- Data Augmentation: Introduction
- Numerical Data Augmentation
- Image Augmentation for Computer Vision Applications
- Adversarial Training based Augmentation
- GAN based Augmentation
- Neural Style Transfer based Augmentation
- Text Augmentation Techniques for Natural Language Processing
Contributed by: Arun K
LinkedIn Profile: https://www.linkedin.com/in/arunsme/
Introduction to Data Augmentation
The prediction accuracy of the Supervised Deep Learning models is largely reliant on the amount and the diversity of data available during training. The relation between deep learning models and amount of training data required is analogous to that of the relation between rocket engines (deep learning models) and the huge amount of fuel (huge amounts of data) required for the rocket to complete its mission (success of the deep learning model).
DL models trained to achieve high performance on complex tasks generally have a large number of hidden neurons. As the number of hidden neurons increases, the number of trainable parameters also increases. The number of parameters in the State-of-the-art Computer Vision models such as RESNET (60M) and Inception-V3 (24M) is of the order of ten million.
In Natural Language Processing models such as BERT (340M), it is of the order of a hundred million. These deep learning models trained to perform complex tasks such as object detection or language translation with high accuracy have a large number of tunable parameters. They need a large amount of data to learn the values for a large number of parameters during the training phase.
In simple terms, the amount of data required is proportional to the number of learnable parameters in the model. The number of parameters is proportional to the complexity of the task.
Oftentimes, when working on specific complex tasks such as classifying a weed from a crop, or identifying the novelty of a patient, it is very hard to get large amounts of data required to train the models. Though transfer learning techniques could be used to great effect, the challenges involved in making a pre-trained model to work for specific tasks are tough.
Another way to deal with the problem of limited data is to apply different transformations on the available data to synthesize new data. This approach of synthesizing new data from the available data is referred to as ‘Data Augmentation’.
Data augmentation can be used to address both the requirements, the diversity of the training data, and the amount of data. Besides these two, augmented data can also be used to address the class imbalance problem in classification tasks.
The questions that come to the mind are; Does data augmentation work? Do we really get better performance from the models when we use augmented data for training? Table 1 shows a few case studies indicating the effect of data augmentation on model performance for different applications.
Table 1. model performance for different applications with and without data augmentation
| Application | Performance without Augmentation | Performance with Augmentation | Augmentation method |
| Image classification | 57% | 78.6% | Simple Image based |
| Image classification | 57% | 85.7% | GAN based |
| NMT | 11 BLEU | 13.9 BLEU | Translation data augmentation |
| Text classification | 79% | 87% | Easy Data Augmentation |
The answer to the questions is an assured and cautious ‘yes’: assured since several case studies indicate that the performance improves and cautious since different augmentation techniques used affect the scale of improvement differently.
Numerical Data Augmentation
The augmentation techniques used in deep learning applications depends on the type of the data. To augment plain numerical data, techniques such as SMOTE or SMOTE NC are popular. These techniques are generally used to address the class imbalance problem in classification tasks.
For unstructured data such as images and text, the augmentation techniques vary from simple transformations to neural network generated data, based on the complexity of the application. The augmentation techniques for images and text type data are discussed separately in the following sections.
Also Read: Image Recognition using Python
Image Augmentation for Computer Vision Applications
Amongst the popular deep learning applications, computer vision tasks such as image classification, object detection, and segmentation have been highly successful. Data augmentation can be effectively used to train the DL models in such applications. Some of the simple transformations applied to the image are; geometric transformations such as Flipping, Rotation, Translation, Cropping, Scaling, and color space transformations such as color casting, Varying brightness, and noise injection. Figure 1. Shows the original image and the images after applying some of these transformations. The python code used for applying the transformations is shown in appendix-1.
Figure 1. Some of common image transformations applied for data augmentation
Geometric transformations work well when positional biases are present in the images such as the dataset used for facial recognition. The color space transformation can help address the challenges connected to illumination or lighting in the images. Table 2 shows the impact of simple transformations on the accuracy of the model on the Caltech101 dataset.
Table 2. model performance improvement after applying specific transformations.
| Transformation | Top-1 accuracy (%) |
| None (baseline) | 48.13 ± 0.42 |
| Flipping | 49.73 ± 1.13 |
| Rotating | 50.80 ± 0.63 |
| Cropping | 61.95 + 1.01 |
| Color Jittering | 49.57 ± 0.53 |
| Edge Enhancement | 49.29 + 1.16 |
| Fancy PCA | 49.41 ± 0.84 |
Some of the popular open-source python packages used for image augmentation packages are Albumentations, Keras ImageDataGenerator, OpenCV, Skimage. The simple transformations shown in figure-1 can be achieved using any of these packages. Besides the simple ones, each package offers some custom transformations.
In reality, images could be shot in diverse conditions. The simple transformations listed above may not be able to account for all the variations in the conditions. Another disadvantage with the simple transformations is that they could lead to changes in geometry or lighting that can cause the objects in an image to lose the original features. Deep Neural Network-based methods such as Adversarial Training, Generative Adversarial Networks (GAN), and Neural Style Transfer are being researched and used to apply more realistic transformations. An overview of each of these techniques is presented.
Adversarial Training based Augmentation
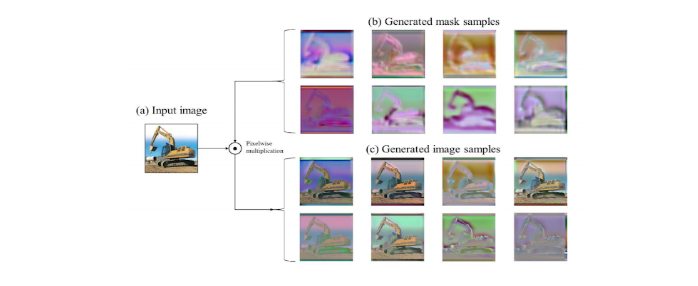
In Adversarial training, the objective is to transform the images to deceive a deep-learning model to the extent that the model fails to correctly analyze it. Such transformed images can be used as training data to compensate for the weaknesses in the deep-learning model. In simple terms, the method learns to generate masks which when applied to the input image, generated different augmented images. Figure 2 shows an instance of the masks generated, the input image, and the augmented images.
GAN based Augmentation
This is used to synthesize images for data augmentation. It consists of two simultaneously trained neural networks: the generator and the discriminator. The goal of the generator is to generate fake images from the latent space and the goal of the discriminator is to distinguish the synthetic fake images from the real images. Figure 3 shows the original and the generated images from GAN for pest classification.

Also Read: Introduction to GANs
Neural Style Transfer based Augmentation
In Neural style transfer, Deep Neural Networks are trained to extract the content from one image and style from another image and compose the augmented image using the extracted content and style. The augmented image is transformed to look like the input image, but “painted” in the style of the style image. Figure 4 shows augmented images generated using neural style transfer.

The above-mentioned transformations can be applied in ‘offline’ or the ‘online’ modes depending on the size of the training data. In the offline mode, the transformed image files are stored and fed to the model during training. In the online model, the transformations are applied on the fly and the mini-batch is prepared to train the model. The online method is suitable for large data sets.
With several techniques available to augment images, choosing the right set of augmentation techniques for a custom application remains a challenge. The current approach to find the right combination of transformations is to use the ‘search-stop’ method until the desired performance is achieved. Alternatively, learning augmentation policies using deep reinforced learning could be explored.
Text Augmentation Techniques for Natural Language Processing
While the use of augmented data in computer vision applications is very popular and standardized, the data augmentation techniques in NLP applications are still in the exploratory phase. This is largely due to the complexity involved in language processing. Some of the currently popular techniques are discussed and the links to implementations are provided
A popular augmentation technique in NLP referred to as non-conditional augmentation, is word replacement. In this technique, the synonyms of words or phrases in a sentence are found and replaced. The problem associated with this approach is that not all the words have synonyms and sometimes replacement by synonyms could lead to totally different meanings. For instance, if we look at the review for a movie- ‘A Black comedy with a social message’, the sentiment associated is positive. The augmented form of this review could be- ‘An obscure humor with communal message’. The sentiment indicated by the augmented review is the opposite. Using the augmented sentence to train a sentiment classifier model with the positive-label will negatively impact the performance. This is referred to as a class-label preservation problem.
To address the class-label preservation issue in unconditional augmentation, conditional augmentation techniques using pre-trained language models such as BERT, GP2, and BART as generator models are proposed. In this approach, a dataset for sentiment classification, intent classification, and question classification is used. The datasets are preconditioned in two ways referred to as prepend and expand. In both cases, the class label is appended to the description sentence. The difference is in the fact that the class label is not added to the vocabulary in the prepend approach and it is added to the vocabulary in extend approach. Once the data is preprocessed by either prepend or the extended method, the language model is fine-tuned to predict the class labels and the randomly masked words in the sentence. The fine-tuned models are used for augmented data generation. The code associated with this method is available on varying-Github.
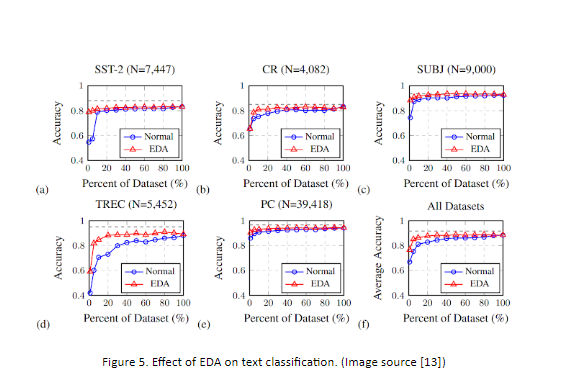
Some of the other data augmentation techniques that are effectively used for text classification purposes are; Random Insertion, Random swap, and Random deletion. This group of techniques along with Synonym Replacement is referred to as Easy Data Augmentation (EDA). Figure 5 shows the prediction accuracy of an RNN classifier with and without augmented data. The amount of original data set used during the training is also shown. The plots indicate that when a lower percentage of the original data is used, the performance of the model is significantly higher with data augmentation.
The results are shown for classification tasks on five different data sets: 1) SST-2: Stanford Sentiment Treebank, 2) CR: customer reviews, 3) SUBJ: subjectivity/objectivity dataset, 4) TREC: question type dataset 5) PC: Pro-Con dataset. The references to all these datasets are provided in. The EDA technique is found to be specifically useful on smaller dataset. The code associated with this method is available on jasonwei20-Github.
In this article, the need and the impact of data augmentation on supervised deep learning models are articulated. Different techniques for augmenting numerical data, images, and text data are presented. Some of the popular image augmentation techniques are discussed and the resulting images are shown. The limitation of simple text augmentation technique has been highlighted and the workaround techniques have been highlighted. The effect of text augmentation on small datasets for text classification is highlighted. Some closing points are; data augmentation serves as an effective way to develop robust high-performance deep learning models. Developing effective data augmentation techniques needs thorough research about the problem, domain knowledge, and creativity.
If you found this helpful and wish to learn more, join Great Learning Academy's free courses!