
In supervised learning, to enable an algorithm’s predictions to be as close to the actual values/labels as possible, we employ two things: 1) A cost function and 2) A technique to minimize the cost function. There are popular forms of cost functions used for different tasks that the algorithms are expected to perform. Also, a popular technique used to minimize the cost function is the gradient descent method. We will understand these concepts to understand the role of ‘learning rate’ in machine learning.
Cost Function
A cost function is a measure of the error in prediction committed by an algorithm. It indicates the difference between the predicted and the actual values for a given dataset. Closer the predicted value to the actual value, the smaller the difference and lower the value of the cost function. Lower the value of the cost function, the better the predictive capability of the model. An ideal value of the cost function is zero. Some of the popular cost functions used in machine learning for applications such as regression, classification, and density approximation are shown in table-1.
To further the discussion, let’s consider the cost function for regression, in which the objective is to learn a mapping function between the predictors (independent variables) and target (dependent variable). If we assume the relationship to be linear, the equation for the predicted value (yi) is shown below.

In equation-1, x1 and x2 are the two predictors and β0, β1, β2 are the model parameters. The algorithm learns(estimates) the values of these parameters during training.
In regression, the typical cost function (CF) used is the mean squared error (MSE) cost function. The form of the function is shown below.

In the above equation, yi and yi are respectively the actual and predicted values. n is the number of records in the dataset. Replacing yi in the above equation, the cost function can be re-written as shown below

In the above equation, it is important to note that the values for yi, x1i and x2i come from the dataset and cannot be manipulated to minimize the cost function. Only the model parameters β0, β1, β2 can be manipulated to minimize the cost function. For the given dataset, these parameters can be estimated using the gradient descent method such that the cost function value is minimum.
Gradient Descent Method
Gradient descent is the popular optimization algorithm used in machine learning to estimate the model parameters. During training a model, the value of each parameter is guessed or assigned random values initially. The cost function is calculated based on the initial values and the parameter estimates are improved over several steps such that the cost function assumes a minimum value eventually. This is shown in figure 1 below.
The equation used to improve the estimate is shown below. It is important to note that when one of the parameter’s estimates is being improved, the other parameters are held constant. In our example, while the estimate for βo is being improved, β1 and β2 are held constant.
Learning rate
In machine learning, we deal with two types of parameters; 1) machine learnable parameters and 2) hyper-parameters. The Machine learnable parameters are the one which the algorithms learn/estimate on their own during the training for a given dataset. In equation-3, β0, β1 and β2 are the machine learnable parameters. The Hyper-parameters are the one which the machine learning engineers or data scientists will assign specific values to, to control the way the algorithms learn and also to tune the performance of the model. Learning rate, generally represented by the symbol ‘α’, shown in equation-4, is a hyper-parameter used to control the rate at which an algorithm updates the parameter estimates or learns the values of the parameters.
Get hands on practice, take Machine Learning Quiz.
Effect of different values for learning rate
Learning rate is used to scale the magnitude of parameter updates during gradient descent. The choice of the value for learning rate can impact two things: 1) how fast the algorithm learns and 2) whether the cost function is minimized or not. Figure 2 shows the variation in cost function with a number of iterations/epochs for different learning rates.
It can be seen that for an optimal value of the learning rate, the cost function value is minimized in a few iterations (smaller time). This is represented by the blue line in the figure. If the learning rate used is lower than the optimal value, the number of iterations/epochs required to minimize the cost function is high (takes longer time). This is represented by the green line in the figure. If the learning rate is high, the cost function could saturate at a value higher than the minimum value. This is represented by the red line in the figure. If the learning rate selected is very high, the cost function could continue to increase with iterations/epochs. An optimal learning rate is not easy to find for a given problem. Though getting the right learning is always a challenge, there are some well-researched methods documented to figure out optimal learning rates. Some of these techniques are discussed in the following sections. In all these techniques the fundamental idea is to vary the learning rate dynamically instead of using a constant learning rate.
Decaying Learning rate
In the decaying learning rate approach, it decreases with increase in epochs/iterations. The formula used is shown below:

In the above equation, o is the initial learning rate, is the decay rate and is the learning rate at a given Epoch number. Figure 3 shows the learning rate decay with the epoch number for different initial learning rates and decay rates.
Scheduled Drop Learning rate
Unlike the decay method, where the learning rate drops monotonously, in the drop method, the learning rate is dropped by a predetermined proportion at a predetermined frequency. The formula used to calculate for a given epoch is shown in the below equation:

In the above equation, o is the initial learning rate, ‘n’ is the epoch/iteration number, ‘D’ is a hyper-parameter which specifies by how much the learning rate has to drop, and ρ is another hyper-parameter which specifies the epoch-based frequency of dropping the learning rate. Figure 4 shows the variation with epochs for different values of ‘D’ and ‘ρ’.
The limitation with both the decay approach and the drop approach is that they do not evaluate if decreasing the learning rate is required or not. In both the methods, the learning rate decreases irrespective of difficulty involved in minimizing the cost function.
Adaptive Learning rate
In this approach, the learning rate increases or decreases based on the gradient value of the cost function. For higher gradient value, the learning rate will be smaller and for lower gradient value, the learning rate will be larger. Hence, the learning decelerates and accelerates respectively at steeper and shallower parts of the cost function curve. The formula used in this approach is shown in the below equation.

In the above equation, o is the initial learning rate and ‘sn’ is the momentum factor, which is calculated using below equation. ‘n’ is the epoch/iteration number

In the above equation, 𝛾 is a hyperparameter whose value is typically between 0.7 and 0.9. Note that in equation-7, momentum factor Sn is an exponentially weighted average of gradients. So not only the value of the current gradient is considered, but also the values of gradients from the previous epochs are considered to calculate the momentum factor. Figure 5 shows the idea behind the gradient adapted learning rate. When the cost function curve is steep, the gradient is large, and the momentum factor ‘Sn’ is larger. Hence the learning rate is smaller. When the cost function curve is shallow, the gradient is small and the momentum factor ‘Sn’ is also small. The learning rate is larger.
The gradient adapted learning rate approach eliminates the limitation in the decay and the drop approaches by considering the gradient of the cost function to increase or decrease the learning rate. This approach is widely used in training deep neural nets with stochastic gradient descent.
Cycling Learning Rate
In this approach, the learning rate varies between a base rate and a maximum rate cyclically. Figure 6 shows the idea behind this approach. The figure shows that the learning rate varies in a triangular form between the maximum and the base rates at a fixed frequency.
It is reported [1] that other forms such as sinusoidal or parabolic too yield similar results. The frequency of variation can be adjusted by setting the value of ‘step size’. The formula used in this approach is shown below.
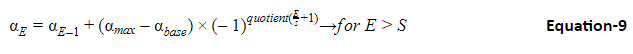
In the above equation, E is the learning rates for a given epoch, E is the epoch number, max and base are respectively the maximum and the base learning rates. S is the step size. Note that the above equation valid when E>S. for E≤S below equation can be used
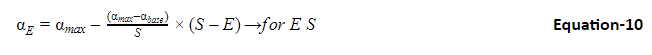
An important step in making this approach work is identifying the right base and the maximum learning rates. The process to identify these, referred to as ‘LR range test’ in [1] is; train the model for a few epochs allowing the learning rate to vary linearly starting from a small number. Capture the accuracy of the model for different learning rates and plot. The plot could look like the image shown in figure 7.
From the plot identify two learning rate values; 1) the value at which the accuracy starts to increase and 2) the value at which the accuracy begins to fluctuate or to decrease. The first point corresponds to the base learning rate, and the second point corresponds to the maximum learning rate. Figure 8 shows the comparison of model accuracy achieved with different learning rate approaches on CIFER-10 image dataset in a convolutional neural network (CNN). In the figure, ‘Original learning rate’ corresponds to a fixed learning rate, ‘Exponential’ corresponds to an exponential learning rate decay approach and ‘CLR’ corresponds to the cyclic learning rate approach. While the constant learning and the exponential approach seem to have taken close to 70000 iterations to achieve an accuracy of 81%, the cyclic learning rate seems to have taken close to 25000 iterations indicating close to 2.5 times quicker convergence.
In this article, the role of learning rate as a hyper-parameter is discussed, highlighting the role it plays in the time taken to train a model and the prediction accuracy achieved by the model. Some of the important aspects to remember are; using variable learning rate instead of a constant learning rate could help achieve higher accuracy in smaller training time. One of these or a combination of these techniques, especially the adaptive learning rate and the cyclic learning rate can be used in practical applications to train algorithms using the gradient descent method.
Contributed by: Arun K
References:
[1] Cyclical Learning Rates for Training Neural Networks
[2] Neural Network: Tricks of the Trade
[3] understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks
Find Machine Learning Course in Top Indian Cities
Chennai | Bangalore | Hyderabad | Pune | Mumbai | Delhi NCROur Machine Learning Courses
Explore our Machine Learning and AI courses, designed for comprehensive learning and skill development.
| Program Name | Duration |
|---|---|
| MIT No code AI and Machine Learning Course | 12 Weeks |
| MIT Data Science and Machine Learning Course | 12 Weeks |
| Data Science and Machine Learning Course | 12 Weeks |








