- An Introduction to Artificial Neural Network
- Types of Neural Networks
- A. Perceptron
- B. Feed Forward Neural Networks
- C. Multilayer Perceptron
- D. Convolutional Neural Network
- E. Radial Basis Function Neural Networks
- F. Recurrent Neural Networks
- G. Sequence to sequence models
- H. Modular Neural Network
- Conclusion
- FAQs
- Must Read
Neural networks are like the brain of AI, designed to learn and solve problems just like humans do. In this blog, we delve into the fundamentals of neural networks and their types, exploring how they operate.
Whether you're new to AI or looking to deepen your understanding, this guide will help you grasp the basics and see how these networks function. If you're serious about advancing your career in AI, obtaining the best AI certification can be a game changer, offering a comprehensive understanding of neural networks, machine learning, deep learning, and more. This will ensure you're equipped with the right skills to thrive in this fast-evolving field.
Different Types of Neural Networks Models
The nine types of neural network architectures are:
- Perceptron
- Feed Forward Neural Network
- Multilayer Perceptron
- Convolutional Neural Network
- Radial Basis Functional Neural Network
- Recurrent Neural Network
- LSTM - Long Short-Term Memory
- Sequence to Sequence Models
- Modular Neural Network

An Introduction to Artificial Neural Network
Artificial neural networks (ANNs) are a fundamental concept in deep learning within artificial intelligence. They are crucial in handling complex application scenarios that traditional machine-learning algorithms may struggle with. Here's an overview of how neural networks operate and their components:
- Inspired by Biology
ANNs are inspired by biological neurons in the human brain. Just as neurons activate under specific conditions to trigger actions in the body, artificial neurons in ANNs activate based on input data.
- Structure of ANNs
ANNs consist of layers of interconnected artificial neurons. These neurons are organized into layers, each performing specific computations using activation functions to decide which signals to pass onto the next layer.
- Training Process
During training, ANNs adjust internal parameters known as weights. These weights are initially random and are optimized through a process called backpropagation, where the network learns to minimize the difference between predicted and actual outputs (loss function).
Components of Neural Networks:
- Weights: Numeric values multiplied by inputs and adjusted during training to minimize error.
- Activation Function: Determines whether a neuron should be activated ("fired") based on its input, introducing non-linearity crucial for complex mappings.
Layers of Neural Networks
- Input Layer: Receives input data and represents the dimensions of the input vector.
- Hidden Layers: Intermediary layers between input and output that perform computations using weighted inputs and activation functions.
- Output Layer: Produces the neural network's final output after processing through the hidden layers.
Neural networks are powerful tools for solving complex problems. They can learn and adapt to data, and they have wide-ranging applications across industries. This makes them essential for anyone looking to deepen their skills in AI and deep learning.
Check Out Different NLP Courses
Build a successful career specializing in Neural Networks and Artificial Intelligence.
- Projected 25% increase in job creation by 2030
- Over 10,000 job openings available
Start your journey towards a rewarding career in AI and Neural Networks today.
Enroll Now
Post Graduate Program in AI & Machine Learning: Business Applications
Master in-demand AI and machine learning skills with this executive-level AI course—designed to transform professionals into strategic tech leaders.
Types of Neural Networks
There are many types of neural networks available or that might be in the development stage. They can be classified depending on their:
- Structure
- Data flow
- Neurons used and their density
- Layers and their depth activation filters

Now, let's discuss the different types of ANN (Artificial Neural Networks)
A. Perceptron
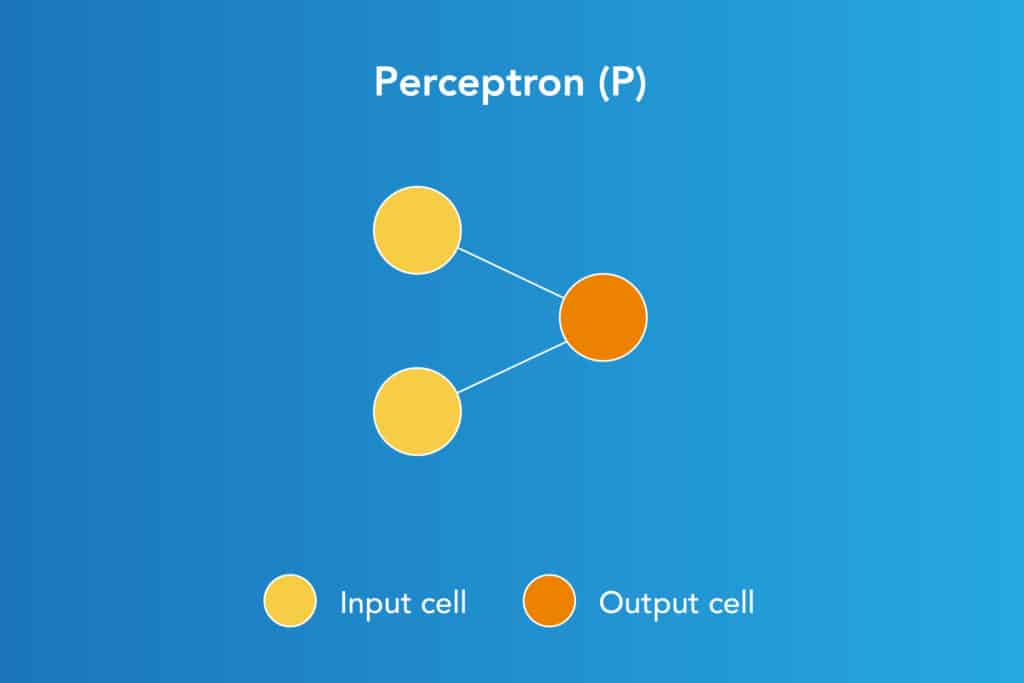
The Perceptron model, developed by Minsky and Papert, is one of the simplest and earliest neuron models. As the basic unit of a neural network, it performs computations to detect features or patterns in input data, making it a foundational tool in machine learning.
Functionality:
The Perceptron accepts weighted inputs and applies an activation function to produce an output, which is the final result.
It is also called a Threshold Logic Unit (TLU), highlighting its role in making binary decisions based on input data.
The Perceptron is a supervised learning algorithm primarily used for binary classification tasks. It distinguishes between two categories by defining a hyperplane within the input space. This hyperplane is represented mathematically by the equation:
w⋅x+b=0
Here, w represents the weight vector, x denotes the input vector, and b is the bias term. This equation delineates how the Perceptron divides the input space into distinct categories based on the learned weights and bias.
Advantages of Perceptron
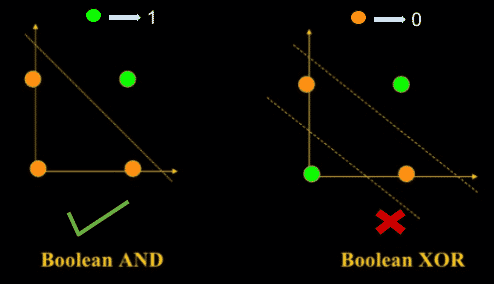
Perceptrons can implement Logic Gates like AND, OR, or NAND.
Disadvantages of Perceptron
Perceptrons can only learn linearly separable problems such as boolean AND problem. For non-linear problems such as the boolean XOR problem, it does not work.
Check out this free neural networks course to understand the basics of Neural Networks
B. Feed Forward Neural Networks
Feed Forward Neural Networks (FFNNs) are foundational in neural network architecture, particularly in applications where traditional machine learning algorithms face limitations.
They facilitate tasks such as simple classification, face recognition, computer vision, and speech recognition through their uni-directional flow of data.
- Structure
FFNNs consist of input and output layers with optional hidden layers in between. Input data travels through the network from input nodes, passing through hidden layers (if present), and culminating in output nodes.
- Activation and Propagation
These networks operate via forward propagation, where data moves in one direction without feedback loops. Activation functions like step functions determine whether neurons fire based on weighted inputs. For instance, a neuron may output 1 if its input exceeds a threshold (usually 0), and -1 if it falls below.
FFNNs are efficient for handling noisy data and are relatively straightforward to implement, making them versatile tools in various AI applications.
From basics to advanced insights, discover everything about computer vision.
Read our blog: What is Computer Vision? Know Computer Vision Basic to Advanced & How Does it Work?
Advantages of Feed Forward Neural Networks
- Less complex, easy to design & maintain
- Fast and speedy [One-way propagation]
- Highly responsive to noisy data
Disadvantages of Feed Forward Neural Networks:
- Cannot be used for deep learning [due to absence of dense layers and back propagation]
C. Multilayer Perceptron
The Multi-Layer Perceptron (MLP) represents an entry point into complex neural networks, designed to handle sophisticated tasks in various domains such as:
- Speech recognition
- Machine translation
- Complex classification tasks
MLPs are characterized by their multilayered structure, where input data traverses through interconnected layers of artificial neurons.
This architecture includes input and output layers alongside multiple hidden layers, typically three or more, forming a fully connected neural network.
Operation:
- Bidirectional Propagation
Utilizes forward propagation (for computing outputs) and backward propagation (for adjusting weights based on error).
- Weight Adjustment
During backpropagation, weights are optimized to minimize prediction errors by comparing predicted outputs against actual training inputs.
- Activation Functions
Nonlinear functions are applied to the weighted inputs of neurons, enhancing the network's capacity to model complex relationships. The output layer often uses softmax activation for multi-class classification tasks.
Advantages on Multi-Layer Perceptron
- Used for deep learning [due to the presence of dense fully connected layers and back propagation]
Disadvantages on Multi-Layer Perceptron:
- Comparatively complex to design and maintain
Comparatively slow (depends on number of hidden layers)
Build a successful career specializing in Neural Networks and Artificial Intelligence.
- Projected 25% increase in job creation by 2030
- Over 10,000 job openings available
Start your journey towards a rewarding career in AI and Neural Networks today.
Enroll Now
D. Convolutional Neural Network
A Convolutional Neural Network (CNN) specializes in tasks such as:
- Image processing
- Computer vision
- Speech recognition
- Machine translation
CNNs differ from standard neural networks by incorporating a three-dimensional arrangement of neurons, which is particularly effective for processing visual data. The key components include:
Structure
- Convolutional Layer
The initial layer processes localized regions of the input data, using filters to extract features like edges and textures from images.
- Pooling Layer
Follows convolution to reduce spatial dimensions, capturing essential information while reducing computational complexity.
- Fully Connected Layer
Concludes the network, using bidirectional propagation to classify images based on extracted features.
Operation
- Feature Extraction
CNNs utilize filters to extract features from images, enabling robust recognition of patterns and objects.
- Activation Functions
Rectified linear units (ReLU) are common in convolution layers to introduce non-linearity and enhance model flexibility.
- Classification
Outputs from convolution layers are processed through fully connected layers with nonlinear activation functions like softmax for multi-class classification.
Quick check - Deep Learning Course
Advantages of Convolution Neural Network:
- Used for deep learning with few parameters
- Less parameters to learn as compared to fully connected layer
Disadvantages of Convolution Neural Network:
- Comparatively complex to design and maintain
- Comparatively slow [depends on the number of hidden layers]
MIT Data Science and Machine Learning Course
Unlock the power of data. Build hands-on data science and machine learning skills to drive innovation in your career.
E. Radial Basis Function Neural Networks
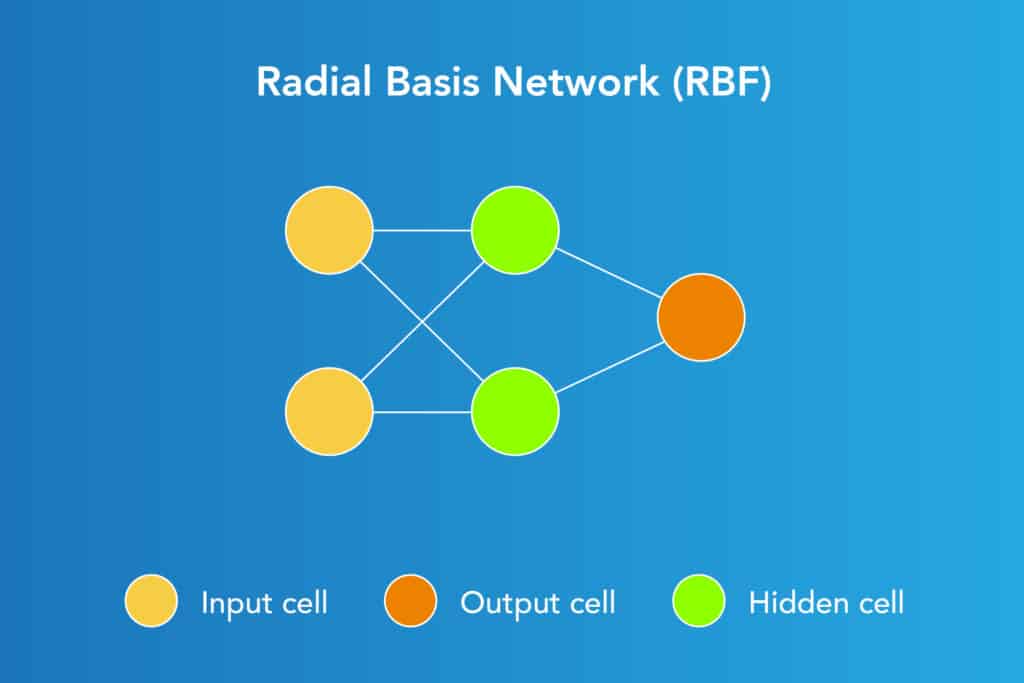
A Radial Basis Function Network comprises an input layer followed by RBF neurons and an output layer with nodes corresponding to each category. During classification, the input's similarity to training set data points, where each neuron stores a prototype, determines the classification.
When classifying a new n-dimensional input vector:
Each neuron computes the Euclidean distance between the input and its prototype.
For instance, if we have classes A and B, the input is closer to class A prototypes than class B, leading to classification as class A.
Each RBF neuron measures similarity by outputting a value from 0 to 1. The response is maximal (1) when the input matches the prototype and diminishes exponentially (towards 0) with increasing distance. This response forms a bell curve pattern characteristic of RBF neurons.
Quick check - NLP course
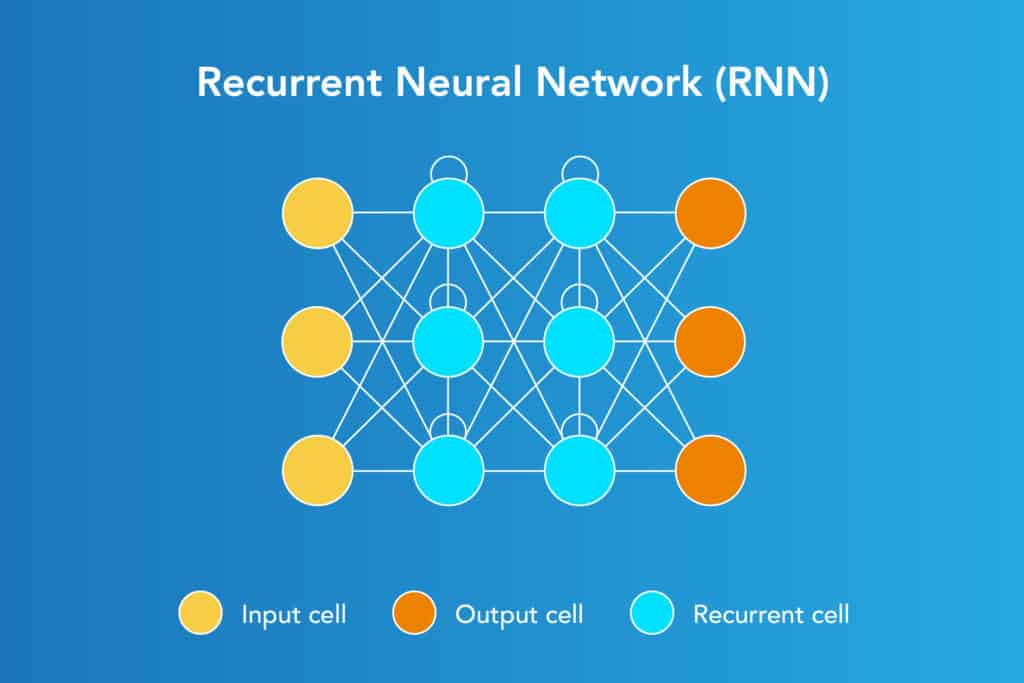
F. Recurrent Neural Networks
Applications of Recurrent Neural Networks
- Text processing like auto suggest, grammar checks, etc.
- Text to speech processing
- Image tagger
- Sentiment Analysis
- Translation
Designed to save the output of a layer, Recurrent Neural Network is fed back to the input to help in predicting the outcome of the layer. The first layer is typically a feed forward neural network followed by recurrent neural network layer where some information it had in the previous time-step is remembered by a memory function. Forward propagation is implemented in this case. It stores information required for it's future use. If the prediction is wrong, the learning rate is employed to make small changes. Hence, making it gradually increase towards making the right prediction during the backpropagation.
Advantages of Recurrent Neural Networks
- Model sequential data where each sample can be assumed to be dependent on historical ones is one of the advantage.
- Used with convolution layers to extend the pixel effectiveness.
Disadvantages of Recurrent Neural Networks
- Gradient vanishing and exploding problems
- Training recurrent neural nets could be a difficult task
- Difficult to process long sequential data using ReLU as an activation function.
Build a successful career specializing in Neural Networks and Artificial Intelligence.
- Projected 25% increase in job creation by 2030
- Over 10,000 job openings available
Start your journey towards a rewarding career in AI and Neural Networks today.
Enroll Now
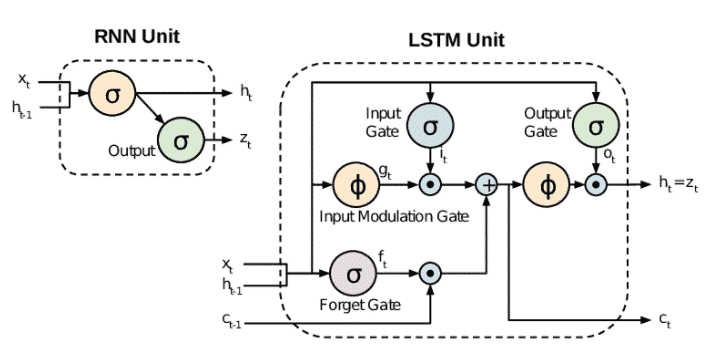
Improvement over RNN: LSTM (Long Short-Term Memory) Networks
LSTM networks are a type of RNN that uses special units in addition to standard units. LSTM units include a 'memory cell' that can maintain information in memory for long periods of time. A set of gates is used to control when information enters the memory when it's output, and when it's forgotten. There are three types of gates viz, Input gate, output gate and forget gate. Input gate decides how many information from the last sample will be kept in memory; the output gate regulates the amount of data passed to the next layer, and forget gates control the tearing rate of memory stored. This architecture lets them learn longer-term dependencies
This is one of the implementations of LSTM cells, many other architectures exist.
G. Sequence to sequence models
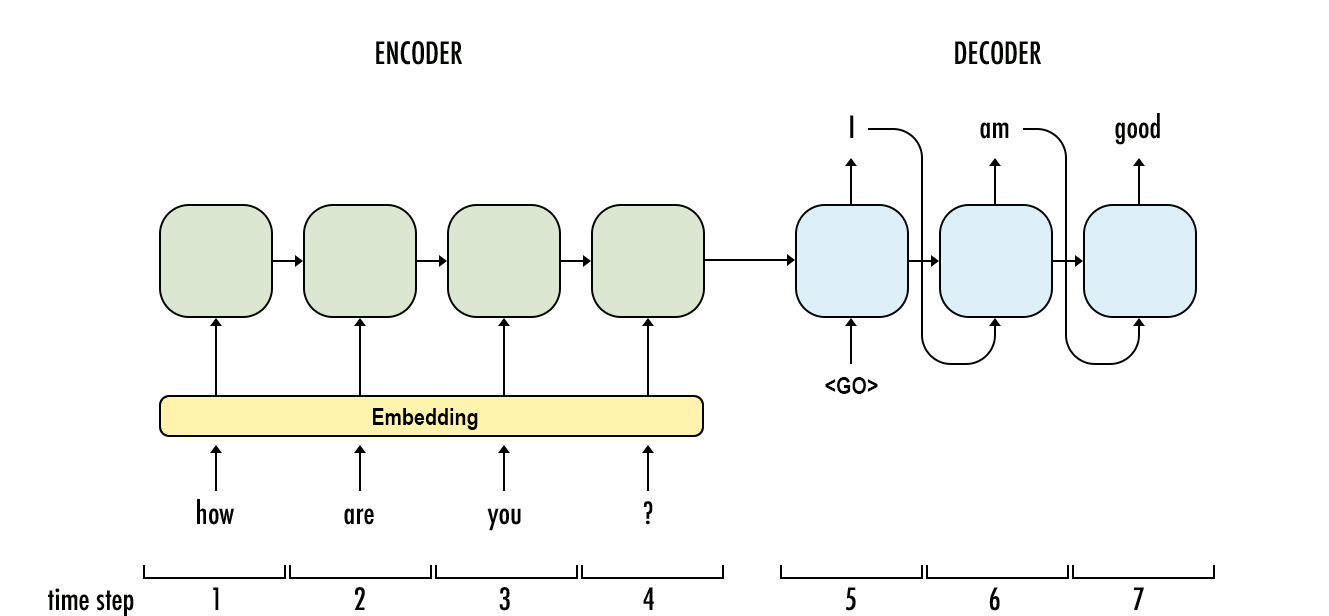
A sequence to sequence model consists of two Recurrent Neural Networks. Here, there exists an encoder that processes the input and a decoder that processes the output. The encoder and decoder work simultaneously - either using the same parameter or different ones. This model, on contrary to the actual RNN, is particularly applicable in those cases where the length of the input data is equal to the length of the output data. While they possess similar benefits and limitations of the RNN, these models are usually applied mainly in chatbots, machine translations, and question answering systems.
Also read the Top 5 Examples of How IT Uses Analytics to Solve Industry Problems.
H. Modular Neural Network
Applications of Modular Neural Network
- Stock market prediction systems
- Adaptive MNN for character recognitions
- Compression of high level input data
A modular neural network has a number of different networks that function independently and perform sub-tasks. The different networks do not really interact with or signal each other during the computation process. They work independently towards achieving the output.

As a result, a large and complex computational process are done significantly faster by breaking it down into independent components. The computation speed increases because the networks are not interacting with or even connected to each other.
Advantages of Modular Neural Network
- Efficient
- Independent training
- Robustness
Disadvantages of Modular Neural Network
- Moving target Problems
Boost your neural network training with top Free Data Sets for Analytics/Data Science Project.
Conclusion
This list provides a springboard for your database management system project endeavors. Don't be afraid to get creative and explore project ideas that pique your interest. You could even combine elements from different projects to create a unique and challenging experience.
For instance, imagine building a mobile app for a university library management system that allows students to search for books, check their borrowing history, and even receive notifications for overdue items – all through the convenience of their smartphones.
The database project possibilities for students are truly endless!
If you have any queries, feel free to reach out. Keep learning and keep upskilling with online courses with certificates at Great Learning Academy.
To gain deep expertise in different neural network architectures and prepare for high-demand roles in AI and ML, consider enrolling in the Great Learning PG Program in Artificial Intelligence and Machine Learning.
This program equips you with the understanding of all types of neural networks and the necessary skills required to excel in today's hottest AI and ML-based job market, offering opportunities for lucrative careers.
FAQs
The different types of neural networks are:
Perceptron
Feed Forward Neural Network
Multilayer Perceptron
Convolutional Neural Network
Radial Basis Functional Neural Network
Recurrent Neural Network
LSTM – Long Short-Term Memory
Sequence to Sequence Models
Modular Neural Network
Neural Networks are artificial networks used in Machine Learning that work in a similar fashion to the human nervous system. Many things are connected in various ways for a neural network to mimic and work like the human brain. Neural networks are basically used in computational models.
A deep neural network (DNN) is an artificial neural network (ANN) with multiple layers between the input and output layers. They can model complex non-linear relationships. Convolutional Neural Networks (CNN) are an alternative type of DNN that allow modelling both time and space correlations in multivariate signals.
CNN is a specific kind of ANN that has one or more layers of convolutional units. The class of ANN covers several architectures including Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN) eg LSTM and GRU, Autoencoders, and Deep Belief Networks.
Multilayer Perceptron (MLP) is great for MNIST as it is a simpler and more straight forward dataset, but it lags when it comes to real-world application in computer vision, specifically image classification as compared to CNN which is great.
Hope you found this interesting! You can check out our blog about Convolutional Neural Network. To learn more about such concepts, take up an artificial intelligence online course and upskill today.