority queue and heuristic search. To search the graph space, the BFS method uses two lists for tracking the traversal. An ‘Open’ list that keeps track of the current ‘immediate’ nodes available for traversal and a ‘CLOSED’ list that keeps track of the nodes already traversed.
MIT Data Science and Machine Learning Course
Unlock the power of data. Build hands-on data science and machine learning skills to drive innovation in your career.
Best First Search vs. Breadth-First Search: Clearing the Confusion
Because both algorithms share the "BFS" acronym, beginners often mix them up. However, they function very differently. When developers refer to BFS, they are almost always talking about Breadth-First Search. Best First Search is typically referred to as Greedy BFS to avoid this exact confusion.
| Feature | Breadth-First Search (Standard BFS) | Best First Search (Greedy BFS) |
| Search Category | Uninformed Search (Blind Search) | Informed Search (Heuristic Search) |
| Core Mechanism | Explores the graph level-by-level, checking all neighbor nodes before going deeper. | Explores the most "promising" node first based on an estimated distance to the goal. |
| Data Structure | Queue (FIFO - First In, First Out) | Priority Queue (Min-Heap based on heuristic value) |
| Use of Heuristics | Does not use any heuristic or cost estimates. Explores blindly. | Uses a heuristic function, h(n), to estimate the distance to the target. |
| Completeness | Complete: It will always find a solution if one exists. | Incomplete: It can get stuck in dead ends or infinite loops without a good heuristic. |
| Optimality | Optimal: Always finds the shortest path (if all edge weights are equal). | Not Optimal: May find a quick path, but it is not guaranteed to be the absolute shortest. |
| Speed & Efficiency | Slower and highly memory-intensive for large graphs, as it evaluates all possible paths equally. | Generally much faster, as the heuristic guides it directly toward the goal, skipping irrelevant nodes. |
Best First Search Algorithm
Best First Search (BFS) follows a graph by using a priority queue and heuristics. It keeps an 'Open' list for nodes that need exploring and a 'Closed' list for those already checked. Here’s how it operates:
- Create 2 empty lists: OPEN and CLOSED
- Start from the initial node (say N) and put it in the ‘ordered’ OPEN list
- Repeat the next steps until the GOAL node is reached
- If the OPEN list is empty, then EXIT the loop returning ‘False’
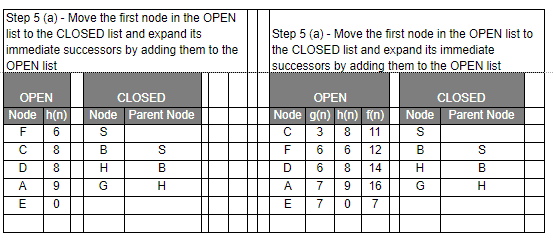
- Select the first/top node (say N) in the OPEN list and move it to the CLOSED list. Also, capture the information of the parent node
- If N is a GOAL node, then move the node to the Closed list and exit the loop returning ‘True’. The solution can be found by backtracking the path
- If N is not the GOAL node, expand node N to generate the ‘immediate’ next nodes linked to node N and add all those to the OPEN list
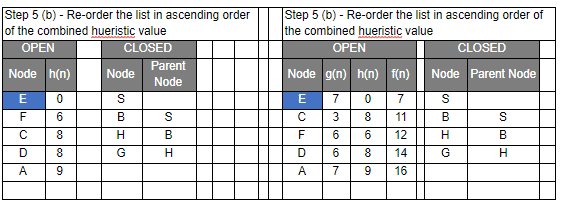
- Reorder the nodes in the OPEN list in ascending order according to an evaluation function f(n)
This algorithm will traverse the shortest path first in the queue.
Time and Space Complexity of Best First Search
The performance of the Best First Search algorithm depends heavily on the accuracy of the heuristic function. In the worst-case scenario (where the heuristic is poor and guides the search down a long, incorrect path), it behaves similarly to an uninformed Depth-First Search.
| Metric | Complexity | Explanation |
|---|---|---|
| Time Complexity | O(bd) | Where b is the branching factor, and d is the depth. In the worst case, it may expand all nodes in the tree. A good heuristic drastically reduces this. |
| Space Complexity | O(bd) | Since Best First Search maintains a priority queue (OPEN list) of all generated nodes, memory consumption can be very high in the worst case. |
Best First Search Implementation in Python
Below is a practical implementation of the Greedy Best First Search algorithm using Python. It utilizes a priority queue to always expand the node with the lowest heuristic value first.from queue import PriorityQueue
# Graph represented as an adjacency list
# graph[node] = [(cost, adjacent_node), ...]
def best_first_search(source, target, graph, heuristics):
visited = set()
pq = PriorityQueue()
# Priority Queue stores tuples of (heuristic_value, node)
pq.put((heuristics[source], source))
visited.add(source)
path = []
while not pq.empty():
_, current_node = pq.get()
path.append(current_node)
# Check if we have reached the target
if current_node == target:
print("Path found:", " -> ".join(path))
return True
# Explore neighbors
for cost, neighbor in graph.get(current_node, []):
if neighbor not in visited:
visited.add(neighbor)
pq.put((heuristics[neighbor], neighbor))
print("Target not reachable.")
return False
# Example Data
heuristics = {'S': 10, 'A': 8, 'B': 5, 'C': 7, 'D': 3, 'G': 0}
graph = {
'S': [(3, 'A'), (2, 'B')],
'A': [(4, 'C'), (3, 'D')],
'B': [(5, 'D'), (6, 'G')],
'C': [(2, 'G')],
'D': [(1, 'G')]
}
print("Best First Search Traversal:")
best_first_search('S', 'G', graph, heuristics)
Variants of Best First Search
The two variants of BFS are Greedy Best First Search and A* Best First Search. Greedy BFS makes use of the Heuristic function and search and allows us to take advantage of both algorithms.
There are various ways to identify the ‘BEST’ node for traversal and accordingly there are various flavours of BFS algorithm with different heuristic evaluation functions f(n). We will cover the two most popular versions of the algorithm in this blog, namely Greedy Best First Search and A* Best First Search.
- Greedy Best First Search: Uses only a heuristic function h(n) to estimate the direct distance from the current node to the goal. Prioritizes nodes that seem closest to the goal.
- A Best First Search*: Combines the heuristic function h(n) with the actual travel cost g(n) from the start. The evaluation function 𝑓(𝑛)=𝑔(𝑛)+ℎ(𝑛) balances direct distance and travel cost for optimal pathfinding.
How They Work:
As you travel from one node (city) to the next, both methods calculate the next best node to visit based on different criteria.
- Greedy BFS: Focuses on the estimated distance to the goal, which may not reflect actual road conditions like curves or hills.
- A Search*: Considers both the estimated distance and the actual distance traveled, leading to more accurate and efficient route planning.
Example Application:
If traveling from city S to city E, both algorithms will suggest routes but with different considerations:
- Greedy BFS: Chooses the next city based purely on which seems closest to city E according to the heuristic.
- A Search*: Selects the next city by minimizing the sum of both the travel cost so far and the estimated distance to the goal.
Evaluation Function Differences:
- Greedy BFS: 𝑓(𝑛)=ℎ(𝑛) focuses only on heuristic distance.
- A Search*: 𝑓(𝑛)=𝑔(𝑛)+ℎ(𝑛) integrates both travel cost and heuristic distance for a more balanced and potentially shorter route.
Each variant has its specific use case, with A* being generally more reliable for complex pathfinding due to its comprehensive evaluation of both cost and distance.
Best First Search Example
Let’s have a look at the graph below and try to implement both Greedy BFS and A* algorithms step by step using the two list, OPEN and CLOSED.
| g(n) | Path Distance |
| h(n) | Estimate to Goal |
| f(n) | Combined Hueristics i.e. g(n) + h(n) |
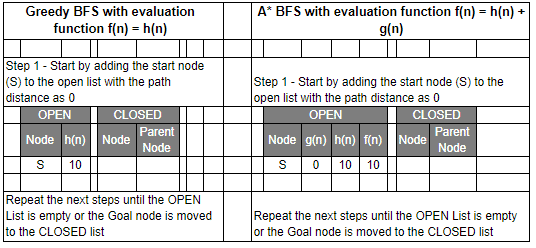
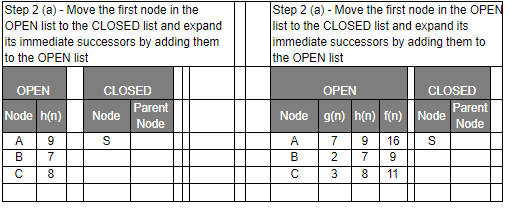
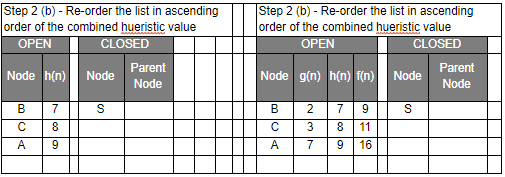
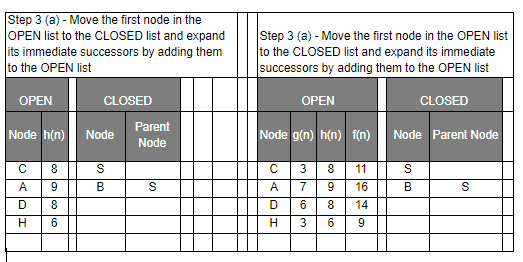
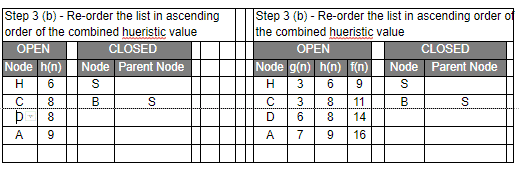
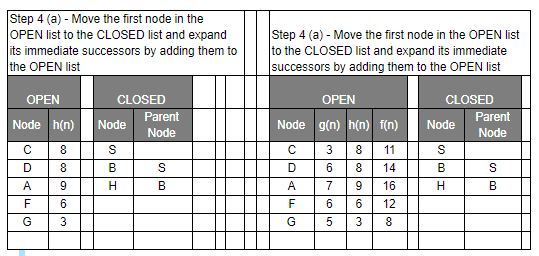
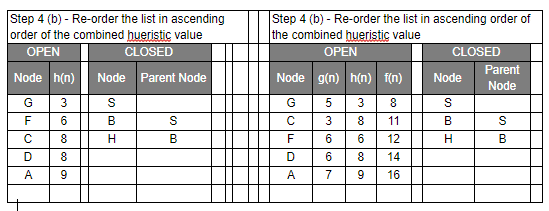
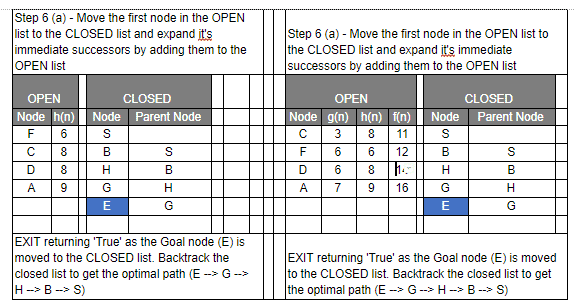
Even though you would find that both Greedy BFS and A* algorithms find the path equally efficiently, a number of steps, you may notice that the A* algorithm is able to come up with is a more optimal path than Greedy BFS. So in summary, both Greedy BFS and A* are the Best first searches but Greedy BFS is neither complete nor optimal whereas A* is both complete and optimal. However, A* uses more memory than Greedy BFS, but it guarantees that the path found is optimal.
Aspiring to be an AI and ML pro?
Don't miss out on the insights in "How to Start a Career in Artificial Intelligence and Machine Learning?"
PG Program in AI & Machine Learning
Master AI with hands-on projects, expert mentorship, and a prestigious certificate from UT Austin and Great Lakes Executive Learning.
Advantages and Disadvantages of Best First Search
Advantages:
1. Can switch between BFS and DFS, thus gaining the advantages of both.
2. More efficient when compared to DFS.
Disadvantages:
1. Chances of getting stuck in a loop are higher.
Also check out our blog on "Advantages and Disadvantages of Artificial Intelligence" to explore the multifaceted aspects of artificial intelligence!
Conclusion
While there are ample resources available online to help you understand the subject, there’s nothing quite like a certificate. Check out Great Learning’s PG program in Artificial Intelligence and Machine Learning to upskill in the domain. This course will help you learn from a top-ranking global school to build job-ready AIML skills. Also, don’t forget to check out popular free Artificial Intelligence courses to upskill in the domain.
If you're interested in expanding your skills beyond Best First Search, consider exploring free courses with certificate to access a range of learning opportunities in various subjects.
FAQS
Best First Search (BFS) is an algorithm used in AI to find the most efficient path through a graph. It prioritizes nodes based on a heuristic that estimates the best path to the goal.
BFS works by using a priority queue to explore the most promising node first, based on a heuristic value. It maintains two lists: an 'Open' list for nodes yet to be explored and a 'Closed' list for nodes that have been examined.
The key components include the priority queue for managing node exploration, the heuristic that estimates cost to the goal, and the 'Open' and 'Closed' lists to track exploration progress.
The main variants are Greedy Best First Search, which uses only the heuristic to guide the search, and A* Search, which combines the heuristic with the cost from the start to a node.
BFS is advantageous in scenarios where you need to find an efficient path through a large search space, such as in route finding, scheduling tasks, and game AI.
BFS can be less efficient if the heuristic is not accurate, leading to unnecessary exploration. Additionally, Greedy BFS may not always find the shortest path, focusing only on the nearest to the goal.
Unlike other search algorithms like Depth-First Search or Breadth-First Search, BFS uses heuristics to make informed decisions about which node to explore next, potentially reducing the number of nodes it needs to examine.