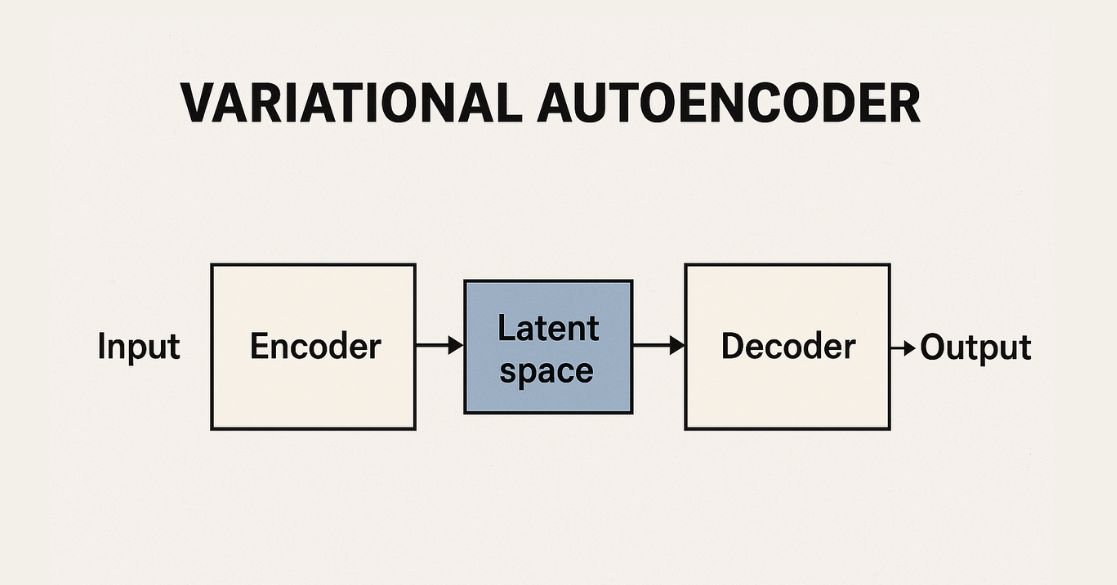
Variational Autoencoders (VAEs) are a type of deep learning model used for unsupervised learning and data generation. They extend traditional autoencoders by incorporating probabilistic techniques, allowing them to generate new data that resembles the training dataset.
Unlike standard autoencoders, which focus solely on compressing and reconstructing data, VAEs learn the underlying probability distribution of the data. This makes them particularly useful for applications such as image generation, anomaly detection, data compression, and feature learning.
By leveraging a latent space representation, VAEs can create diverse and realistic outputs while maintaining a structured, continuous, and interpretable encoding of the data.
Understanding Autoencoders
An autoencoder is a type of neural network used to compress data into a lower-dimensional representation and then reconstruct it back to its original form. Autoencoders consist of two main components:
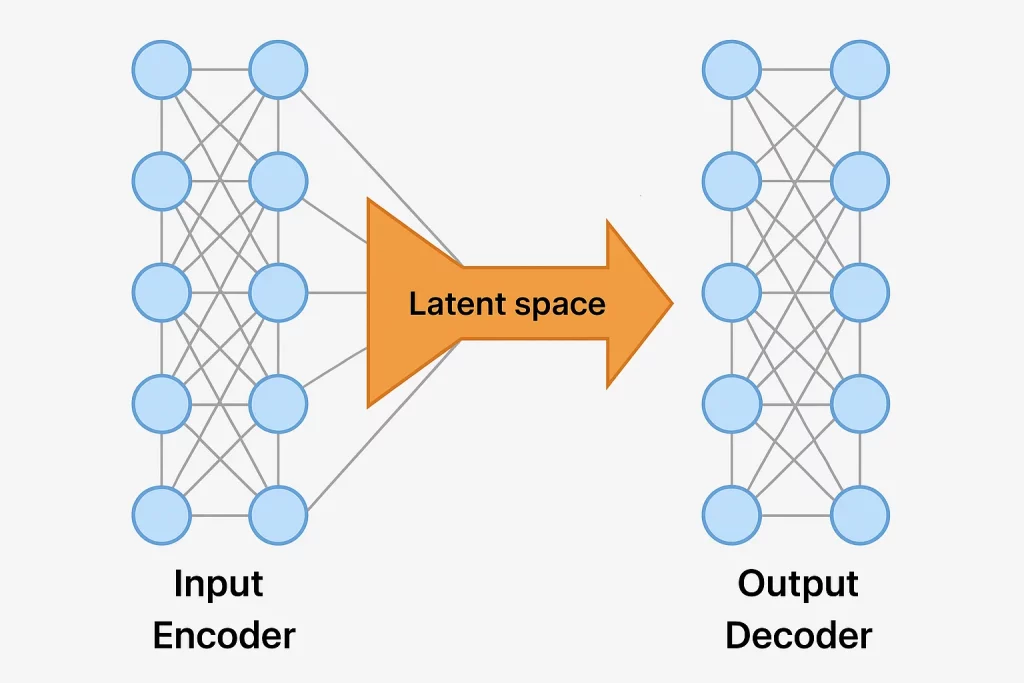
- Encoder: Compresses the input into a compact representation (latent space).
- Decoder: Reconstructs the original input from this compact representation.
A traditional autoencoder learns to map an input X to a lower-dimensional representation Z and then back to an approximation of X. However, they do not enforce any constraints on how the compressed representations are structured, which makes them less useful for data generation.
How Variational Autoencoders Work
VAEs improve upon traditional autoencoders by enforcing a probabilistic structure on the latent space. Instead of learning a direct mapping to a compressed space, VAEs learn to represent data as a probability distribution. This helps in generating new data by sampling from this learned distribution.

1. Encoder
The encoder does not just generate a single compressed vector; instead, it models the data as a probability distribution. It outputs two vectors:
- Mean (μ): Represents the center of the learned distribution.
- Variance (σ²): Determines the spread of the distribution.
These parameters define a normal distribution (Gaussian distribution) in the latent space, from which new samples can be generated.
2. Reparameterization Trick
A key challenge in VAEs is that sampling from a probability distribution is not differentiable, making backpropagation difficult. To overcome this, VAEs use the reparameterization trick, which introduces a small amount of randomness to make sampling differentiable:
z = μ + σ * ε
where is a random variable sampled from a standard normal distribution. This allows gradients to be backpropagated through the encoder, enabling efficient learning.
3. Decoder
The decoder reconstructs the original input from the sampled latent variable. It learns to map the probabilistic latent space back to the data space.
4. Loss Function
VAEs optimize two key loss functions:
- Reconstruction Loss: Ensures that the reconstructed data is similar to the original input.
- KL Divergence Loss: Encourages the learned distribution to be close to a standard normal distribution , preventing overfitting.
The total loss function is:
L = Lreconstruction + λLKL
where λ balances reconstruction and regularization.
Where λ balances reconstruction and regularization.
Get familiar with popular Machine Learning algorithms and learn how they help build smart, data-driven solutions.
Applications of VAEs

1. Image Generation: VAEs can be trained on large image datasets to generate new, realistic images. Examples include:
- Face Generation: Creating human-like faces.
- Art and Style Transfer: Generating new artistic styles.
2. Anomaly Detection: Since VAEs learn the underlying distribution of normal data, they can detect anomalies as outliers. Examples:
- Fraud Detection: Identifying unusual transaction patterns.
- Medical Diagnosis: Spotting abnormalities in medical images.
3. Data Compression: VAEs can learn compressed representations of data, reducing storage and improving efficiency.
4. Feature Learning: The latent space representation learned by VAEs can be useful for other machine-learning tasks such as clustering and classification.
Variational Autoencoder vs Generative Adversarial Network
While VAEs and Generative Adversarial Networks (GANs) are both generative models, they have key differences:
| Feature | VAEs | GANs |
| Training Method | Uses probability distributions | Uses a generator-discriminator approach |
| Output Sharpness | Often blurry images | Sharp, high-quality images |
| Use Case | Good for representation learning | Best for generating highly realistic data |

Challenges and Future Improvements
1. Blurry Images: Since VAEs optimize reconstruction loss using a probabilistic approach, the generated images tend to be blurrier than GAN-generated images.
2. Posterior Collapse: If the KL loss term is too strong, the latent space may collapse, reducing the effectiveness of the model.
3. Scalability: Training VAEs on high-resolution images is computationally expensive and requires better architectures.
Future Advancements
- VAE-GAN Hybrids: Combining VAEs with GANs for better image quality.
- Hierarchical VAEs: Using multiple levels of latent representations for improved results.
- Disentangled Representations: Learning independent features to improve interpretability.
Conclusion
Variational Autoencoders (VAEs) are powerful tools for learning data representations and generating new data. They use probability distributions to create smooth and meaningful latent spaces, making them useful for tasks like image generation, anomaly detection, and data compression.
While they may produce blurrier images than GANs, VAEs are easier to train and great for structured data modeling. As research advances, VAEs will continue improving, especially when combined with other generative models.
Master advanced AI techniques with the Master Generative AI program. Gain expertise in deep learning, NLP, and AI-powered content generation with hands-on projects.
Frequently Asked Questions(FAQ’s)
What makes Variational Autoencoders (VAEs) different from regular autoencoders?
Variational Autoencoders (VAEs) learn a probability distribution instead of a fixed encoding. This allows them to generate new data points, unlike regular autoencoders, which only reconstruct inputs.
Can Variational Autoencoders (VAEs) generate high-quality images?
Yes, but VAE-generated images may be slightly blurry due to their probabilistic nature. Generative Adversarial Networks (GANs) usually produce sharper and more detailed images.
Are Variational Autoencoders (VAEs) only used for images?
No, Variational Autoencoders (VAEs) are also used for text, speech, and other structured data. They are widely applied in Natural Language Processing (NLP), bioinformatics, and data compression.
Do Variational Autoencoders (VAEs) need labeled data?
No, Variational Autoencoders (VAEs) use unsupervised learning and do not require labeled data. They learn patterns from the input data itself.
Can Variational Autoencoders (VAEs) be combined with other models?
Yes, Variational Autoencoders (VAEs) are often combined with Generative Adversarial Networks (GANs) for better image quality. They can also be integrated with transformers and other deep learning architectures.








