Earn a certificate & get recognized
Bias Variance Tradeoff


About this course
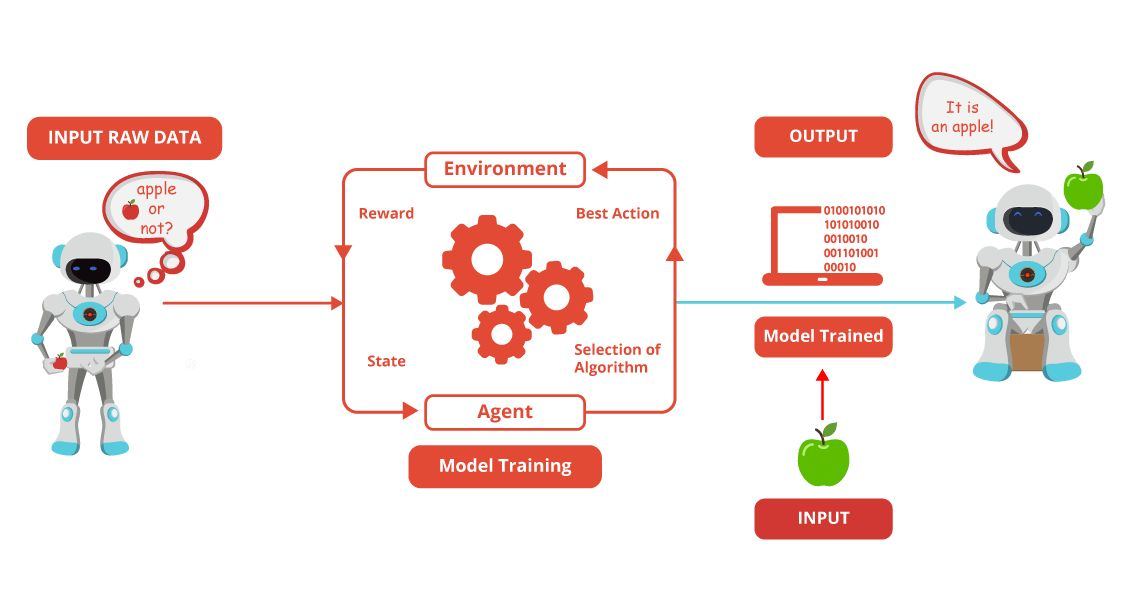
In simple words, bias means how far you have come in predicting the desired value from your actual value. It is an approach that can ultimately make or break the model in favor or against your idea. It can also be thought of as a methodological error in your machine learning model due to inappropriate assumptions made by you during the making of that model. Variance is the reverse of bias, It is called the variance when your model performs exceptionally well on the training dataset yet fails to live up to the same standards when running it on an entirely new dataset. The trade-off is simply the tension that exists between the error that is introduced by bias and variance.
Course outline
Get access to the complete curriculum once you enroll in the course
 4.59
4.59




 United Arab Emirates
United Arab Emirates

 United Kingdom
United Kingdom

 India
India

 United States
United States
What our learners enjoyed the most
Skill & tools
62% of learners found all the desired skills & tools
Frequently Asked Questions
Will I receive a certificate upon completing this free course?
Is this course free?
Will I get a certificate after completing this Bias Variance Tradeoff free course?
Yes, you will get a certificate of completion for Bias Variance Tradeoff after completing all the modules and cracking the assessment. The assessment tests your knowledge of the subject and badges your skills.
How much does this Bias Variance Tradeoff course cost?
It is an entirely free course from Great Learning Academy. Anyone interested in learning the basics of Bias Variance Tradeoff can get started with this course.
Is there any limit on how many times I can take this free course?
Once you enroll in the Bias Variance Tradeoff course, you have lifetime access to it. So, you can log in anytime and learn it for free online.
Can I sign up for multiple courses from Great Learning Academy at the same time?
Yes, you can enroll in as many courses as you want from Great Learning Academy. There is no limit to the number of courses you can enroll in at once, but since the courses offered by Great Learning Academy are free, we suggest you learn one by one to get the best out of the subject.
Why choose Great Learning Academy for this free Bias Variance Tradeoff course?
Great Learning Academy provides this Bias Variance Tradeoff course for free online. The course is self-paced and helps you understand various topics that fall under the subject with solved problems and demonstrated examples. The course is carefully designed, keeping in mind to cater to both beginners and professionals, and is delivered by subject experts. Great Learning is a global ed-tech platform dedicated to developing competent professionals. Great Learning Academy is an initiative by Great Learning that offers in-demand free online courses to help people advance in their jobs. More than 5 million learners from 140 countries have benefited from Great Learning Academy's free online courses with certificates. It is a one-stop place for all of a learner's goals.
What are the steps to enroll in this Bias Variance Tradeoff course?
Enrolling in any of the Great Learning Academy’s courses is just one step process. Sign-up for the course, you are interested in learning through your E-mail ID and start learning them for free online.
Will I have lifetime access to this free Bias Variance Tradeoff course?
Yes, once you enroll in the course, you will have lifetime access, where you can log in and learn whenever you want to.




Recommended Free Machine Learning courses




Similar courses you might like



Related Machine Learning Courses
-

Johns Hopkins University
Certificate Program in AI Business Strategy10 weeks · Online
Know More
-
Walsh College
MS in Artificial Intelligence & Machine Learning2 Years · Online
Know More
-
MIT Professional Education
No Code and Agentic AI14 Weeks · Online · Weekend
Learn from MIT FacultyKnow More








")