
- What is Machine Learning in a Business Context?
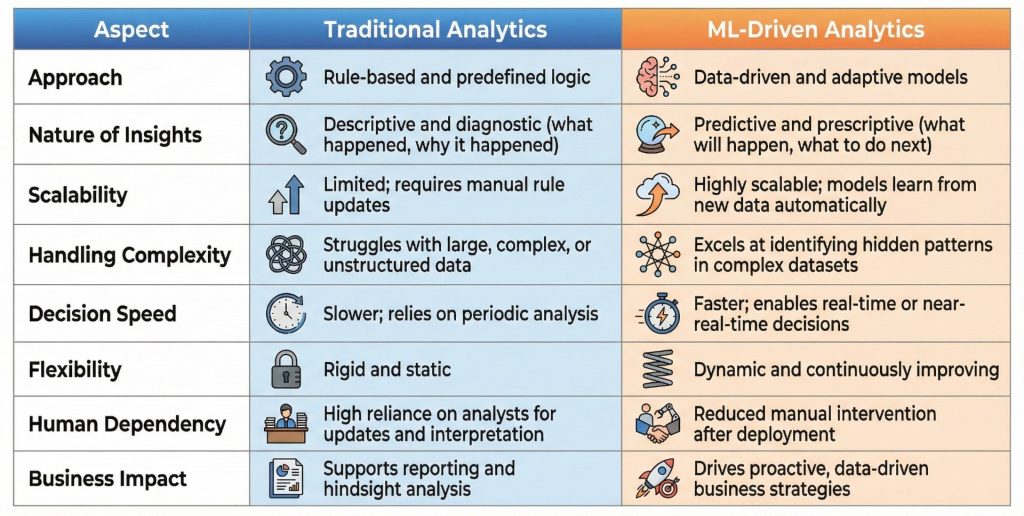
- Difference Between Traditional Analytics & ML-Driven Analytics
- Types of Machine Learning Models Used in Business
- Why Businesses Are Adopting Machine Learning?
- How to Get Started with Data-Driven Decisions in Your Business with ML?
- Best Practices for Successful ML Adoption
- Conclusion
The shift toward data-driven decision-making is reshaping how businesses operate, compete, and grow.
Machine learning plays a central role in this transformation by enabling organizations to uncover patterns, predict outcomes, and automate insights at scale.
For leaders aiming to move from intent to measurable impact, this article presents a practical roadmap for implementing machine learning in business applications that prioritizes business outcomes, operational feasibility, and long-term value creation.
What is Machine Learning in a Business Context?
Machine learning (ML) refers to the use of algorithms that enable systems to learn from historical and real-time data to:
- Identify Patterns
- Predict Outcomes
- Support Decision-Making Without Being Explicitly Programmed
Fundamentally, integrating machine learning in business applications shifts the organizational focus from hindsight to foresight. It allows businesses to automate complex decision-making processes such as dynamic pricing, fraud detection, or personalized marketing at a speed and scale impossible for human analysts.
It is the transition from asking "What happened?" to asking "What will happen next?"
Difference Between Traditional Analytics & ML-Driven Analytics
Types of Machine Learning Models Used in Business
1. Supervised Learning
The algorithm is trained on a labeled dataset, meaning it is given both the input (the question) and the correct output (the answer). It learns the relationship between the two so it can predict the output for new, unseen data.
- Classification: Used when the output is a category or label (e.g., Yes/No, Spam/Not Spam, High Risk/Low Risk).
- Regression: Used when the output is a continuous numerical value (e.g., price, temperature, sales volume).
Real-World Business Examples:
- Credit Risk Assessment (Classification): A bank feeds the model historical data on loan applicants (income, debt, history) labeled as "Defaulted" or "Repaid." The model then classifies new applicants as high or low risk.
- Sales Forecasting (Regression): A retailer inputs past sales data, seasonality, and marketing spend to predict exact revenue figures for the upcoming quarter.
2. Unsupervised Learning
The algorithm explores the data structure to find hidden patterns, correlations, or groupings that humans might miss.
- Clustering: Grouping similar data points together based on shared characteristics.
- Anomaly Detection: Identifying data points that significantly deviate from the norm.
Real-World Business Examples:
- Customer Segmentation (Clustering): Marketing teams feed the model raw customer data. The model identifies distinct "clusters" (e.g., "Price-Sensitive Students" vs. "High-Spending Professionals"), allowing for hyper-targeted marketing campaigns.
- Fraud Detection (Anomaly Detection): In fintech, a model learns the "normal" spending behavior of a user. If a transaction occurs that is statistically improbable (e.g., a card used in London and Tokyo within an hour), it flags the anomaly for review.
3. Reinforcement Learning
The algorithm learns through trial and error. It operates in an environment where it takes actions and receives feedback in the form of "rewards" (positive outcomes) or "penalties" (negative outcomes). Its goal is to maximize the cumulative reward over time.
Real-World Business Examples:
- Dynamic Pricing: A ride-share app or airline uses RL to adjust prices in real-time. If it raises prices too high, demand drops (penalty); if too low, revenue is left on the table (penalty). It learns the optimal price point to balance supply and demand.
- Supply Chain Robotics: Warehouse robots use RL to determine the most efficient path to pick and pack items, learning to navigate obstacles and minimize travel time to increase fulfillment speed.
Why Businesses Are Adopting Machine Learning?
- Leveraging Unstructured Information
Conventional analytics often overlook unstructured information such as emails, customer support chats, images, and documents. Machine learning techniques, particularly natural language processing, enable organizations to structure and analyze this data, transforming underutilized information into actionable intelligence.
- Individualized Customer Engagement
Traditional marketing relies on broad demographic segments. Machine learning enables personalization at the individual level by leveraging real-time behavioral insights. This allows businesses to move from reactive support to anticipatory engagement, strengthening customer relationships and long-term loyalty.
- Sustainable Data-Driven Advantage
The strategic use of machine learning in business applications creates a self-reinforcing advantage. As models improve, products and services become more effective, attracting more users. Increased usage generates additional data, further enhancing model performance. This compounding cycle establishes a competitive advantage that is difficult for late entrants to replicate.
- Operational Efficiency and Cost Stability
Machine learning enhances efficiency by optimizing resource allocation across operations. It reduces energy consumption, improves logistics, and automates routine processes, resulting in lower operating costs and improved resilience during economic uncertainty.
How to Get Started with Data-Driven Decisions in Your Business with ML?
Here is a practical guide to getting started with data-driven decisions using Machine Learning. For practical understanding, we will use a single example throughout every step of: A Subscription Software Company wanting to reduce Customer Churn.
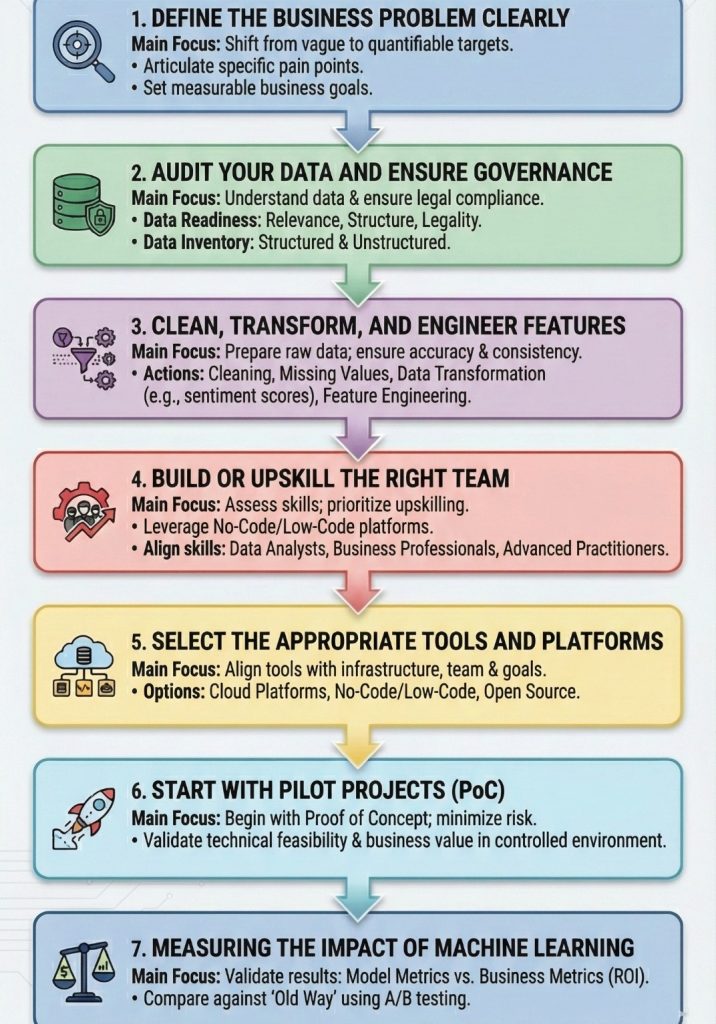
Step 1: Define the Business Problem Clearly
The most common cause of failure is starting with the solution ("Let's use AI") instead of the problem. You must articulate a specific pain point and a measurable business goal.
Key Focus: Shift from vague goals ("Improve service") to quantifiable targets ("Reduce response time by 20%").
Example:
- The Problem: The company is losing 15% of its subscribers annually, costing $2M in lost revenue.
- The Objective: Identify customers at risk of cancelling before they leave.
- Success Metric: Reduce annual churn rate from 15% to 12% within 6 months.
Step 2: Audit Your Data and Ensure Governance
Before building any machine learning models, it is critical to understand what data you have and ensure it is legally compliant. Data readiness is not just about quantity; it is about relevance, structure, and legality.
Key Considerations:
1. Data Inventory: Identify all data sources, including:
- Structured Data: Databases, spreadsheets, transaction logs.
- Unstructured Data: Emails, chat logs, images, audio, or social media content.
2. Governance and Compliance: Ensure you have the legal right to use the data. Apply anonymization and adhere to regulations such as GDPR or CCPA.
Example:
- Data Audit: The company reviews CRM and billing systems.
- Availability: 5 years of structured data (login frequency, payment history, subscription tier) and unstructured data (support chat logs).
- Governance: All customer data is anonymized to comply with GDPR before analysis.
Outcome:
You now have a clear understanding of your data sources, their formats, and legal readiness for use in machine learning projects.
Step 3: Clean, Transform, and Engineer Features
Once your data is audited and compliant, the next step is to prepare it for modeling. Raw data is rarely directly usable for machine learning. This step ensures the data is accurate, consistent, and structured in a way that algorithms can interpret.
Key Actions:
- Data Cleaning: Remove duplicates and inconsistencies. Handle missing values, decide whether to remove incomplete records or impute values (e.g., averages, medians, or predictions).
- Data Transformation: Convert textual or categorical data into numeric formats. Example: Convert “Customer complained” into a sentiment score (-0.8).
- Feature Engineering: Derive new variables that improve predictive power. Example: Aggregate purchase frequency or calculate churn probability based on login patterns.
Key Focus:
- Machine learning models are only as reliable as the data they are trained on. Poorly prepared data leads to inaccurate and misleading predictions.
- Data preparation is not a preliminary task; it is the foundation of model performance and long-term business impact.
Example:
- Missing values in customer age and activity history are imputed.
- Chat logs are processed using NLP techniques to generate sentiment scores.
- Key behavioral indicators such as subscription duration and engagement frequency are engineered for model input.
Outcome:
A clean, structured, and high-quality dataset ready for training and validating machine learning models.
Step 4: Upskill Your Team
Successful machine learning adoption depends as much on people as it does on technology. Organizations should assess whether their current teams possess the skills required to support ML initiatives or whether targeted upskilling is necessary before considering new hires.
Key Focus:
Prioritize upskilling existing talent through structured machine learning programs such as No Code AI and Machine Learning: Building Data Science Solutions, which enable professionals to design, build, and deploy machine learning models using intuitive, no-code platforms.
No Code AI and Machine Learning: Building Data Science Solutions
Build AI and machine learning tools without any coding. Made for professionals ready to lead in the AI-driven world.
This approach allows teams to focus on business problem-solving and decision-making rather than technical complexity, making ML adoption faster and more accessible across functions.
Team Composition and Skill Alignment:
- Data Analysts: Can transition from descriptive reporting to predictive and prescriptive analytics by learning data preparation, feature engineering, and model interpretation.
- Business and Functional Professionals: Can actively participate in ML initiatives without deep coding knowledge through no-code and low-code approaches.
- Advanced ML Practitioners (as needed): Support complex modeling, deployment, and optimization efforts.
Strategic Approach:
For organizations initiating their first ML projects, a blended strategy works best, leveraging external expertise for early guidance while enrolling internal teams in structured upskilling programs to ensure long-term ownership and scalability.
Step 5: Select the Appropriate Tools and Platforms
Selecting the right tools and platforms is a critical decision that directly impacts scalability, cost, and adoption speed.
Organizations should avoid selecting tools based on trends and instead focus on alignment with existing infrastructure, team capabilities, and long-term business goals. Primary Options:
- Cloud Platforms (AWS SageMaker, Google Vertex AI): Best for scalability if you are already on the cloud.
- No-Code/Low-Code (DataRobot, H2O.ai): Best for business analysts to build models without deep coding knowledge.
- Open Source (TensorFlow, PyTorch, Scikit-learn): Best for custom, highly flexible solutions (requires coding experts).
Example:
- Selection: Since the company's data is already hosted on AWS, they chose AWS SageMaker.
- Reasoning: It integrates easily with their existing S3 storage buckets, and the external consultants are already certified in it. This minimizes integration friction.
Outcome:
By selecting a platform that aligns with both infrastructure and team expertise, the company accelerates model development, reduces implementation risk, and establishes a scalable foundation for future machine learning initiatives.
Step 6: Start with Pilot Projects (Proof of Concept)
Organizations should avoid deploying machine learning solutions across the entire business at the outset. Instead, it is recommended to begin with a Proof of Concept (PoC), a controlled, small-scale initiative designed to validate both technical feasibility and business value.
Key Focus:
Adopt a measured approach that minimizes risk and cost. A model that fails to demonstrate value in a pilot environment is unlikely to succeed at scale.
Example:
- Pilot Scope: Rather than deploying the model across all 50,000 users, the company tests it on a randomly selected subset of 5,000 users.
- Action Taken: The model identifies 500 users within this group as high-risk for churn. The marketing team targets only these users with personalized retention offers.
Outcome:
The pilot provides clear evidence of model effectiveness, enables data-driven decision-making, and informs whether the solution should be refined, scaled, or discontinued.
Step 7: Measuring the Impact of Machine Learning
Finally, you must validate the results. This involves two types of metrics: Model Metrics (Technical accuracy) and Business Metrics (ROI). A model can be 99% accurate but financially useless if it predicts things that don't save money.
Key Focus:
Compare the ML approach against the "Old Way" (Control Group) using A/B testing.
What to Measure?
- Model Metrics: Accuracy, precision, recall, or other relevant performance indicators.
- Business Metrics: Revenue impact, cost savings, efficiency gains, or ROI.
- Benchmarking: Compare results against a control group or previous methods using A/B testing.
Example:
- Technical Metric: The model successfully identified 70% of the people who were about to churn (Recall rate).
- Business ROI: In the pilot group of 500 "at-risk" users, 100 renewed their subscription because of the intervention
- Result: The cost of the discount was $2,000. The saved revenue from retained customers was $20,000. ROI is 10x. The pilot is a success; the company creates a roadmap to roll this out to the remaining 45,000 users.
Best Practices for Successful ML Adoption
- Avoid the “Black Box” Trap
Deploying machine learning models without transparency undermines trust and adoption. Organizations should prioritize Explainable AI (XAI) to ensure that model decisions, such as loan rejections or churn predictions, are clearly understandable and can be justified by business teams.
- Keep Humans in the Loop (HITL)
ML systems require continuous oversight. Models can degrade over time due to changing market conditions or data patterns. Incorporating human review and periodic validation ensures predictions remain relevant, reliable, and aligned with business objectives.
- Eliminate Data Silos
Machine learning delivers optimal results when it has access to the complete context. Fragmented data across platforms such as Salesforce, Excel, and Zendesk limits model effectiveness. Establish a centralized data repository, such as a data lake or warehouse, to enable holistic analysis and more accurate predictions.
Conclusion
The transition from intuition to data-driven precision through machine learning in business applications is no longer just a competitive advantage; it is a necessity.
Yet, the most powerful algorithms are useless without a team that understands how to interpret them ethically and effectively to drive strategy. To bridge this gap and ensure your workforce can translate raw numbers into measurable growth, invest in the right foundation.
Empower your team with AI and Data Science: Leveraging Responsible AI, Data, and Statistics for Practical Impact, a course designed to provide the practical skills needed to harness data, ensure ethical compliance, and deliver high-value business outcomes.





