
Object Detection using Tensorflow is a computer vision technique to detect objects in an image or a video in real time. As the name suggests, it helps us in locating, understanding and tracing an object from an image or a video. Let us gain a deeper understanding about how object detection works, what Tensorflow is, and more.
- What is object detection?
- How does object detection work?
- What is Tensorflow?
- What is Tensorflow object detection API?
- Object Detection Using Tensorflow
- Real-Tim Object detection using Tensorflow
What is Object detection?
Object detection is a computer vision technique in which a software system can detect, locate, and trace the object from a given image or video.
The special thing about object detection using tensorflow is that it identifies the class of objects (person, table, chair, etc.) and their location-specific coordinates in the given image.
The location is pointed out by drawing a bounding box around the object. The bounding box may or may not accurately locate the position of the object.
The ability to locate the object inside an image defines the performance of the algorithm used for detection. Face detection is one of the examples of object detection.
These object detection algorithms might be pre-trained or can be trained from scratch. In most use cases, we use pre-trained weights from pre-trained models and then fine-tune them as per our requirements and different use cases.
Object Detection using YOLO algorithm
How does Object detection work?
Generally, the object detection task is carried out in three steps:
- Generates the small segments in the input as shown in the image below. As you can see the large set of bounding boxes are spanning the full image

- Feature extraction is carried out for each segmented rectangular area to predict whether the rectangle contains a valid object.
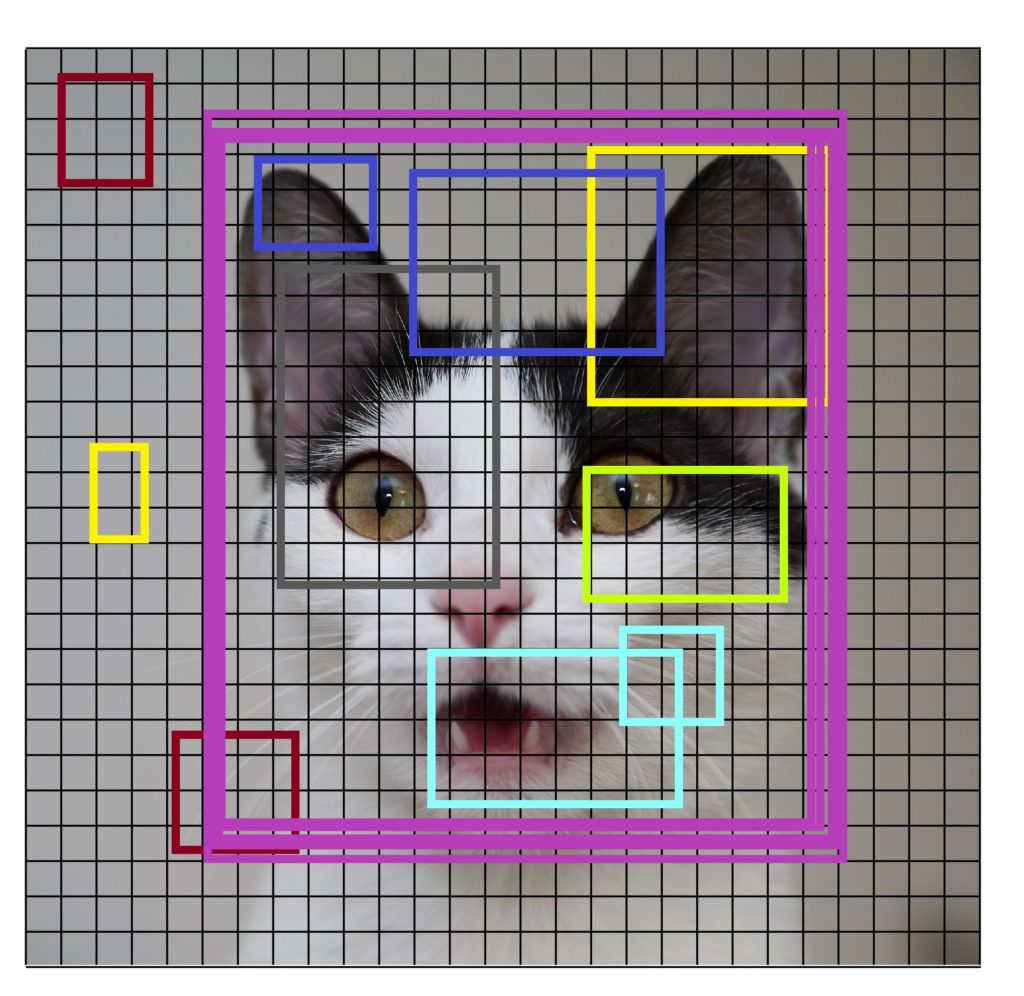
- Overlapping boxes are combined into a single bounding rectangle (Non-Maximum Suppression)

What is TensorFlow?
Tensorflow and Keras are open-source libraries for numerical computation and large-scale machine learning that ease Google Brain TensorFlow, the process of acquiring data, training models, serving predictions, and refining future results.
- Tensorflow bundles together Machine Learning and Deep Learning models and algorithms.
- It uses Python as a convenient front-end and runs it efficiently in optimized C++.
- Tensorflow allows developers to create a graph of computations to perform.
- Each node in the graph represents a mathematical operation and each connection represents data. Hence, instead of dealing with low-details like figuring out proper ways to hitch the output of one function to the input of another, the developer can focus on the overall logic of the application.
The deep learning artificial intelligence research team at Google, Google Brain, in the year 2015 developed TensorFlow for Google’s internal use. This Open-Source Software library is used by the research team to perform several important tasks.
TensorFlow is at present the most popular software library. There are several real-world applications of deep learning that makes TensorFlow popular. Being an Open-Source library for deep learning and machine learning, TensorFlow finds a role to play in text-based applications, image recognition, voice search, and many more. DeepFace, Facebook’s image recognition system, uses TensorFlow for image recognition. It is used by Apple’s Siri for voice recognition. Every Google app that you use has made good use of TensorFlow to make your experience better.
Transform healthcare with AI. Apply now for Johns Hopkins AI in Healthcare Program and enhance patient outcomes with cutting-edge skills
What is Tensorflow object detection API?
The TensorFlow Object Detection API is an open-source framework built on top of TensorFlow. It makes it easy to construct, train, and deploy object detection models. It lets the developers focus on the main logic of the application, and it takes care of object detection. Housing a great deal of pre-trained object detection models, Tensorflow gives you the power to work on crucial stuff rather than fighting over unimportant details as to which algorithm, Machine Learning, or Deep Learning to use.
- There are already pre-trained models in their framework which are referred to as Model Zoo.
- It includes a collection of pre-trained models trained on various datasets such as the
- COCO (Common Objects in Context) dataset,
- the KITTI dataset,
- and the Open Images Dataset.
As you may see below there are various models available so what is different in these models. These various models have different architecture and thus provide different accuracies but there is a trade-off between speed of execution and the accuracy in placing bounding boxes.
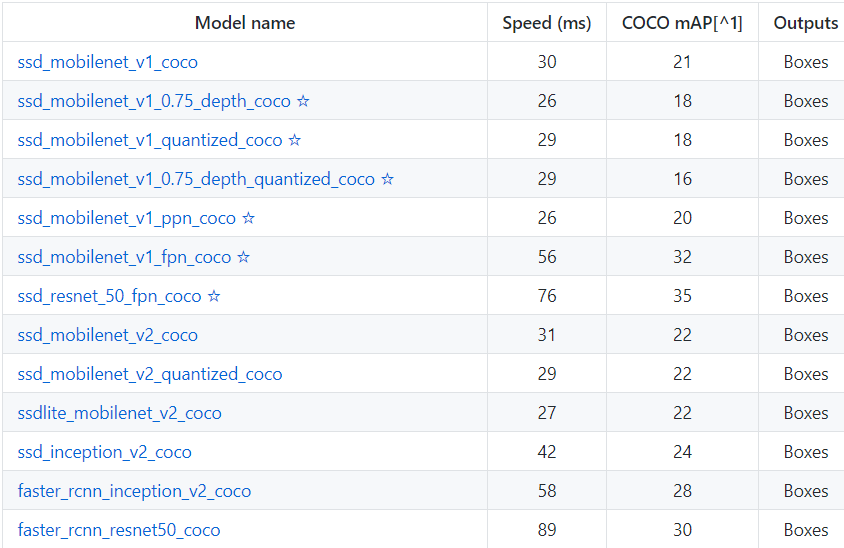
Here mAP (mean average precision) is the product of precision and recall on detecting bounding boxes. It’s a good combined measure for how sensitive the network is to objects of interest and how well it avoids false alarms. The higher the mAP score, the more accurate the network is but that comes at the cost of execution speed which we want to avoid here.
As my PC is a low-end machine with not much processing power, I am using the model ssd_mobilenet_v1_coco which is trained on COCO dataset. This model has decent mAP score and less execution time. Also, the COCO is a dataset of 300k images of 90 most commonly found objects so the model can recognise 90 objects
Object Detection Using Tensorflow
As mentioned above the knowledge of neural network and machine learning is not mandatory for using this API as we are mostly going to use the files provided in the API. All we need is some knowledge of python and passion for completing this project. Also, I assume Anaconda is already installed in your PC.So let us start by downloading some files:
Download Tensorflow API from Github Repository
There are two ways of doing this, one is by using git and another by manually downloading it :
- Using git: This is the easiest way of downloading the Tensorflow Object detection API from the repository but you need to have git installed in the system. Open the command prompt and type this command
- git clone https://github.com/tensorflow/models
- Downloading Manually: To manually download the API, go to this link and click on the code button(in green colour). You can see the download zip option, click on that you will have a compressed file. Now you need to extract the files.
After getting this API in your PC, rename the folder from models-master to models
- Setting up a virtual environment
Next, we are going to do is to create a separate virtual environment. The main purpose of Python virtual environments is to create an isolated environment for Python projects. This means that each project can have its own dependencies, regardless of what dependencies every other project has. I am naming my virtual environment as obj_detection but you can name it anything else. Now open the Anaconda prompt and type
- To set up the virtual environment:
conda create -n obj_detection
- To activate it the above created virtual environment:
conda activate obj_detection
Installing dependencies
The next step is to install all the dependencies needed for this API to work on your local PC. Type this command after activating your virtual environment.
- pip install tensorflow
If you have a GPU in your PC, use this instead. You will have a better performance
- pip install tensorflow-gpu
Next, use this command to install the rest of dependencies
- pip install pillow Cython lxml jupyter matplotlib contextlib2 tf_slim
Now we need to download Protocol Buffers (Protobuf) which are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data, – think of it as XML, but smaller, faster, and simpler. Download the appropriate version of Protobuf from here and extract it. After extracting it copy it to the ‘research’ sub-folder in the ‘models’ folders we downloaded earlier.
Now in the anaconda prompt, navigate to the folder containing the protoc file using the cd ‘path of folder’ and run this command
- protoc object_detection/protos/*.proto --python_out=.
To check whether this worked or not, you can go to the protos folder inside models>object_detection>protos and there you can see that for every proto file there’s one python file created.
Object detection Code
Now you need to go to the “object_detection” directory inside research subfolder and then create a new python file and paste this code. You can use Spyder or Jupyter to write your code. I would recommend using the Jupyter notebook.
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
import pathlib
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
from IPython.display import display
from object_detection.utils import ops as utils_ops
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
while "models" in pathlib.Path.cwd().parts:
os.chdir('..')
def load_model(model_name):
base_url = 'http://download.tensorflow.org/models/object_detection/'
model_file = model_name + '.tar.gz'
model_dir = tf.keras.utils.get_file(
fname=model_name,
origin=base_url + model_file,
untar=True)
model_dir = pathlib.Path(model_dir)/"saved_model"
model = tf.saved_model.load(str(model_dir))
return model
PATH_TO_LABELS = 'models/research/object_detection/data/mscoco_label_map.pbtxt'
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
model_name = 'ssd_inception_v2_coco_2017_11_17'
detection_model = load_model(model_name)
def run_inference_for_single_image(model, image):
image = np.asarray(image)
# The input needs to be a tensor, convert it using `tf.convert_to_tensor`.
input_tensor = tf.convert_to_tensor(image)
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = input_tensor[tf.newaxis,...]
# Run inference
model_fn = model.signatures['serving_default']
output_dict = model_fn(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(output_dict.pop('num_detections'))
output_dict = {key:value[0, :num_detections].numpy()
for key,value in output_dict.items()}
output_dict['num_detections'] = num_detections
# detection_classes should be ints.
output_dict['detection_classes'] = output_dict['detection_classes'].astype(np.int64)
# Handle models with masks:
if 'detection_masks' in output_dict:
# Reframe the the bbox mask to the image size.
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
output_dict['detection_masks'], output_dict['detection_boxes'],
image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(detection_masks_reframed > 0.5,
tf.uint8)
output_dict['detection_masks_reframed'] = detection_masks_reframed.numpy()
return output_dict
def show_inference(model, image_path):
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = np.array(Image.open(image_path))
# Actual detection.
output_dict = run_inference_for_single_image(model, image_np)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks_reframed', None),
use_normalized_coordinates=True,
line_thickness=8)
display(Image.fromarray(image_np))Inside the object detection folder, we have a folder named as test_images. There are two images already in that folder that will be used to test the model. We can put our Images also for which we want to located objects and run the below cells to get the results.
PATH_TO_TEST_IMAGES_DIR = pathlib.Path('models/research/object_detection/test_images')
TEST_IMAGE_PATHS = sorted(list(PATH_TO_TEST_IMAGES_DIR.glob("*.jpg")))
for image_path in TEST_IMAGE_PATHS:
print(image_path)
show_inference(detection_model, image_path)
Here are some of the predictions on some random pictures I took from Google.


Object Detection using YOLO algorithm
Real-Time Object detection using Tensorflow
The steps in detecting objects in real-time are quite similar to what we saw above. All we need is an extra dependency and that is OpenCV. So to install OpenCV run this command in our virtual environment.
pip install opencv-python
Now just copy and paste this code and you are good to go
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
import pathlib
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
from IPython.display import display
from object_detection.utils import ops as utils_ops
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
while "models" in pathlib.Path.cwd().parts:
os.chdir('..')
def load_model(model_name):
base_url = 'http://download.tensorflow.org/models/object_detection/'
model_file = model_name + '.tar.gz'
model_dir = tf.keras.utils.get_file(
fname=model_name,
origin=base_url + model_file,
untar=True)
model_dir = pathlib.Path(model_dir)/"saved_model"
model = tf.saved_model.load(str(model_dir))
return model
PATH_TO_LABELS = 'models/research/object_detection/data/mscoco_label_map.pbtxt'
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
model_name = 'ssd_inception_v2_coco_2017_11_17'
detection_model = load_model(model_name)
def run_inference_for_single_image(model, image):
image = np.asarray(image)
# The input needs to be a tensor, convert it using `tf.convert_to_tensor`.
input_tensor = tf.convert_to_tensor(image)
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = input_tensor[tf.newaxis,...]
# Run inference
model_fn = model.signatures['serving_default']
output_dict = model_fn(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(output_dict.pop('num_detections'))
output_dict = {key:value[0, :num_detections].numpy()
for key,value in output_dict.items()}
output_dict['num_detections'] = num_detections
# detection_classes should be ints.
output_dict['detection_classes'] = output_dict['detection_classes'].astype(np.int64)
# Handle models with masks:
if 'detection_masks' in output_dict:
# Reframe the the bbox mask to the image size.
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
output_dict['detection_masks'], output_dict['detection_boxes'],
image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(detection_masks_reframed > 0.5,
tf.uint8)
output_dict['detection_masks_reframed'] = detection_masks_reframed.numpy()
return output_dict
Till here everything was the same as the previous section, but now you can see some minor changes. All we do is to get frames from the webcam feed and convert them to Numpy arrays.
def show_inference(model, frame):
#take the frame from webcam feed and convert that to array
image_np = np.array(frame)
# Actual detection.
output_dict = run_inference_for_single_image(model, image_np)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks_reframed', None),
use_normalized_coordinates=True,
line_thickness=5)
return(image_np)
#Now we open the webcam and start detecting objects
import cv2
video_capture = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
re,frame = video_capture.read()
Imagenp=show_inference(detection_model, frame)
cv2.imshow('object detection', cv2.resize(Imagenp, (800,600)))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
Here is the output of the code:
This brings us to the end of this article where we learned how to use Tensorflow object detection API to detect objects in images as well as in webcam feed too.
Looking to get started with TensorFlow? Check out our free tensorflow courses and learn how to build effective machine learning models!








