
Introduction
Innovations in the dynamic field of artificial intelligence are frequently evaluated by how well they address practical problems. In 2012, a convolutional neural network (CNN) called AlexNet won the coveted ImageNet competition. This was a milestone in the journey of AlexNet.
Why did this matter so much? Image identification was a complex problem to solve at the time. Even basic objects in images were complex for machines to recognize, let alone the complexities of a 1000-class dataset like imageNet.
Then came AlexNet, which significantly outperformed rivals because of its novel architecture and unparalleled precision. This triumph ushered in the current deep learning era and paved the way for artificial intelligence's rapid expansion.
This article delves deeply into AlexNet's design, reveals its groundbreaking breakthroughs, and examines its enduring impact on artificial intelligence. Hold on tight because this is where the real voyage of deep learning started.
What is ALexNet?
AlexNet is a convolutional neural network (CNN) that was introduced in 2012. It was designed to recognize images and has been used in many fields, including robotics, medical imaging, and autonomous vehicles.
AlexNet was created to handle challenging picture recognition jobs effectively. For Example, Imagine teaching a child to recognize objects like apples and oranges. Initially, you’d show them many pictures of these objects.
Before AlexNet, we had to manually describe the characteristics of each object to the 'machine child'. AlexNet changed this by allowing the machine to learn these features on its own, similar to how children learn.
MIT Data Science and Machine Learning Course
Unlock the power of data. Build hands-on data science and machine learning skills to drive innovation in your career.
Background and Context
Prior to AlexNet, feature engineering was a significant component of machine learning techniques. Engineers manually designed features for algorithms to identify patterns. This process was time-consuming, prone to mistakes, and limited in scalability. Because of data and computational limitations, the idea of deep learning using artificial neural networks to learn features automatically was not novel and remained speculative.
Everything changed in 2009 with the release of the ImageNet dataset. Developed by Fei-Fei Li and her team, ImageNet provided a vast collection of labeled photos across 1,000 categories, creating an ideal environment for testing machine learning models. However, the dataset's scale and complexity were beyond the capabilities of traditional methods.
In 2012, three researchers—Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever—introduced the AlexNet model, inspired by the human visual system. Using convolutional neural networks and leveraging the computational power of GPUs, AlexNet demonstrated that machines could achieve superhuman performance in image classification when designed effectively.
Suggested Read: What is Machine Learning?
AlexNet Architecture
Let's dissect the design and operation of AlexNet to discover what made it revolutionary.
AlexNet has eight layers: three fully connected layers for classification and five convolutional layers for feature extraction. Each layer gradually converts the input image into insightful predictions.
ReLU activation, dropout, and overlapping pooling are among the innovations that set AlexNet apart and addressed the shortcomings of previous models.
Layer-by-layer Explanation
- Input Layer:
- Size: AlexNet used RGB images with dimensions of 227x227x3.
- Preprocessing: To improve feature extraction and reduce redundancy, images were normalized.
- Convolutional Layers: These layers use filters to extract elements, including forms, edges, and textures. While deeper layers concentrated on finer details, early layers recorded larger patterns. Large filters (11x11) were used in AlexNet's first convolutional layer, a daring decision for gathering global data.
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(96, (11, 11), strides=(4, 4), activation='relu', input_shape=(227, 227, 3)),
layers.MaxPooling2D((3, 3), strides=(2, 2))
])
print(model.summary())

- ReLu Activation: AlexNet employed Rectified Linear Units (ReLU), which added non-linearity and accelerated training, in contrast to conventional activation functions like sigmoid or tanh. ReLu played a crucial role in making deeper networks possible by addressing the vanishing gradient issue.
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 100)
relu = np.maximum(0, x)
plt.plot(x, relu, label='ReLU')
plt.title("ReLU Activation")
plt.legend()
plt.show()
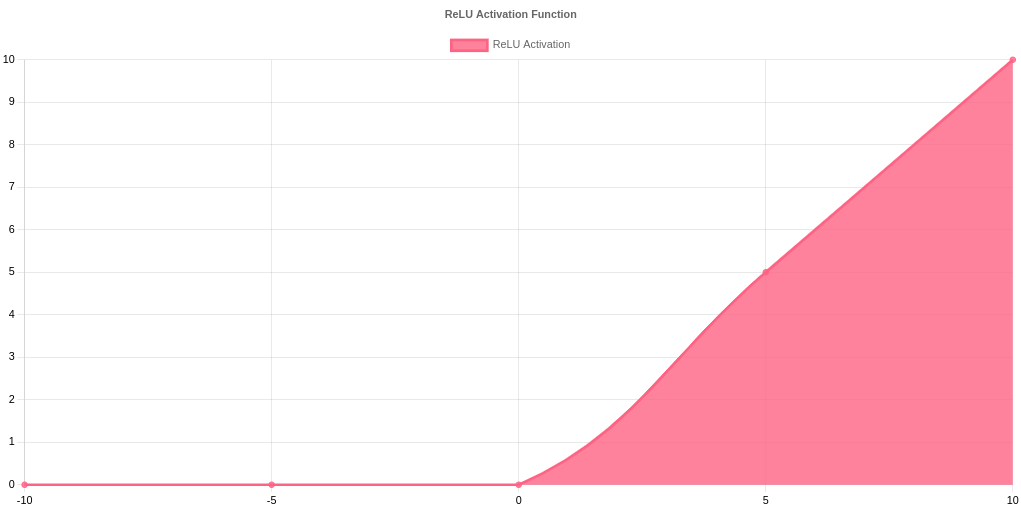
- Pooling Layers: To minimize spatial dimensions while maintaining essential features, AlexNet used overlapping max-pooling layers. A small regularization impact brought forth by overlapping pooling enhanced generalization and decreased overfitting.
# overlapping pooling with code
model.add(layers.MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
- Fully Connected Layer: The last layers mapped high-level feature mappings to class probabilities. These intricately linked layers identified intricate patterns in the data.
- Output Layer: A softmax algorithm generated probabilities for 1000 ImageNet classes. The final forecast was made for the class with the highest probability.
model.add(layers.Dense(1000, activation='softmax'))
By layering these components, AlexNet outperformed its competitors in ImageNet competition, with a record-breaking top-5 error rate of 15.3%.
Key Innovations and Their Significance
Modern deep learning was made possible by its groundbreaking innovations:
- ReLU Activation: In contrast to sigmoid or tanh functions, ReLU's introduction of non-linearity solved the vanishing gradient issue and greatly accelerated training.
- Dropout: one of the main issues with deep networks was overfitting. Dropout, a technique used by AlexNet to randomly deactivate neurons during training, enhanced generalization and added a layer of regularization. Code Example:
model.add(layers.Dropout(0.5))
- GPU Acceleration: Due to CPU limitations, AlexNet could not have been trained on the large ImageNet dataset. However, AlexNet significantly decreased training time and illustrated the significance of hardware in AI by utilizing GPUs for parallel processing.
- Overlapping Pooling: In contrast to conventional pooling, overlapping pooling added a small amount of regularization, which enhanced the model's capacity to generalize to fresh data.
- Data Augmentation: To increase resilience and decrease overfitting, AlexNet artificially expanded the dataset using data augmentation techniques like flipping and random cropping. Code Example:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=30,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True
)
These developments expanded the potential of deep learning and went beyond simple technological advancements.
Impact of AlexNet's Success
With far-reaching effects, AlexNet's breakthrough signalled a sea change in AI history:
- Catalyst for Deeper Architectures: AlexNet's success sparked the creation of deeper and more intricate structures, such as VGGNet, ResNet, and Inception, which all pushed the limits of neural networks.
- Revolutionizing other fields: AlexNet's advancements went beyond picture identification, including natural language processing, driverless cars, and medical imaging. Deep learning made seemingly impossible tasks possible.
- Hardware Acceleration Revolution: AlexNet sparked the creation of TPUs (Tensor Processing Units) and other AI accelerators by demonstrating the effectiveness of GPUs in training deep networks.
- Shift in AI Research: AlexNet's success signalled a shift in AI research from conventional machine learning methods to deep learning, making CNNs the preferred method for image-related tasks.
- Reshaping AI Education: AlexNet inspired a new generation of researchers and educators to study deep learning. Its methods were included in AI courses at universities, inspiring the upcoming generation of AI professionals and enthusiasts.
Suggested Read: Applications of Deep Learning
Challenges faced by AlexNet
Even though AlexNet was incredibly successful, there were some challenges:
- Computational Demands: AlexNet's training required high-end GPUs, which were costly and out of reach for many researchers at the time.
- Overfitting: While data augmentation and dropout helped to reduce overfitting, generalization on smaller datasets remained difficult.
- Data Dependency: The significance of data curation and labelling was underestimated because AlexNet's success was dependent on sizable, annotated datasets such as ImageNet.
- Energy Consumption: The computational energy required to train big models, such as AlexNet, raised concerns about scalability and environmental effects.
- Interpretability: In spite of its achievements, AlexNet brought to light a crucial problem in deep learning: comprehending the reasoning behind models' decisions. This sparked research into explainable AI.
These difficulties highlighted the necessity of ongoing innovation in the accessibility and effectiveness of the concept.
AlexNet's win in the 2021 ImageNet competition was a significant turning point in artificial intelligence. Its cutting-edge architecture, which included GPU acceleration, dropout, and ReLu activation, helped close the gap between theoretical research and actual application.
In addition to winning a contest, AlexNet laid the groundwork for the AI revolution. The methods it introduced continue to influence contemporary deep learning, from generative models to object detection.
Related Free Courses:








