
- What is Data Cleaning in Python?
- How to perform Data Cleaning in Python?
- Remove Repeated Values
- Missing Value Treatment
- Removal of irrelevant data
- Manual Error While Typing
- Renaming Columns
Contributed by: Praneeta
LinkedIn Profile: linkedin.com/in/praneeta-Kalaskar-903073a1
When we talk about the real world, most of the data we come across for analysis is raw data. This raw data is the combination of repeated, missing, and many irrelevant rows. Hence, if passed to a model, it results in inaccuracy or incorrect prediction, which ultimately leads us to understand the importance of Data Cleaning. Data Cleaning in Python, also known as Data Cleansing is an important technique in model building that comes after you collect data. It can be done manually in excel or by running a program. In this article, therefore, we will discuss data cleaning entails and how you could clean noises(dirt) step by step by using Python.
What is Data Cleaning?
According to Wikipedia, is the process of detecting and correcting corrupt or inaccurate records from a record-set, table, or database and refers to identifying incomplete, incorrect, inaccurate, or irrelevant parts of the data, and then replacing, modifying, or deleting the dirty or coarse data.
This definition is too big and certainly not easy to understand. To make it easier, we can see an example. Consider a scenario where a factory owner of Dairy Products is interested in knowing the frequent buyers of milk bottles to increase the customer base. But if the data is corrupted or has noise, then the decision will be misguided. In the below data, we have shown an example.
From the figure, we can depict that Data Cleaning is a technique which helps to convert improper data into meaningful data. In short, Machine Learning is data-driven. With data cleaning in place, your Machine Learning model will perform better. So, it is important to process data before use. Without quality data, it is foolish to expect a correct output.
Also Read: Top Data Mining Applications in Industries
How to perform Data Cleaning in Python?
For understanding, let’s take the example of a survey in which a company's HR staff has to locate all of its area employees, and make sure they are safe at home. Before that, let’s understand that there are no Standard Data Cleaning Techniques. It is not possible to comment on which one is best. The only aspect which needs to be considered on cleaning methods depends on the nature of Data. This helps us choose which technique should be used.
We will get back to the example. To keep it simpler, we are looking at below fields.
Look at the table carefully. You'll notice that certain fields are either blank or have irrelevant values. If we process such data, then our prediction will be in trouble. Thus, we will carry out the below steps for Data Cleaning.
- Remove Repeated Row
- Missing value treatment
- Removal of Irrelevant Data
- Manual error while typing
- Renaming Columns
As to process data, our first step would be to read data in Python.
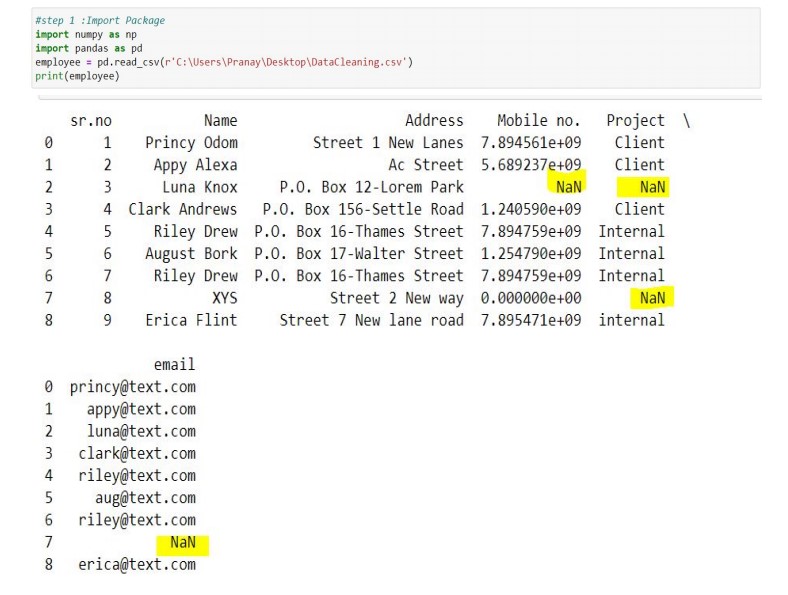
Observe the output table carefully, it's the same table which we had in the first place.
The two important packages which we imported are Panda and Numpy. These are needed for a Python code to run. The next important thing is acronyms we adopted as a good practice. employee variable used to store data read from DataCleaning.csv file saved at the mentioned location. The command used to read data is read_csv and displayed on the screen by using print. For the fields having missing value, the system has filled it with NaN(Not a number).
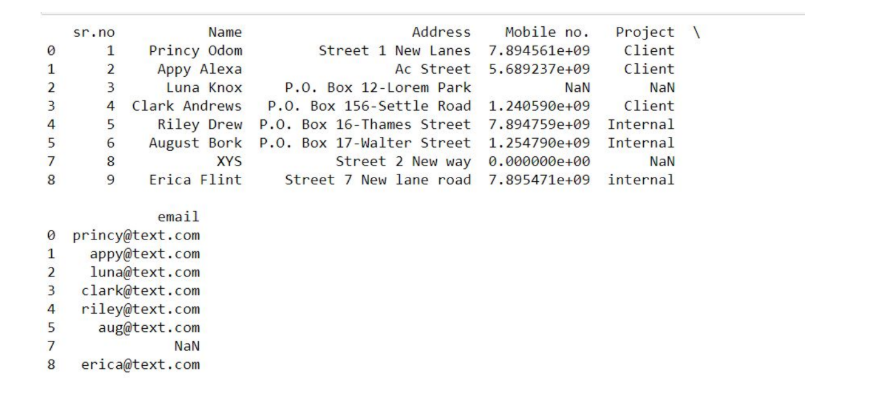
Remove Repeated Values
We know that there are duplicates in the dataset and that need to be removed. Row 5 and 7 have the same employee data.

We can delete the last row, and keep the first row.

Function drop_duplicates returns output with repeated rows removed. Below are the parameters used in a command.
subset: We have assigned column name to subset parameters to check repeated values. By default, it takes all columns.
keep: for keeping the first row(5)
inplace: Boolean case, default false. By assigning true we asked the command to drop last value.
Data with no repeated values.
Missing Value Treatment
In panda, missing data is represented in two ways. None or NaN. In our dataset, missing values are recognized as NaN. For checking missing values, we have used the function is.null().

The output of the command is boolean which is True for NaN values.
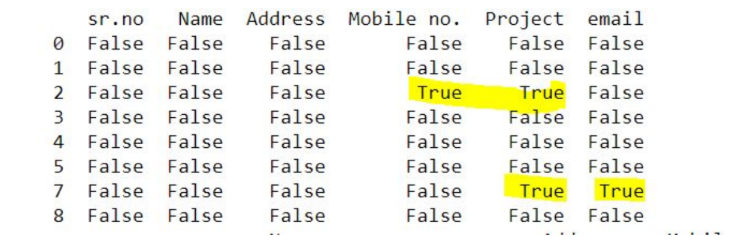
As shown in the output image, column Mobile no., Project and email have missing values. Missing values can either be filled or dropped.
In our example, we are working on employee data so filling it with any value will be inappropriate. Hence, we have dropped the missing values.
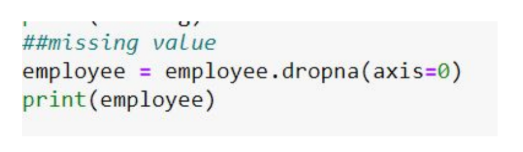
The command dropna drops rows/columns having at least null values in CSV file.

As shown in the output table, missing values are removed from the dataset.
Removal of irrelevant data
Sometimes, certain categories/columns in a dataset are not useful. In our case, column name, serial no are not important. Retaining it will take unnecessary space and consume time.
Panda provides an easy command del to remove the unwanted column.

If we inspect the data we will see that the column is removed successfully.
Manual Error While Typing
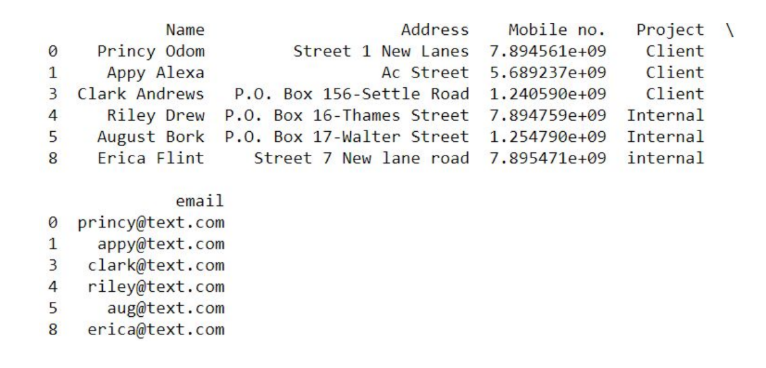
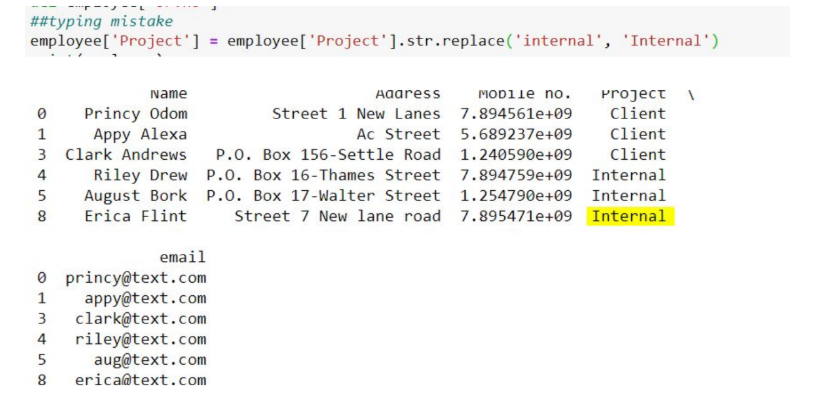
In this step, we need to make sure the data has correct values whenever there are categories mentioned. In our case, the column Project has two possible values Client or Internal. But close observation of the output table can help us to point row 8 where the value is not following the possible case. (i.e, internal should be corrected to Internal).
In python, we can replace the column with the corrected value.
Renaming Columns
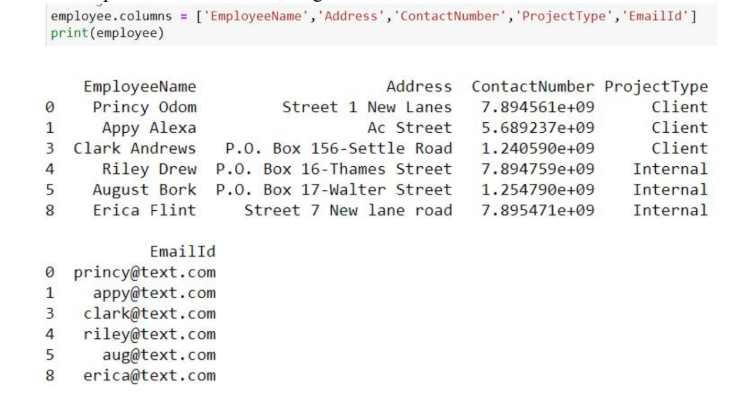
The dataset we are working on has a column name that does not speak about the importance of the data it holds. Thus, we will add some sensible labels by renaming the columns.
The output demonstrates the change in column name.
Recap to Data Cleaning
In this article, we have treated unnecessary information by using various steps. We have removed the duplicate rows, treated missing values, deleted irrelevant columns, and corrected the typing mistake. Lastly, the article also talks about renaming columns.
If you found this guide on Data Cleaning in Python helpful and wish to learn more such concepts, join Great Learning Academy's free online courses today.









