Whether it’s a career that you are considering, or you want to move up the ladder from where you already are – in the AI domain, the future definitely is bright. There are numerous professionals, alongside you, who have recognized the opportunities to move into the field. Considering the competition in this sphere, to position yourself as a successful job candidate who stands out from a crowd. Hence, it is a good idea to not only pursue certifications in Artificial Intelligence, but also prepare ahead of time for crucial job AI interview questions. Here are some commonly asked ones that will assist you in preparing for the same.

1.What is AI?
Artificial Intelligence is a field of computer science wherein the cognitive functions of the human brain are studied and replicated on a machine or a system. Artificial Intelligence today is widely used in various sectors of the economy including science and technology, healthcare, telecommunications, energy and so on. AI has three different levels:
- Narrow AI: AI is narrow when the machine performs a specific task better than a human. The current research of AI is taking place at this level.
- General AI: AI reaches the general state when it can perform any intellectual task equivalent to the accuracy of that of a human.
- Active AI: AI is active when it can completely beat humans in all performed tasks.

2. What is the difference between Artificial Intelligence, Machine Learning, and Deep Learning?
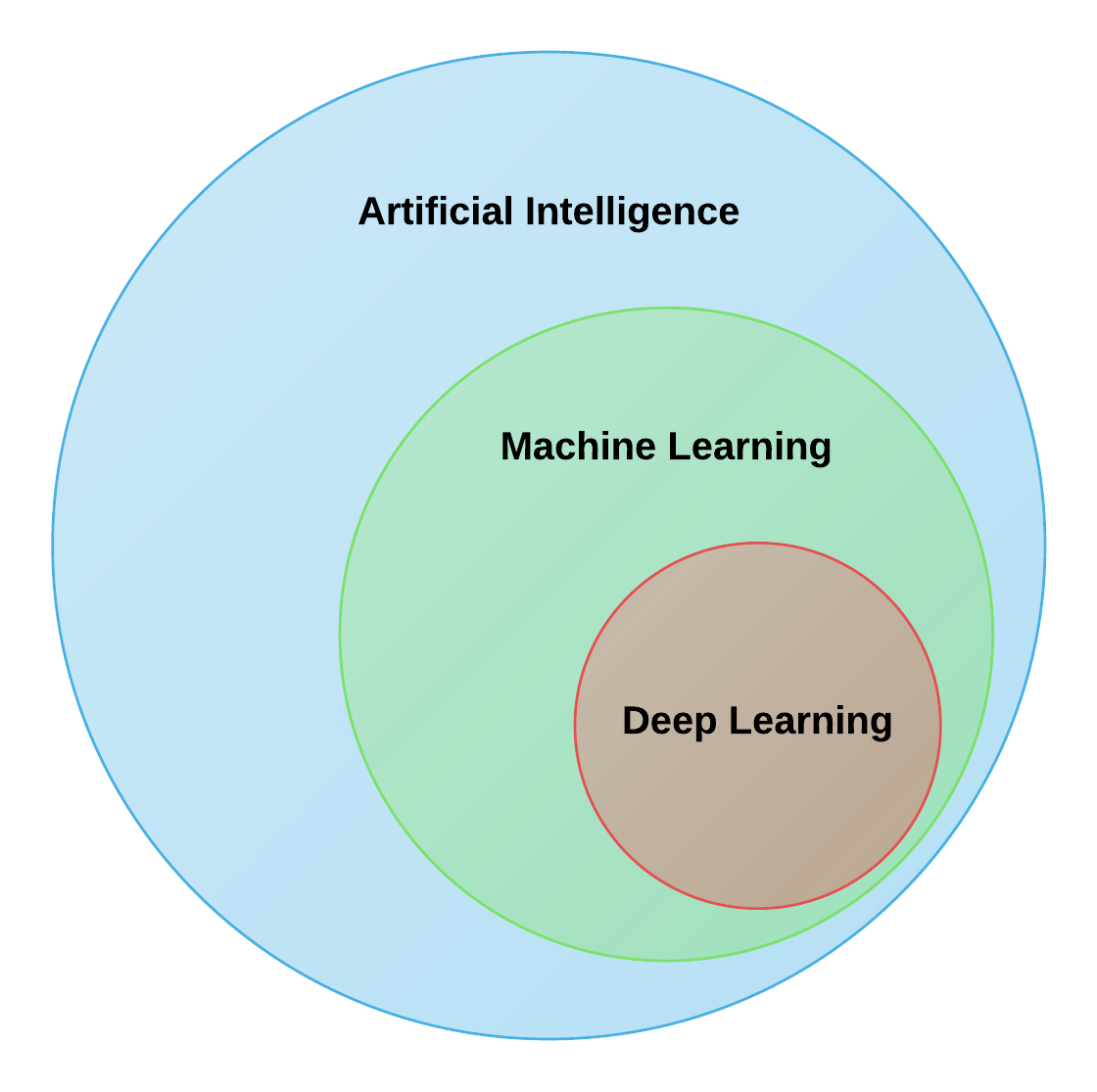
DL is a subset of ML, which is the subset of AI. Hence, AI is the all-encompassing concept that initially erupted in computer science. It was then followed by ML that thrived later, and lastly DL, that is now promising to escalate the advances of AI to another level.
Read more on Differences between Artificial Intelligence, Machine Learning, and Deep Learning.
3. What are the Different Types of AI?
- Reactive Machines AI: Based on present actions, it is not capable of using previous experiences to form current decisions whilst simultaneously updating their memory.
- Limited Memory AI: This type of AI is used in self-driving cars – they detect the movement of vehicles around them constantly and add it to their memory.
- Theory of Mind AI: Advanced levels of AI have the ability to understand emotions and people.
- Self Aware AI: This type of AI possesses human-like consciousness and reactions. Such machines have the ability to form self-driven actions.
- Artificial Narrow Intelligence (ANI): This type of AI is a general-purpose AI, essentially used in building virtual assistants like Siri or Alexa.
- Artificial General Intelligence (AGI): AGI is also known as strong AI. Example: Pillo robot – that answers questions related to health.
- Artificial Superhuman Intelligence (ASI): This is the AI that possesses the ability to do everything that a human can do and more. An example is the Alpha 2 which is the first humanoid ASI robot.
4. Name some popular programming languages in AI.
Some commonly used programming languages in AI include:
- Python
- R
- Lisp
- Prolog
- Java
5. List some AI Applications and Common uses.
AI-powered tools are applied in various spheres of the economy, including:
- Natural Language Processing
- Chatbots
- Sentiment analysis
- Sales prediction
- Self-driving cars
- Facial expression recognition
- Image tagging
6. Mention Some Popular Domains of AI.
The most popular domains in AI are:
- Machine Learning
- Neural Networks
- Robotics
- Expert Systems
- Fuzzy Logic Systems
- Natural Language Processing
7. What is the difference between Weak AI and Strong AI?
| Weak AI | Strong AI |
| It is a narrow application with a limited scope. | It is a wider application with a more vast scope. |
| This application is good at specific tasks. | This application has an incredible human-level intelligence. |
| It uses supervised and unsupervised learning to process data. | It uses clustering and association to process data. |
| Example: Siri, Alexa. | Example: Advanced Robotics |
8. What is an expert system? What are its characteristics?
An expert system is an Artificial Intelligence program that has an expert-level knowledge about a specific area of data and its utilisation to react appropriately. These systems tend to have the capability to substitute a human expert. Their characteristics include:
- High performance
- Consistency
- Reliability
- Diligence
- Unbiased nature
Read more on Expert Systems in AI.
9. What are the Advantages of an Expert System?
The advantages of an expert system are:
- Easy availability
- Low production costs
- Greater speed and reduced workload
- They avoid motions, tensions, and fatigue
- They reduce the rate of errors.
10. What is an Artificial Neural Network? Name some of the commonly used ones.
Artificial Neural Networks, as the name suggests, are brain-inspired systems that are intended to replicate the way humans learn. Neural networks consist of input and output layers, as well as a hidden layer consisting of units that transform the inputs into optimal outputs. They are excellent tools to find patterns that are far too complex or numerous for a human programmer to extract and teach the machine to recognize.
Some of the commonly used ones include:
- Feed Forward Neural Nets
- Multiple Layered Perceptron Neural Nets
- Convolution Neural Nets
- Recurrent Neural Nets
- Modular Neural Network
Read more on Types of Neural Networks.
11. What are the Hyper Parameters of ANN?
- Learning rate: The learning rate implies how fast the network learns its parameters.
- Momentum: This parameter helps in coming out of the local minima and smoothening the jumps while gradient descents.
- Number of epochs: This shows the number of times the entire training data is fed to the network. Here, the training is referred to as the number of epochs.
12. What is the Tower of Hanoi?
Tower of Hanoi essentially is a mathematical puzzle that displays how recursion is utilised as a device in building up an algorithm to solve a specific problem. The Tower of Hanoi can be solved using a decision tree and a breadth-first search (BFS) algorithm in AI. With 3 disks, a puzzle can essentially be solved in 7 moves. However, the minimal number of moves required to solve a Tower of Hanoi puzzle is 2n − 1, where n is the number of disks.
13. What is the Turing test?
The Turing test is a method that tests a machine’s ability to match human-level intelligence. It is only considered intelligent if it passes the Turing test. However, a machine can be considered as intelligent even without sufficiently knowing how to mimic a human, in specific scenarios.
14. What is an A* Algorithm search method?
A* is a computer algorithm in AI that is extensively used for the purpose of finding paths or traversing graphs – to obtain the most optimal route between nodes. It is widely used in solving pathfinding problems in video games. Considering its flexibility and versatility, it can be used in a wide range of contexts. A* is formulated with weighted graphs, which means it can find the best path involving the smallest cost in terms of distance and time. This makes A* an informed search algorithm for best-first search.
15. What is a breadth-first search algorithm?
A breadth-first search (BFS) algorithm is used to search tree or graph data structures. It starts from the root node, proceeds through neighbouring nodes, and finally moves towards the next level of nodes. Till the arrangement is found and created, it produces one tree at any given moment. As this pursuit is capable of being executed by utilising the FIFO (first-in, first-out) data structure, this strategy gives the shortest path to the solution.
16. What is a Depth-first Search Algorithm?
Depth-first search (DFS) is an algorithm that is based on LIFO (last-in, first-out). Since recursion is implemented with LIFO stack data structure, the nodes are in a different order than in BFS. The path is stored in each iteration from root to leaf nodes in a linear fashion with space requirement.
17. What is fuzzy logic? List its Applications.
Fuzzy logic is a subset of AI. It is a way of encoding human learning for artificial processing. It is represented as IF-THEN rules. Some of its important applications include:
- Facial pattern recognition
- Air conditioners, washing machines, and vacuum cleaners
- Anti Skid braking systems and transmission systems
- Control of subway systems and unmanned helicopters
- Weather forecasting systems
- Project risk assessment
- Medical diagnosis and treatment plans
- Stock trading
18. Mention some popular Machine Learning Algorithms?
Some of the popular Machine Learning algorithms are:
- Logistic regression
- Linear regression
- Decision trees
- Support vector machines
19. Differentiate between parametric and non-parametric models.
| Differentiation | Parametric Model | Non-parametric Model |
| Features | A finite number of parameters to predict new data | Unbounded number of parameters to predict new data. |
| Algorithm | Logistic regressionLinear discriminant analysisPerceptronNaive Bayes | K-nearest neighboursDecision trees (E.g.CART and C4.5)Support vector machines |
| Benefits | Easy to use Quick in functioningLess data | FlexibilityPowerPerformance |
| Limitations | Constrained Limited complexity Poor fit | More dataSlowerOverfit |
20. What is Ensemble Learning?
Ensemble learning is a computational technique in which classifiers or experts are strategically formed and combined. It is used to improve classification, prediction, and function approximation of any model.
Stay tuned for more information on interview questions and career assistance. If you wish to learn artificial intelligence, there are several courses available online that you can choose from. Upskill today!






