
- What is a Convolutional Neural Network?
- How CNN Works: Key Components
- Why Use CNN in Deep Learning?
- Applications of Convolutional Neural Networks
- How CNN Differs from Traditional Neural Networks
- Challenges and Limitations of CNNs
- Future of CNNs in AI and Deep Learning
- Conclusion
- Frequently Asked Questions(FAQ's)
Convolutional neural networks (CNN) have revolutionized deep learning operations through their capability to analyze images, which led machines toward visual data comprehension.
Their ability to detect patterns, edges, and textures makes them essential for computer vision. From image recognition to self-driving cars, CNNs power key AI innovations.
Let's explore their architecture, functioning, and applications in deep learning.
What is a Convolutional Neural Network?
Convolutional neural network is a deep learning model designed to process grid-based data inputs including images and videos. Unlike traditional fully connected neural networks, CNNs use a unique structure that mimics how the human brain processes visual information.
The fundamental building blocks of CNN networks consist of layers that use convolution to spot vital image characteristics.
Using its abilities the network finds image objects and detects their arrange and surface structure without human help to select features.
How CNN Works: Key Components
A convolutional neural network consists of multiple layers that work together to extract and analyze features from input data. Let's break down the essential components:
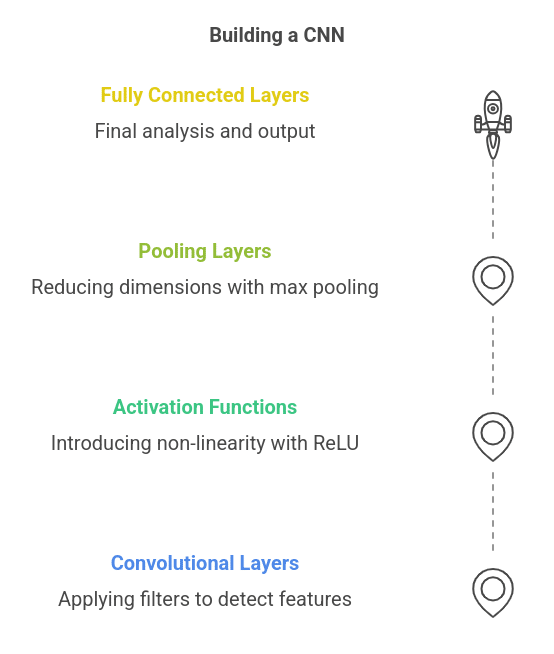
a) Convolutional Layers
The convolutional layer is the foundation of a CNN. It applies filters (kernels) to the input image, sliding across to detect specific features such as edges, textures, and patterns. These filters help the network learn spatial hierarchies, meaning lower layers detect simple patterns while deeper layers identify complex structures.
b) Activation Functions (ReLU)
After applying convolution, the Rectified Linear Unit (ReLU) activation function introduces non-linearity into the network. Since real-world data is highly complex, ReLU helps CNN learn better representations by transforming negative values into zero and keeping positive values unchanged.
c) Pooling Layers
Pooling layers reduce the spatial dimensions of feature maps while retaining important information. The most common method is max pooling, which selects the maximum value from a region of the feature map. This reduces computational complexity while making the network more robust to small variations in input images.
d) Fully Connected Layers
The network receives extracted features from all its convolutional and pooling layers after that it sends them into the fully connected layer. This top layer receives extracted information for advanced analysis then provides the final output.
Why Use CNN in Deep Learning?
The use of CNNs has revolutionized deep learning research because they can find important image qualities without human direction. People use CNNs because these networks have several critical advantages like:
- Efficient Feature Extraction – CNNs learn hierarchical patterns, making them highly effective for image-related tasks.
- Reduced Computational Complexity – The use of shared weights (filters) and pooling layers significantly lowers the number of parameters compared to traditional neural networks.
- High Accuracy in Image Recognition – CNNs include medical diagnostics systems, autonomous driving systems and facial recognition technology.
Applications of Convolutional Neural Networks
CNN architectures serve as a primary deep learning method that excels in detecting images and patterns during computational processing, particularly those involving image and pattern recognition. Here are some key areas where CNNs excel:
a) Image Recognition
Convolutional neural networks (CNNs) are a frequent application for image recognition. Platforms like Google Photos and Facebook use CNNs to identify and categorize images based on objects, faces, and scenes. CNNs can distinguish between thousands of categories with high accuracy.
b) Object Detection
CNNs are the backbone of object detection systems used in security surveillance, self-driving cars, and facial recognition technologies. Models like YOLO (You Only Look Once) and Faster R-CNN use convolutional layers to detect and classify multiple objects in real-time.
Learn about object detection using TensorFlow and enhance your machine learning skills with this detailed guide.
c) Medical Imaging
Through medical imaging CNNs help healthcare professionals make disease diagnoses in the healthcare sector. CNN-based medical models execute X-ray and MRI and CT scan analyses to find medical inconsistencies including tumors infections and fractures more successfully than previous practices do.
d) Natural Language Processing (NLP)
Although CNNs are primarily used for image-related tasks, they are also applied in NLP tasks like text classification and sentiment analysis. By treating text as a 2D structure (word embeddings), CNNs can identify key phrases and context in a document.
Explore the world of Natural Language Processing and boost your expertise with this comprehensive Guide.
How CNN Differs from Traditional Neural Networks
Traditional artificial neural networks (ANNs) rely on fully connected layers, where every neuron is connected to all others in the next layer. This results in a large number of parameters and computational inefficiency, especially for high-dimensional data like images.
CNNs, on the other hand:
- Use convolutional layers to detect spatial hierarchies and patterns.
- Have local connectivity (not every neuron is connected to all others).
- Share weights (filters), reducing the number of parameters significantly.
- Utilize pooling layers to reduce dimensionality and improve efficiency.
Because of these advantages, CNNs outperform ANNs in image-processing tasks.
Learn more about different types of neural networks.
Challenges and Limitations of CNNs
Despite their advantages, CNNs come with specific challenges:
- High Computational Cost – Training deep CNN models requires significant processing power and memory, often relying on GPUs.
- Need for Large Datasets – CNNs perform best with large, labeled datasets. Small datasets can lead to overfitting.
- Lack of Interpretability – CNNs function as "black boxes," making it difficult to understand how they make specific decisions.
- Vulnerability to Adversarial Attacks – Small changes in input images can mislead CNNs, causing incorrect predictions.
Researchers continue to enhance CNN innovations because they want to overcome these difficulties.
Learn more about deep learning.
Future of CNNs in AI and Deep Learning
The future of CNN in deep learning looks promising, with advancements in:
- Capsule Networks – A potential improvement over CNNs that retains spatial hierarchies better.
- Efficient Architectures – Models like MobileNet and EfficientNet optimize CNNs for mobile and edge computing.
- Integration with Transformers – Combining CNNs with transformer models is enhancing vision-based AI applications.
Future advancements in image recognition healthcare robotics and additional fields will rely on advancements in CNNs.
Conclusion
The convolutional neural network has changed how deep learning deals with visual data by making machines better at recognizing images accurately. Computers use CNNs as an essential tool to advance applications in AI technology.
CNNs continue to develop to build more effective and smarter AI systems. Research progress will bring CNN technology into new deep learning systems to achieve better results.
Related Free Courses:
Frequently Asked Questions(FAQ's)
1. How do CNNs handle different image sizes?
CNNs can process images of varying sizes by using adaptive architectures such as global pooling layers or resizing images before feeding them into the network. Many CNN models require a fixed input size, so images are often preprocessed using padding or cropping.
2. Can CNNs be used for non-image data?
Yes! While CNNs are primarily used for image processing, they can also be applied to tasks like speech recognition, time-series analysis, and natural language processing (NLP) by treating sequential data as 2D representations (e.g., spectrograms for audio or word embeddings for text).
3. What are pre-trained CNN models, and why are they useful?
Pre-trained CNN models like VGG16, ResNet, and MobileNet are trained on large datasets (e.g., ImageNet) and can be fine-tuned for specific tasks. They help speed up training and improve accuracy, especially when labeled data is limited.
4. How do CNNs compare to Vision Transformers (ViTs)?
CNNs excel at learning local patterns through convolutional layers, while Vision Transformers (ViTs) focus on global attention mechanisms to capture long-range dependencies. ViTs are gaining popularity for tasks where understanding relationships between distant pixels is crucial.








