Deep Learning Basics
Deep Learning, a subset of machine learning has taken over the world as a leading technology today. It imitates the complex functionalities of the human brain to use unstructured data to decipher meaning and teach machines. From industries like automotive, healthcare, security, to content creation, the applications of deep learning are many and on the rise.
If you are an interested candidate who is keen on learning more about the domain, check out this free deep learning course. And, if you are already well-versed in this technology and looking for job opportunities in this field.
Deep Learning Interview Questions for Freshers
1. What is Deep Learning?
Deep learning is a machine learning technology that involves neural networks. The term ‘deep’ in deep learning refers to the hierarchical structure of the networks used to teach computers natural human actions.
It is commonly used in medical research, driverless cars, and other cases where precision and accuracy are important.
2. What is the difference between deep learning, machine learning and AI?
Both Deep Learning and Machine Learning are part of Artificial intelligence and the difference between all the three domains is really just about the specificities. While deep learning deals with neural networks attempting to train machines through several layers of logic, machine learning is all about algorithms which uses historical data to teach machines. Artificial intelligence, of course, is the broader term which refers to any method which helps machines to mimic basic human actions.
3. What is the difference between supervised and unsupervised deep learning?
Supervised learning refers to the learning method which trains machines through labelled data. This data is already categorised and tagged to the correct set of answers. When a machine is fed this data, it analyses the training set and produces the correct result.
Unsupervised learning, on the other hand, does not require the data to be labelled. Machines self-learn from identifying patterns and model data according to probability densities.
4. What are data visualisation libraries?
Data visualisation libraries help in understanding complex ideas by using visual elements such as graphs, charts, maps and more. The visualisation tools help you to recognise patterns, trends, outliers and more, making it possible to design your data according to the requirement. Popular data visualisation libraries include D3, React-Vis, Chart.js, vx, and more.
5. What is overfitting?
Overfitting is a type of modelling error which results in the failure to predict future observations effectively or fit additional data in the existing model. It occurs when a function is too closely fit to a limited set of data points and usually ends with more parameters than the data can accommodate. It is common for huge data sets to have some anomalies, so when this data is used for any kind of modelling, it can result in inaccuracies in the analysis.
Also Read: Top Deep Learning Tools

6. How to prevent overfitting?
Overfitting can be prevented by following a few methods namely-
- Cross-validation: Where the initial training data is split into several mini-test sets and each mini data set is used to tune the model.
- Remove features: Remove irrelevant features manually from the algorithms and use feature selection heuristics to identify the important features
- Regularisation: This involves various ways of making your model simpler so that there’s little room for error due to obscurity. Adding penalty parameters and pruning your decision tree are ways of doing that.
- Ensembling: These are machine learning techniques for combining multiple separate predictions. The most popular methods of ensembling are bagging and boosting.
7. How are Deep networks better than shallow networks?
Neural networks include hidden layers apart from input and output layers. Shallow neural networks use a single hidden layer between the input and output layers whereas Deep neural networks, use multiple layers. For a shallow network to fit into any function, it needs to have a lot of parameters. However, since deep networks have several layers, it can fit functions better even with a limited number of parameters. Today deep networks have become preferable owing to its ability to work on any kind of data modelling, whether it is for voice or image recognition.
8. What is Perceptron? And how does it work?
Perceptron is a machine learning algorithm which came to exist from the 1950s. It is a single layer neural network with a linear classifier to work on a set of input data. Since perceptron uses classified data points which are already labelled, it is a supervised learning process.
Perceptron algorithms often present visual charts for users where output datasets are processed to provide the required output. The input data goes through an iterative loop to teach machines. This loop not only iterates but also evolves every time a dataset is fed to the machine. The algorithm improvises its output based on its findings each time so that after a period of time, the output data is more sophisticated and accurate.

9. What is Multilayer Perceptron and Boltzmann Machine?
Similar to single layer perceptron, multilayer perceptrons have input, output and hidden layers. However, since MLPs have more than one hidden layer, they are capable of classifying non-linear classes. Each node in the hidden layers uses a nonlinear activation function along with the input layers to produce the output through ‘backpropagation’. In this method, the neural networks calculate the errors using cost function and pushes the error backwards to the source to train the model more accurately.
The Boltzmann machine is a simplified version of the multilayer perceptron. This is a two layer model with a visible input layer and a hidden layer which makes stochastic decisions for the neurons. The nodes of this model are connected across layers without being connected to each other.
10. What are activation functions and its types?
Activation functions introduce non-linear properties to our network, allowing it to learn more complex functions. The main purpose of an activation function is to convert an input signal of a node in an A-NN to an output signal. This output signal is then used as an input in the next layer in the stack. To get the output of that layer and feed it as an input to the next layer, we must take the sum of the products of the inputs (x) and their corresponding weights (w) and apply the activation function f(x) to it, in an A-NN.
There are various types of activation functions, such as-
Linear or Identity,
Unit or Binary Step,
Sigmoid or Logistic,
Tanh,
ReLU, and
Softmax.
11. What is inductive reasoning machine learning?
Inductive reasoning focuses as much on the conclusion as the premises and treats the conclusion as part of the reasoning to justify any behaviour. Also known as the ‘cause and effect reasoning’, inductive reasoning tries to prove a conclusion by backtracing to the inputs and picks up that logic as part of its learning.
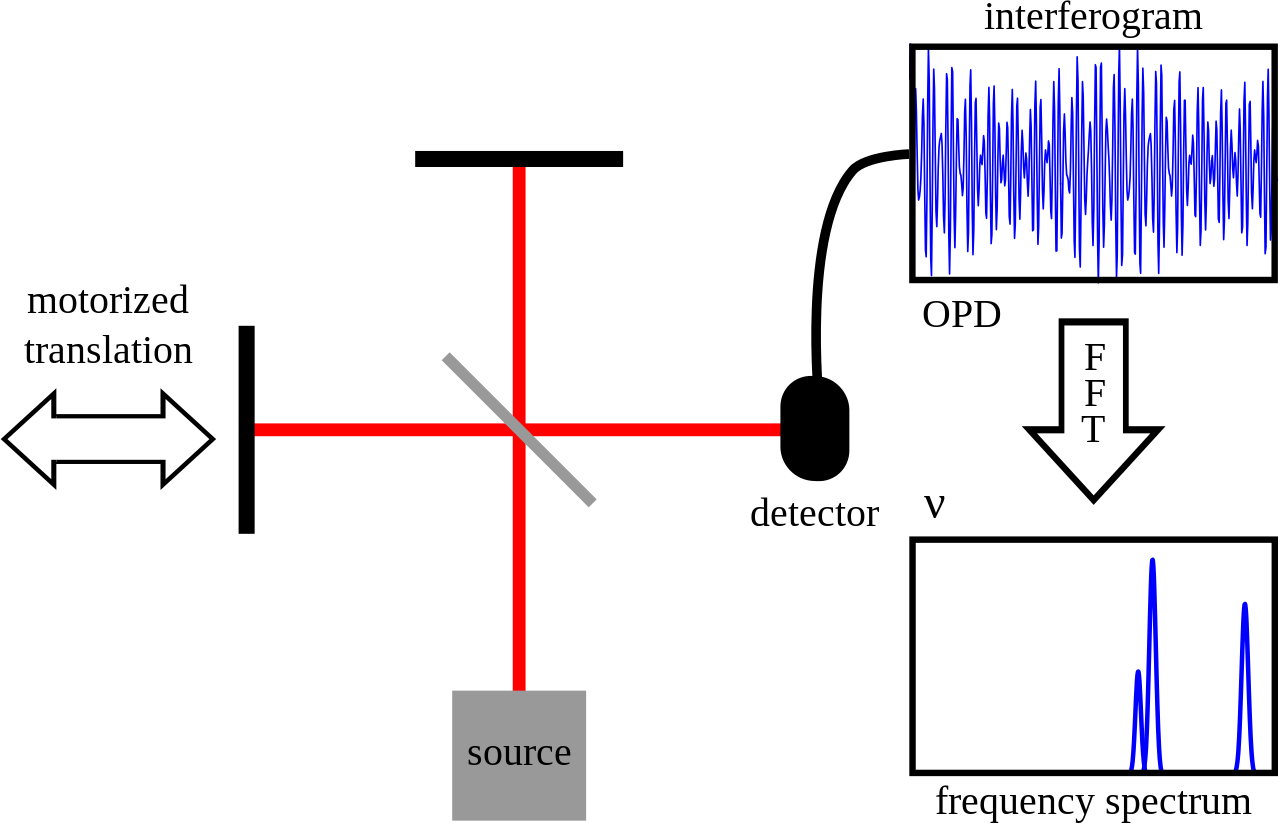
12. What is the use of Fourier Transform in Deep Learning?
Fourier transform is used in machine learning to process signals. The fourier series is a method of breaking down signals into frequency components. It is applicable to non-periodic signals such as a delta function and enables such signals to be measured in terms of frequencies instead of time. Fourier transform is useful when you are working on a system where the transfer function is known.
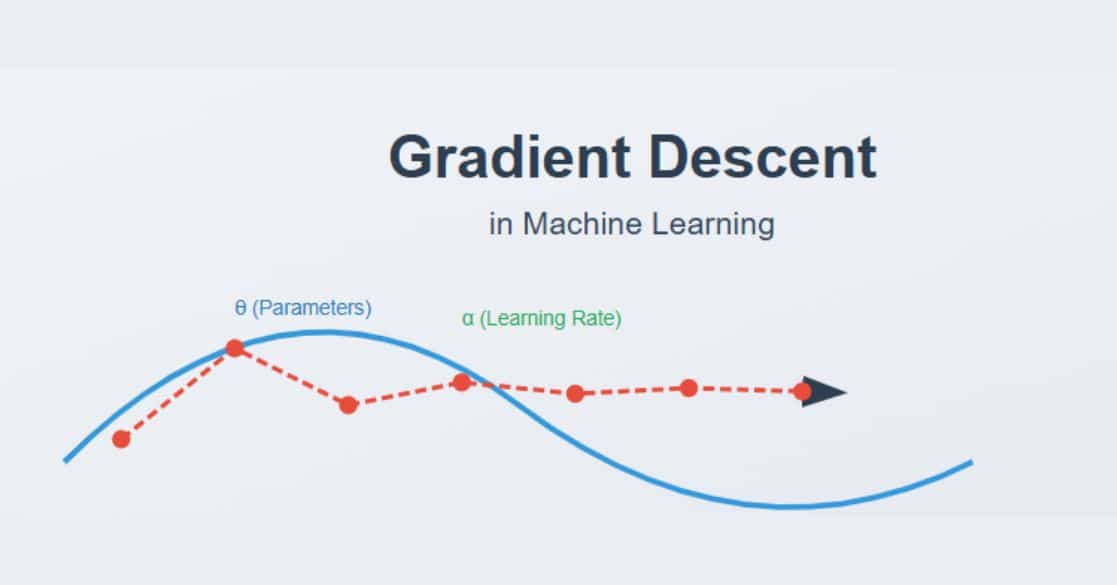
13. What is gradient descent? What are the steps for using a gradient descent algorithm?
An optimization algorithm which is used to learn the value of parameters that minimize cost function is known as a gradient descent. It is an iterative algorithm and moves in the direction of steepest descent. It is defined by the negative of the gradient. It was first proposed in 1847 by Augustin-Louis Cauchy. The steps involved in using a gradient descent algorithm are as follows-
-Initialize a random weight and bias
-Pass an input through the network and get the value from the output layer
-Calculate if there is an error between the actual value and the predicted value
-Go to each neuron which is contributing to the error and change its respective value so that the error is reduced
-Reiterate the steps until the best weights of the network are found
14. What are the benefits of mini-batch gradient descent?
Mini-batch gradient descent, a variation of the gradient descent algorithm, splits any training dataset into small batches to study data model errors and update accordingly. It is the most commonly used gradient descent used for deep learning.
The benefits of using a mini-batch gradient descent is that it allows a more robust convergence without involving the local minima. Even computationally, it is more efficient than other gradient descents (stochastic and batch gradient descents). Mini-batching can work even with zero training data in memory and algorithm implementation.
15. What are Vanishing and Exploding gradients?
Vanishing gradient occurs when backpropagation does not function properly while training the neural networks. In such cases, the network parameters and hyperparameters do not match resulting in the slope becoming too small and decreasing.
In the case of an exploding gradient, there is a significant increase in the norm of the gradient during training. This results in unstable networks that are unable to learn from the training data, especially when the input has a long series of data.
16. What is the difference between Epoch, Batch, and Iteration?
Epoch, iteration and batch are different types of processing datasets and algorithms for gradient descent. Epoch is the process of passing an entire dataset forward and backward through a neural network just once. Often the dataset is too big to be passed in a single attempt so it is passed several times to generate accurate results. When this happens, i.e., a limited set of data is passed through a neural network several times, it is known as an iterative process. However, if the data set is broken down into a number of batches or subsets to ensure it passes through the neural networks successfully, it is known as batch. All the three methods, i.e., epoch, iteration and batch size are basically ways of working on the gradient descent depending on the size of the data set.

17. How to choose the appropriate formula to solve issues on classification?
Choosing the right metrics and formula to classify your data is extremely important for understanding and optimising the model. Use a model evaluation procedure to choose between different model types, features and tuning parameters. Train and test these models on the same set of data, split-test the models or cross-validate the models by comparing average results with test split results.
18. What is backpropagation?
A training algorithm which is used for a multilayer neural network is known as backpropagation. In backpropagation, the error is moved from the end of the network to all weights, thus allowing efficient computing of the gradient. It is typically divided into several steps, such as-
-Forward propagation of the training data so that the output is generated.
-By using the target value and the output value, error derivative can be computed. (with respect to output activation)
-We then propagate for computing the derivative of the error (with respect to output activation) and continue to do so for all of the hidden layers.
-By using the previously calculated derivatives, we can calculate error derivatives with respect to the weights.
-Update the weights.
19. What are hyperparameters?
Hyperparameters are created from prior observation before a dataset is captured and used in deep learning algorithms to train a model. Hyperparameters need to be initialised before training a model. The benefits of using hyperparameters are that they can control the behaviour of a training model and impact its performance significantly.
Hyperparameters can be optimised by Grid search, Random search, and Bayesian optimisation. Choosing good hyperparameters ensure easy management of large datasets.
20. What is underfitting and how can it be prevented?
When a model cannot train data or generalise new data, it is referred to as underfitting.
If a model has a good performance metric, it is easy to detect the error. In the case of underfitting, the model does not learn enough and is incapable of predicting correct results.
Underfitting can be prevented by using more training data, adding dropouts, reducing the capacity of networks and regularising weight.
21. What are Recurrent Neural Networks?
Recurrent Neural Networks are neural networks which uses the output from the previous step as inputs for the current step. Unlike a traditional neural network, where the inputs and outputs are independent of each other, in a recurrent neural network, the preceding outputs are crucial to decide the next. It features a hidden layer which carries data regarding a sequence.
22. What are the different layers of a convoluted neural network?
The different types of layers of a CNN include:
- Convolutional Layer: This is the core layer which has sets of learnable filters with receptive field. This is the first layer which extracts features from the input data.
- ReLU Layer: This layer converts negative pixels to zero by making the networks non-linear.
- Pooling Layer: This layer progressively reduces the spatial size of the representation by reducing computation and parameters in the network. The most common approach of pooling is max pooling.
23. What is the most preferred library in Deep Learning and why?
Tensorflow is the most preferred library in deep learning.
Tensorflow provides high flexibility owing to its low-level structure. It can fit into any kind of functionality for any model. Tensorflow is popular among researchers as it can be changed according to the requirement and control networks better.
24. What do you understand by Tensors?
Tensors are multidimensional arrays which allow us to represent data that have a higher dimension. Deep learning deals with high dimensional datasets. Here, dimensions refer to the various features that are present in the dataset.
25. What are deep autoencoders?
Two symmetrical deep-belief networks which typically have four or five shallow layers that represent the encoding half of the net and a second set of four or five layers that represent the decoding half are together known as deep autoencoder. These layers are restricted Boltzmann machines and the building blocks of deep belief networks.
To process the dataset MNIST, a deep autoencoder uses binary transformations after each RBM. They can also be used for other datasets on which you would use Gaussian rectified transformations instead of the RBM.
26. What is the ultimate use of Deep learning in today’s age and how is it aiding data scientists?
Deep learning is used for a number of cases including language recognition, self-driving cars, text generation, video and image editing and more. However, the most important use of deep learning is perhaps in the field of computer vision where computers are fed relevant data to learn object detection, image restoration and segmentation, medical diagnostics, monitoring crops and livestock, and more. Scientists are using deep learning across industries to automate surveillance-based and repetitive tasks to improve productivity and accuracy.
27. What are the benefits of supervised learning procedure?
With supervised learning, you can train the classifier perfectly so that it has a perfect decision boundary. Specific definitions of the classes helps machines distinguish between various classes accurately. Once the training is completed, the decision boundary can be reused for the mathematical formula, instead of the training data. Supervised learning is especially helpful for predictions on data with numerical values.
28. How does unsupervised learning aid in deep learning?
Unsupervised learning has been heralded as the future of deep learning. It actually mimics how humans learn. The biggest advantage of using this method is that unlike supervised learning, unsupervised can scaled up. A strong unsupervised algorithm will be capable of learning by distinguishing without many examples.
Now that we have covered the top Deep Learning interview questions, it’s safe to say that you will give it your best shot and impress the interviewer with your answers. Don’t forget to check out the Deep Learning Tutorial to ensure you don’t miss out on any topic. You can also create your own deep learning machine to check your expertise on the domain. Without any further ado, get set and good luck!
Deep Learning FAQs
1. How do you prepare for a deep learning interview?
Preparing for an interview may seem quite intimidating. However, if you are clear with the fundamentals of deep learning, you can answer the questions confidently. Reading blogs, taking up a free online course to brush up your skills, and attending mock interview sessions are some ways through which you can prepare for a deep learning interview.
2. What are the topics in deep learning?
Deep Learning is a machine learning technology that makes use of neural networks. It is a broad concept that has several topics within it. Some of the concepts under deep learning are: basics of neural networks, common activation functions, recurrent neural networks, convolutional neural networks, back propagation, and more.
3. What is the best way to learn deep learning?
The best way to learn deep learning would vary from one individual to another. However, you can learn through blog posts, YouTube video content, free online courses, taking up a PG program, implementing the concepts learnt in your work environment, and though books. All the methods of learning are equally beneficial.
4. Can I directly learn deep learning?
Deep learning is a part of Machine Learning. To learning Deep Learning concepts, it is necessary to have a basic understanding of ML as well. However, there may be a few algorithms/models that are part of deep learning and not Machine Learning. You can learn those directly.
5. How do you master deep learning?
To master deep learning, start with learning the basic concepts. Once the foundational concepts of deep learning are clear, you can practice and implement the skills that you learnt in your daily work. Working on different projects and real-time activities will help you master deep learning.
6. How do I start deep learning?
To start deep learning, you can head over to Great Learning Academy and take up the Introduction to Deep Learning Free Online Course. This course covers all the basic concepts required for you to step into the world of deep learning and build your career.
7. How hard is deep learning?
The difficulty level of the time taken to learn deep learning varies from one individual to another. If you come from a technical background, it might be slightly easier for you to enter the field. If you are from a non-technical background, you may have to spend a longer amount of time to learn the basics and then deep dive into the other concepts.
8. How good is deep learning?
Deep learning is the best choice when it comes to concepts such as natural language processing or NLP, image processing, and speech recognition. It is extremely powerful in working with unstructured data.