
- What is Machine Learning?
- History of Machine Learning
- Why Should We Learn Machine Learning?
- How to get started with Machine Learning?
- There are Seven Steps of Machine Learning
- How does Machine Learning work?
- Which Language is Best for Machine Learning?
- Difference Between Machine Learning, Artificial Intelligence and Deep Learning
- Types of Machine Learning
- Advantages and Disadvantages
- Machine Learning Algorithms
- Applications of Machine Learning
- Real-world machine learning use cases
- Future of Machine Learning
- FAQs
- Our Machine Learning Courses
Machine learning is a field of artificial intelligence that allows systems to learn and improve from experience without being explicitly programmed. It has become an increasingly popular topic in recent years due to the many practical applications it has in a variety of industries. In this blog, we will explore the basics of machine learning, delve into more advanced topics, and discuss how it is being used to solve real-world problems. Whether you are a beginner looking to learn about machine learning or an experienced data scientist seeking to stay up-to-date on the latest developments, we hope you will find something of interest here.
What is Machine Learning?
Machine learning is an application of artificial intelligence that uses statistical techniques to enable computers to learn and make decisions without being explicitly programmed. It is predicated on the notion that computers can learn from data, spot patterns, and make judgments with little assistance from humans.
It is a subset of Artificial Intelligence. It is the study of making machines more human-like in their behavior and decisions by giving them the ability to learn and develop their own programs. This is done with minimum human intervention, i.e., no explicit programming. The learning process is automated and improved based on the experiences of the machines throughout the process.
Good quality data is fed to the machines, and different algorithms are used to build ML models to train the machines on this data. The choice of algorithm depends on the type of data at hand and the type of activity that needs to be automated.
Now you may wonder, how is it different from traditional programming? Well, in traditional programming, we would feed the input data and a well-written and tested program into a machine to generate output. When it comes to machine learning, input data, along with the output, is fed into the machine during the learning phase, and it works out a program for itself. To understand this better, refer to the illustration below:
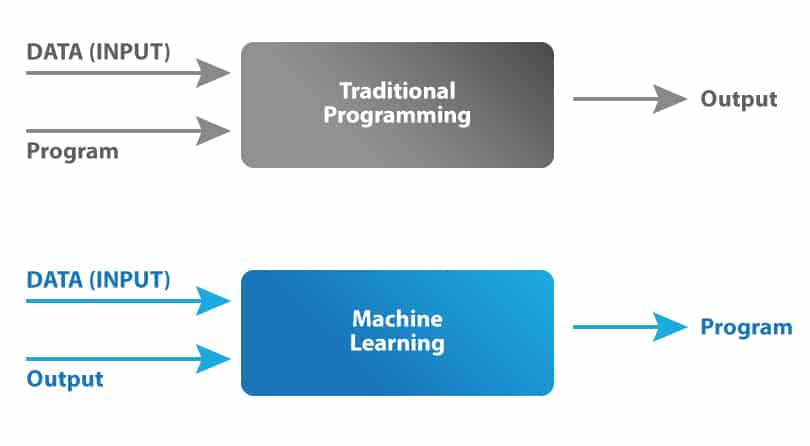
History of Machine Learning
This section discusses the development of machine learning over the years. Today we are witnessing some astounding applications like self-driving cars, natural language processing and facial recognition systems making use of ML techniques for their processing. All this began in the year 1943, when Warren McCulloch a neurophysiologist along with a mathematician named Walter Pitts authored a paper that threw a light on neurons and its working. They created a model with electrical circuits and thus neural network was born.
The famous “Turing Test” was created in 1950 by Alan Turing, which would ascertain whether computers had real intelligence. It has to make a human believe that it is not a computer but a human instead, to get through the test. Arthur Samuel developed the first computer program that could learn as it played the game of checkers in the year 1952. The first neural network, called the perceptron was designed by Frank Rosenblatt in the year 1957.
The big shift happened in the 1990s when machine learning moved from being knowledge-driven to a data-driven technique due to the availability of huge volumes of data. IBM’s Deep Blue, developed in 1997 was the first machine to defeat the world champion in the game of chess. Businesses have recognized that the potential for complex calculations could be increased through machine learning. Some of the latest projects include: Google Brain, which was developed in 2012, was a deep neural network that focused on pattern recognition in images and videos. It was later employed to detect objects in YouTube videos. In 2014, Facebook created Deep Face, which can recognize people just like how humans do. In 2014, Deep Mind created a computer program called Alpha Go a board game that defeated a professional Go player. Due to its complexity, the game is said to be a very challenging yet classical game for artificial intelligence. Scientists Stephen Hawking and Stuart Russel have felt that if AI gains the power to redesign itself at an intensifying rate, then an unbeatable “intelligence explosion” may lead to human extinction. Musk characterizes AI as humanity’s “biggest existential threat.” Open AI is an organization created by Elon Musk in 2015 to develop safe and friendly AI that could benefit humanity. Recently, some of the breakthrough areas in AI are Computer Vision, Natural Language Processing and Reinforcement Learning.
Why Should We Learn Machine Learning?
Machine learning is a powerful tool that can be used to solve a wide range of problems. It allows computers to learn from data, without being explicitly programmed. This makes it possible to build systems that can automatically improve their performance over time by learning from their experiences.
There are many reasons why learning machine learning is important:
- Machine learning is widely used in many industries, including healthcare, finance, and e-commerce. By learning machine learning, you can open up a wide range of career opportunities in these fields.
- Machine learning can be used to build intelligent systems that can make decisions and predictions based on data. This can help organizations make better decisions, improve their operations, and create new products and services.
- Machine learning is an important tool for data analysis and visualization. It allows you to extract insights and patterns from large datasets, which can be used to understand complex systems and make informed decisions.
- Machine learning is a rapidly growing field with many exciting developments and research opportunities. By learning machine learning, you can stay up-to-date with the latest research and developments in the field.
Check out Machine Learning Course for Beginners to learn more.
How to get started with Machine Learning?
To get started, let’s take a look at some of the important terminologies.
Terminology:
- Model: Also known as “hypothesis”, a machine learning model is the mathematical representation of a real-world process. A machine learning algorithm along with the training data builds a machine learning model.
- Feature: A feature is a measurable property or parameter of the data-set.
- Feature Vector: It is a set of multiple numeric features. We use it as an input to the machine learning model for training and prediction purposes.
- Training: An algorithm takes a set of data known as “training data” as input. The learning algorithm finds patterns in the input data and trains the model for expected results (target). The output of the training process is the machine learning model.
- Prediction: Once the machine learning model is ready, it can be fed with input data to provide a predicted output.
- Target (Label): The value that the machine learning model has to predict is called the target or label.
- Overfitting: When a massive amount of data trains a machine learning model, it tends to learn from the noise and inaccurate data entries. Here the model fails to characterize the data correctly.
- Underfitting: It is the scenario when the model fails to decipher the underlying trend in the input data. It destroys the accuracy of the machine learning model. In simple terms, the model or the algorithm does not fit the data well enough.
Here’s a video that describes step by step guide to approaching a Machine Learning problem with a beer and wine example:
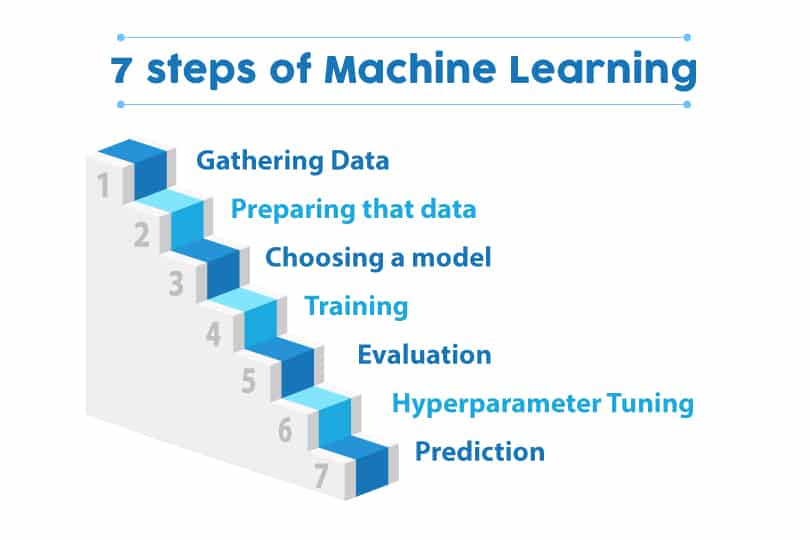
There are Seven Steps of Machine Learning
- Gathering Data
- Preparing that data
- Choosing a model
- Training
- Evaluation
- Hyperparameter Tuning
- Prediction
It is mandatory to learn a programming language, preferably Python, along with the required analytical and mathematical knowledge. Here are the five mathematical areas that you need to brush up before jumping into solving Machine Learning problems:
- Linear algebra for data analysis: Scalars, Vectors, Matrices, and Tensors
- Mathematical Analysis: Derivatives and Gradients
- Probability theory and statistics for Machine Learning
- Multivariate Calculus
- Algorithms and Complex Optimizations
How does Machine Learning work?
The three major building blocks of a system are the model, the parameters, and the learner.
- Model is the system which makes predictions
- The parameters are the factors which are considered by the model to make predictions
- The learner makes the adjustments in the parameters and the model to align the predictions with the actual results
Let us build on the beer and wine example from above to understand how machine learning works. A machine learning model here has to predict if a drink is a beer or wine. The parameters selected are the color of the drink and the alcohol percentage. The first step is:
1. Learning from the training set
This involves taking a sample data set of several drinks for which the colour and alcohol percentage is specified. Now, we have to define the description of each classification, that is wine and beer, in terms of the value of parameters for each type. The model can use the description to decide if a new drink is a wine or beer.
You can represent the values of the parameters, ‘colour’ and ‘alcohol percentages’ as ‘x’ and ‘y’ respectively. Then (x,y) defines the parameters of each drink in the training data. This set of data is called a training set. These values, when plotted on a graph, present a hypothesis in the form of a line, a rectangle, or a polynomial that fits best to the desired results.
2. Measure error
Once the model is trained on a defined training set, it needs to be checked for discrepancies and errors. We use a fresh set of data to accomplish this task. The outcome of this test would be one of these four:
- True Positive: When the model predicts the condition when it is present
- True Negative: When the model does not predict a condition when it is absent
- False Positive: When the model predicts a condition when it is absent
- False Negative: When the model does not predict a condition when it is present
The sum of FP and FN is the total error in the model.
3. Manage Noise
For the sake of simplicity, we have considered only two parameters to approach a machine learning problem here that is the colour and alcohol percentage. But in reality, you will have to consider hundreds of parameters and a broad set of learning data to solve a machine learning problem.
- The hypothesis then created will have a lot more errors because of the noise. Noise is the unwanted anomalies that disguise the underlying relationship in the data set and weakens the learning process. Various reasons for this noise to occur are:
- Large training data set
- Errors in input data
- Data labelling errors
- Unobservable attributes that might affect the classification but are not considered in the training set due to lack of data
You can accept a certain degree of training error due to noise to keep the hypothesis as simple as possible.
4. Testing and Generalization
While it is possible for an algorithm or hypothesis to fit well to a training set, it might fail when applied to another set of data outside of the training set. Therefore, It is essential to figure out if the algorithm is fit for new data. Testing it with a set of new data is the way to judge this. Also, generalisation refers to how well the model predicts outcomes for a new set of data.
When we fit a hypothesis algorithm for maximum possible simplicity, it might have less error for the training data, but might have more significant error while processing new data. We call this is underfitting. On the other hand, if the hypothesis is too complicated to accommodate the best fit to the training result, it might not generalise well. This is the case of over-fitting. In either case, the results are fed back to train the model further.
Which Language is Best for Machine Learning?
Python is hands down the best programming language for Machine Learning applications due to the various benefits mentioned in the section below. Other programming languages that could be used are: R, C++, JavaScript, Java, C#, Julia, Shell, TypeScript, and Scala.
Python is famous for its readability and relatively lower complexity as compared to other programming languages. ML applications involve complex concepts like calculus and linear algebra which take a lot of effort and time to implement. Python helps in reducing this burden with quick implementation for the ML engineer to validate an idea. You can check out the Python Tutorial to get a basic understanding of the language. Another benefit of using Python is the pre-built libraries. There are different packages for a different type of applications, as mentioned below:
- Numpy, OpenCV, and Scikit are used when working with images
- NLTK along with Numpy and Scikit again when working with text
- Librosa for audio applications
- Matplotlib, Seaborn, and Scikit for data representation
- TensorFlow and Pytorch for Deep Learning applications
- Scipy for Scientific Computing
- Django for integrating web applications
- Pandas for high-level data structures and analysis
Here is a summary:

Difference Between Machine Learning, Artificial Intelligence and Deep Learning
| Concept | Definition |
| Artificial intelligence | The field of computer science aims to create intelligent machines that can think and function like humans. |
| Machine learning | A subfield of artificial intelligence that focuses on developing algorithms and models that can learn from data rather than being explicitly programmed. |
| Deep learning | A subfield of machine learning that uses multi-layered artificial neural networks to learn complex patterns in data. |
Here is a brief summary of the main differences between these concepts:
- Artificial intelligence is a broad field that encompasses a variety of techniques and approaches for creating intelligent systems.
- The practice of teaching algorithms to learn from data rather than being explicitly programmed is known as machine learning, which is a subset of artificial intelligence.
- Deep learning is a branch of machine learning that use multiple layers of artificial neural networks to discover intricate data patterns.
Introduction to Artificial Intelligence
Machine learning Course for Beginners
Types of Machine Learning
There are three main types:
Supervised learning
Supervised learning is a class of problems that uses a model to learn the mapping between the input and target variables. Applications consisting of the training data describing the various input variables and the target variable are known as supervised learning tasks.
Let the set of input variable be (x) and the target variable be (y). A supervised learning algorithm tries to learn a hypothetical function which is a mapping given by the expression y=f(x), which is a function of x.
The learning process here is monitored or supervised. Since we already know the output the algorithm is corrected each time it makes a prediction, to optimize the results. Models are fit on training data which consists of both the input and the output variable and then it is used to make predictions on test data. Only the inputs are provided during the test phase and the outputs produced by the model are compared with the kept back target variables and is used to estimate the performance of the model.
There are basically two types of supervised problems: Classification – which involves prediction of a class label and Regression – that involves the prediction of a numerical value.
The MINST handwritten digits data set can be seen as an example of classification task. The inputs are the images of handwritten digits, and the output is a class label which identifies the digits in the range 0 to 9 into different classes.
The Boston house price data set could be seen as an example of Regression problem where the inputs are the features of the house, and the output is the price of a house in dollars, which is a numerical value.
Unsupervised learning
In an unsupervised learning problem the model tries to learn by itself and recognize patterns and extract the relationships among the data. As in case of a supervised learning there is no supervisor or a teacher to drive the model. Unsupervised learning operates only on the input variables. There are no target variables to guide the learning process. The goal here is to interpret the underlying patterns in the data in order to obtain more proficiency over the underlying data.
There are two main categories in unsupervised learning; they are clustering – where the task is to find out the different groups in the data. And the next is Density Estimation – which tries to consolidate the distribution of data. These operations are performed to understand the patterns in the data. Visualization and Projection may also be considered as unsupervised as they try to provide more insight into the data. Visualization involves creating plots and graphs on the data and Projection is involved with the dimensionality reduction of the data.
Reinforcement learning
Reinforcement learning is type a of problem where there is an agent and the agent is operating in an environment based on the feedback or reward given to the agent by the environment in which it is operating. The rewards could be either positive or negative. The agent then proceeds in the environment based on the rewards gained.
The reinforcement agent determines the steps to perform a particular task. There is no fixed training dataset here and the machine learns on its own.
Playing a game is a classic example of a reinforcement problem, where the agent’s goal is to acquire a high score. It makes the successive moves in the game based on the feedback given by the environment which may be in terms of rewards or a penalization. Reinforcement learning has shown tremendous results in Google’s AplhaGo of Google which defeated the world’s number one Go player.
Advantages and Disadvantages
Everything comes with a few advantages and disadvantages. In this section, let’s talk about a few of the basic advantages and disadvantages of ML.
Advantages:
- It can be used for pattern detection.
- It can be used to make predictions about future data.
- It can be used to generate new features from data automatically.
- It can be used to cluster data automatically.
- It can be used to detect outliers in data automatically.
Disadvantages:
Some disadvantages include the potential for biased data, overfitting data, and lack of explainability.
Machine Learning Algorithms
There are a variety of machine learning algorithms available and it is very difficult and time consuming to select the most appropriate one for the problem at hand. These algorithms can be grouped in to two categories. Firstly, they can be grouped based on their learning pattern and secondly by their similarity in their function.
Based on their learning style they can be divided into three types:
- Supervised Learning Algorithms: The training data is provided along with the label which guides the training process. The model is trained until the desired level of accuracy is attained with the training data. Examples of such problems are classification and regression. Examples of algorithms used include Logistic Regression, Nearest Neighbor, Naive Bayes, Decision Trees, Linear Regression, Support Vector Machines (SVM), Neural Networks.
- Unsupervised Learning Algorithms: Input data is not labeled and does not come with a label. The model is prepared by identifying the patterns present in the input data. Examples of such problems include clustering, dimensionality reduction and association rule learning. List of algorithms used for these type of problems include Apriori algorithm and K-Means and Association Rules
- Semi-Supervised Learning Algorithms: The cost to label the data is quite expensive as it requires the knowledge of skilled human experts. The input data is combination of both labeled and unlabelled data. The model makes the predictions by learning the underlying patterns on their own. It is a mix of both classification and clustering problems.
Based on the similarity of function, the algorithms can be grouped into the following:
- Regression Algorithms: Regression is a process that is concerned with identifying the relationship between the target output variables and the input features to make predictions about the new data. Top six Regression algorithms are: Simple Linear Regression, Lasso Regression, Logistic regression, Multivariate Regression algorithm, Multiple Regression Algorithm.
- Instance-based Algorithms: These belong to the family of learning that measures new instances of the problem with those in the training data to find out a best match and makes a prediction accordingly. The top instance-based algorithms are: k-Nearest Neighbor, Learning Vector Quantization, Self-Organizing Map, Locally Weighted Learning, and Support Vector Machines.
- Regularization: Regularization refers to the technique of regularizing the learning process from a particular set of features. It normalizes and moderates. The weights attached to the features are normalized, which prevents in certain features from dominating the prediction process. This technique helps to prevent the problem of overfitting in machine learning. The various regularization algorithms are Ridge Regression, Least Absolute Shrinkage and Selection Operator (LASSO) and Least-Angle Regression (LARS).
- Decision Tree Algorithms: These methods construct a tree-based model constructed on the decisions made by examining the values of the attributes. Decision trees are used for both classification and regression problems. Some of the well-known decision tree algorithms are: Classification and Regression Tree, C4.5 and C5.0, Conditional Decision Trees, Chi-squared Automatic Interaction Detection and Decision Stump.
- Bayesian Algorithms: These algorithms apply the Bayes theorem for classification and regression problems. They include Naive Bayes, Gaussian Naive Bayes, Multinomial Naive Bayes, Bayesian Belief Network, Bayesian Network and Averaged One-Dependence Estimators.
- Clustering Algorithms: Clustering algorithms involve the grouping of data points into clusters. All the data points that are in the same group share similar properties and, data points in different groups have highly dissimilar properties. Clustering is an unsupervised learning approach and is mostly used for statistical data analysis in many fields. Algorithms like k-Means, k-Medians, Expectation Maximisation, Hierarchical Clustering, and Density-Based Spatial Clustering of Applications with Noise fall under this category.
- Association Rule Learning Algorithms: Association rule learning is a rule-based learning method for identifying the relationships between variables in a very large dataset. Association Rule learning is employed predominantly in market basket analysis. The most popular algorithms are: Apriori algorithm and Eclat algorithm.
- Artificial Neural Network Algorithms: Artificial neural network algorithms relies find its base from the biological neurons in the human brain. They belong to the class of complex pattern matching and prediction processes in classification and regression problems. Some of the popular artificial neural network algorithms are: Perceptron, Multilayer Perceptrons, Stochastic Gradient Descent, Back-Propagation, , Hopfield Network, and Radial Basis Function Network.
- Deep Learning Algorithms: These are modernized versions of artificial neural network, that can handle very large and complex databases of labeled data. Deep learning algorithms are tailored to handle text, image, audio and video data. Deep learning uses self-taught learning constructs with many hidden layers, to handle big data and provides more powerful computational resources. The most popular deep learning algorithms are: Some of the popular deep learning ms include Convolutional Neural Network, Recurrent Neural Networks, Deep Boltzmann Machine, Auto-Encoders Deep Belief Networks and Long Short-Term Memory Networks.
- Dimensionality Reduction Algorithms: Dimensionality Reduction algorithms exploit the intrinsic structure of data in an unsupervised manner to express data using reduced information set. They convert a high dimensional data into a lower dimension which could be used in supervised learning methods like classification and regression. Some of the well known dimensionality reduction algorithms include Principal Component Analysis, Principal Component Regressio, Linear Discriminant Analysis, Quadratic Discriminant Analysis, Mixture Discriminant Analysis, Flexible Discriminant Analysis and Sammon Mapping.
- Ensemble Algorithms: Ensemble methods are models made up of various weaker models that are trained separately and the individual predictions of the models are combined using some method to get the final overall prediction. The quality of the output depends on the method chosen to combine the individual results. Some of the popular methods are: Random Forest, Boosting, Bootstrapped Aggregation, AdaBoost, Stacked Generalization, Gradient Boosting Machines, Gradient Boosted Regression Trees and Weighted Average.
Applications of Machine Learning
These algorithms help in building intelligent systems that can learn from their past experiences and historical data to give accurate results. Many industries are thus applying ML solutions to their business problems, or to create new and better products and services. Healthcare, defense, financial services, marketing, and security services, among others, make use of ML.
1. Facial recognition/Image recognition
The most common application is Facial Recognition, and the simplest example of this application is the iPhone. There are a lot of use-cases of facial recognition, mostly for security purposes like identifying criminals, searching for missing individuals, aid forensic investigations, etc. Intelligent marketing, diagnose diseases, track attendance in schools, are some other uses.
2. Automatic Speech Recognition
Abbreviated as ASR, automatic speech recognition is used to convert speech into digital text. Its applications lie in authenticating users based on their voice and performing tasks based on the human voice inputs. Speech patterns and vocabulary are fed into the system to train the model. Presently ASR systems find a wide variety of applications in the following domains:
- Medical Assistance
- Industrial Robotics
- Forensic and Law enforcement
- Defense & Aviation
- Telecommunications Industry
- Home Automation and Security Access Control
- I.T. and Consumer Electronics
3. Financial Services
Machine learning has many use cases in Financial Services. Machine Learning algorithms prove to be excellent at detecting frauds by monitoring activities of each user and assess that if an attempted activity is typical of that user or not. Financial monitoring to detect money laundering activities is also a critical security use case.
It also helps in making better trading decisions with the help of algorithms that can analyze thousands of data sources simultaneously. Credit scoring and underwriting are some of the other applications. The most common application in our day to day activities is the virtual personal assistants like Siri and Alexa.
4. Marketing and Sales
It is improving lead scoring algorithms by including various parameters such as website visits, emails opened, downloads, and clicks to score each lead. It also helps businesses to improve their dynamic pricing models by using regression techniques to make predictions.
Sentiment Analysis is another essential application to gauge consumer response to a specific product or a marketing initiative. Machine Learning for Computer Vision helps brands identify their products in images and videos online. These brands also use computer vision to measure the mentions that miss out on any relevant text. Chatbots are also becoming more responsive and intelligent.
5. Healthcare
A vital application is in the diagnosis of diseases and ailments, which are otherwise difficult to diagnose. Radiotherapy is also becoming better.
Early-stage drug discovery is another crucial application which involves technologies such as precision medicine and next-generation sequencing. Clinical trials cost a lot of time and money to complete and deliver results. Applying ML based predictive analytics could improve on these factors and give better results.
These technologies are also critical to make outbreak predictions. Scientists around the world are using ML technologies to predict epidemic outbreaks.
6. Recommendation Systems
Many businesses today use recommendation systems to effectively communicate with the users on their site. It can recommend relevant products, movies, web-series, songs, and much more. Most prominent use-cases of recommendation systems are e-commerce sites like Amazon, Flipkart, and many others, along with Spotify, Netflix, and other web-streaming channels.
Real-world machine learning use cases
- Fraud detection: Machine learning algorithms can be trained to detect patterns of fraudulent behavior, such as suspicious transactions or fake accounts.
- Image and speech recognition: Machine learning algorithms can be used to recognize and classify objects, people, and spoken words in images and audio recordings.
- Predictive maintenance: Equipment maintenance can be planned ahead of time to save downtime using machine learning to predict when it is likely to fail.
- Personalization: Machine learning can be used to personalize recommendations and advertisements, such as those seen on online shopping websites or streaming services.
- Healthcare: Machine learning can be used to predict patient outcomes, identify potential outbreaks of infectious diseases, and assist with diagnosis and treatment planning.
- Natural language processing: Machine learning can be used to understand and process human language, enabling applications such as language translation and chatbots.
Future of Machine Learning
Given that machine learning is a constantly developing field that is influenced by numerous factors, it is challenging to forecast its precise future. Machine learning, however, is most likely to continue to be a major force in many fields of science, technology, and society as well as a major contributor to technological advancement. The creation of intelligent assistants, personalized healthcare, and self-driving automobiles are some potential future uses for machine learning. Important global issues like poverty and climate change may be addressed via machine learning.
It is also likely that machine learning will continue to advance and improve, with researchers developing new algorithms and techniques to make machine learning more powerful and effective. One area of active research in this field is the development of artificial general intelligence (AGI), which refers to the development of systems that have the ability to learn and perform a wide range of tasks at a human-like level of intelligence.
FAQs
1. What exactly is machine learning?
Arthur Samuel coined the term Machine Learning in 1959. He defined it as “The field of study that gives computers the capability to learn without being explicitly programmed”. It is a subset of Artificial Intelligence and it allows machines to learn from their experiences without any coding.
2. What is machine learning used for?
Machine Learning is used in our daily lives much more than we know it. These are areas where it is used:
- Facial Recognition
- Self-driving cars
- Virtual assistants
- Traffic Predictions
- Speech Recognition
- Online Fraud Detection
- Email Spam Filtering
- Product Recommendations
3. What is difference between machine learning and artificial intelligence?
A technology that enables a machine to stimulate human behavior to help in solving complex problems is known as Artificial Intelligence. Machine Learning is a subset of AI and allows machines to learn from past data and provide an accurate output. AI deals with unstructured as well as structured data. Whereas, Machine Learning deals with structured and semi-structured data.
4. How Machine Learning works?
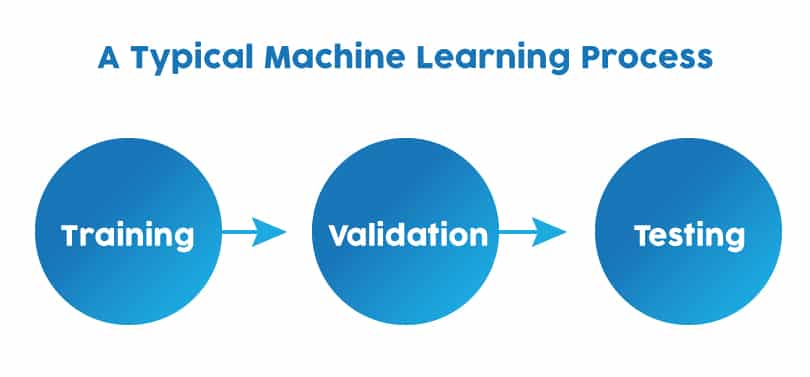
The typical machine learning process involves three steps: Training, Validation, and Testing. The first step is to learn from the training set provided, the second step is to measure error, the third step involves managing noise and testing all the parameters. These are the basic steps followed and a very broad description on how it works.
5. What are the types of Machine Learning?
The broad types of machine learning are:
- Supervised Machine Learning
- Unsupervised Machine Learning
- Semi-supervised Learning
- Reinforcement Learning
6. What is the best language for machine learning?
The best programming language to learn machine learning can be any of the following: Python, R, Java and JavaScript, Julia. However, in today’s day and age, Python is the most commonly used programming language due to it’s ease and simplicity. The number of programmers using Python as their primary coding language is increasing.
7. Is Alexa a machine learning?
Alexa is a virtual assistant that is created by Amazon and is also known as Amazon Alexa. This virtual assistant was created using machine learning and artificial intelligence technologies.
8. Is Siri a machine learning?
Similar to Alexa, Siri is also a virtual or a personal assistant. Siri was created by Apple and makes use of voice technology to perform certain actions. Siri also makes use of machine learning and deep learning to function.
9. Why is machine learning popular?
The amount of data available to us is constantly increasing. Machines make use of this data to learn and improve the results and outcomes provided to us. These outcomes can be extremely helpful in providing valuable insights and taking informed business decisions as well. It is constantly growing, and with that, the applications are growing as well. We make use of machine learning in our day-to-day life more than we know it. In the future, it is only said to grow further and help us. Thus, it is popular.
Our Machine Learning Courses
Explore our Machine Learning and AI courses, designed for comprehensive learning and skill development.
| Program Name | Duration |
|---|---|
| MIT No code AI and Machine Learning Course | 12 Weeks |
| MIT Data Science and Machine Learning Course | 12 Weeks |
| Data Science and Machine Learning Course | 12 Weeks |




