Design Intelligent Systems using LLMs, RAG, and Agentic AI
AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact
 Application closes on
21st May 2026
Application closes on
21st May 2026

 Speak with our expert
+1 617 539 7216
Speak with our expert
+1 617 539 7216



Learn more about the course
Get details on syllabus, projects, tools, and more

Top rated online AI, Data Science, and ML course
Application closes 21st May 2026
Distinctive features
-

AI-assisted coding
Leverage AI-assisted coding tools to write and debug Python faster, including access to OpenAI APIs and Codex for hands-on practice at no additional cost.
-
Next-gen modules
The upgraded curriculum is now infused with GPT-5, Codex for advanced code generation, LangChain, and LangGraph for building modern AI workflows and agentic systems.
Program Outcomes
Elevate your career in AI, Data Science and ML
Build proficiency in advanced topics like Agentic AI, LLM Orchestration, and RAG
-

Explain how AI evolved from prediction models to language models and autonomous agents
-
Write effective prompts, detect hallucinations, and use AI coding assistants to write and debug Python
-
Given a business question, choose the right ML approach, apply it, and assess if results are trustworthy
-
Connect LLMs to external data using RAG to ground outputs in real data and assess pipeline performance
-
Build AI systems that plan a sequence of steps, use external tools, and complete tasks autonomously
-
Design pipelines where multiple AI agents collaborate, divide work, recover from errors, and boost performance
Earn a certificate of completion from MIT IDSS
-
#1 in World Universities
QS World University Rankings, 2025
-
#1 in AI and Data Science
QS World University Rankings by Subject, 2025
-
#2 in National Universities
U.S. News & World Report Rankings, 2024-2025


Key program highlights
Why choose the AI and Data Science program
-
Learn from MIT faculty
Learn from the vast knowledge of MIT AI, Data Science and Machine Learning faculty through recorded sessions.
-
AI-assisted coding
Build AI and data science skills using AI-assisted coding tools like GitHub Copilot and ChatGPT to write, debug, and learn Python through hands-on practice.
-
Advanced AI-infused curriculum
Explore advanced modules on emerging topics including prompt engineering, retrieval-augmented generation (RAG), and next-generation model architectures.
-
Personalized mentorship sessions
Benefit from personalized weekend mentorship by experienced AI, Data Science and ML practitioners from leading global organizations.
-
Dedicated program support
Connect with dedicated program managers to assist with queries and guide you throughout the course.
-
Build Real-World Expertise
Work on 4 hands-on projects and explore 10+ real-world case studies to strengthen your practical skills and demonstrate your AI and Data Science capabilities.



Skills you will learn
Agentic AI
Prompt Engineering
Retrieval-Augmented Generation (RAG)
Multi-Agent Systems
LLM Orchestration
Prompt Optimization
AI-Assisted Coding
LLM Evaluation
AI Workflow Design
Generative AI Applications
Agentic AI
Prompt Engineering
Retrieval-Augmented Generation (RAG)
Multi-Agent Systems
LLM Orchestration
Prompt Optimization
AI-Assisted Coding
LLM Evaluation
AI Workflow Design
Generative AI Applications
view more
- Overview
- Curriculum
- Projects
- Tools
- Certificate
- Faculty
- Mentors
- Reviews
- Fees
- FAQ

This program is ideal for
Professionals ready to advance their skills in AI, Data Science, and Machine Learning
View Batch Profile
-
Career Starters in AI and Data Science
Individuals seeking a structured foundation in AI and Data Science to build job-ready technical capabilities and a strong professional credential.
-
Early-Career Professionals in Data and Technology
With a foundation in data science or software development, seeking to deepen technical expertise and design end-to-end AI workflows.
-
Tech Innovators and AI Practitioners
Responsible for building, integrating, or scaling AI solutions, seeking expertise in system design, multi-agent orchestration, and implementation.
-
Professionals Building Next-Generation AI Systems
Aiming to use advanced frameworks like GenAI, LangChain, and multi-agent systems to build reliable, scalable, real-world AI applications.
Program Curriculum
Designed by MIT faculty, the curriculum covers key concepts in Generative AI, Agentic AI, Data Science, and Machine Learning. Learn from experts through a structured, hands-on learning experience that builds the technical intuition and strategic judgment needed to translate data and AI into measurable business impact.
Pre-Work
Concepts Covered
Week 1: AI, GenAI, and Agentic AI Landscape
Concepts Covered
Week 2: LLMs and Prompt Engineering
Concepts Covered
Week 3: AI-Assisted Python Coding
Concepts Covered
Week 4: AI-Assisted Exploratory Analysis
Concepts Covered
Week 5: Project 1
Work on a real-world challenge by applying skills learned throughout the program, leveraging industry-relevant tools and technologies to maximize outcomes.
Week 6: Predictive Modeling With Regression
Concepts Covered
Week 7: Building Decision Systems With AI
Concepts Covered
Week 8: AI-Powered Recommendation Systems
Concepts Covered
Week 9: Project 2
Work on a real-world challenge by applying skills learned throughout the program, leveraging industry-relevant tools and technologies to maximize outcomes.
Week 10: Learning Break
Learning breaks are structured pauses to consolidate concepts, complete pending work, and reinforce understanding before progressing further.
Week 11: Building Context-Aware AI Workflows
Concepts Covered
Week 12: Prompt Optimization and Evaluation
Concepts Covered
Week 13: Project 3
Work on a real-world challenge by applying skills learned throughout the program, leveraging industry-relevant tools and technologies to maximize outcomes.
Week 14: Designing and Building Agentic AI Workflows
Concepts Covered
Week 15: Orchestrating Multi-Agent Systems
Concepts Covered
Week 16: Project 4
Work on a real-world challenge by applying skills learned throughout the program, leveraging industry-relevant tools and technologies to maximize outcomes.
Self-Paced Modules
Self-Paced Modules
This module is designed to build practical capability in applying Generative AI and Agentic AI using the Claude ecosystem in real-world contexts. Learners build the ability to design, execute, and evaluate AI-driven workflows for real-world applications, supported by ~5 hours of structured learning.
Build a foundational understanding of deep learning concepts and neural network architectures used in modern AI systems.
Learn how AI systems process and interpret visual information using advanced computer vision techniques.
Explore the principles of building fair, transparent, and responsible AI systems across real-world applications.
Understand the fundamentals of time-series data analysis and forecasting for temporal decision-making.
Sample Case Studies
Apply your learning through real-world case studies guided by global industry experts. Please note: All case studies and projects outlined are indicative and subject to change.
Supply Chain Disruption Response Assistant
Clinical Trial Protocol Feasibility Review
AI-Assisted Data Cleaning for Retail Sales
Customer Segmentation for a Retail Bank
Quick-Commerce Order Volume Drivers
Loan Application Risk Triage
E-Commerce Next-Best-Product Recommendations
Employee HR Policy Assistant
Banking Customer Service Copilot
Autonomous SaaS Support Triage Agent
Competitive Market Intelligence Platform
Projects and Case Studies
Engage in projects and real-world case studies using emerging tools and technologies across sectors
-
AI-Assisted
Coding
-
10+
case studies
-
Advanced AI
Modules and Concepts
RETAIL
Customer Personality Segmentation
Description
Analyze customer purchase and demographic data to identify distinct behavioral segments that enable personalized loyalty programs and targeted promotions.
Skills you will learn
- EDA
- K-Means
- Gaussian Mixture Models
- PCA
- Clustering
- Dimensionality Reduction
- Feature Engineering
- Customer Analytics
MEDIA
OTT Platform Content Recommendation Engine
Description
Build a recommendation engine using viewing behavior and content metadata to improve discovery, increase watch time, and reduce churn.
Skills you will learn
- Rank-Based Recommendations
- Content-Based Filtering
- Collaborative Filtering
- Recommender Systems
- User Behavior Analysis
- Ranking Models
- Personalization Algorithms
LEGAL
RAG-Based Legal Contract Review Assistant
Description
Build a contract review assistant that retrieves and analyzes clauses from internal contract repositories to support faster, more consistent legal review.
Skills you will learn
- Retrieval-Augmented Generation (RAG)
- Chunking
- Embeddings
- Vector Databases
- Document Analysis
- Information Retrieval
- LLM Grounding
FINANCE
Multi-Agent Financial Research Assistant
Description
Build a multi-agent system that gathers, analyzes, and synthesizes financial data from filings, internal research, and external sources into structured sector briefings.
Skills you will learn
- Multi-Agent Systems
- Adaptive RAG
- Web Search
- Sentiment Analysis
- Information Retrieval
- Orchestration
- Tool Use
- Evaluation Metrics
- Handoff Reliability
Languages and Tools covered
Build a solid foundation in popular/advanced tools and frameworks top employers seek
-
Python
-
Google Colab
-
VS Code (Visual Studio Code)
-
OpenAI
-
ChatGPT
-
LangChain
-
LangGraph
-
Claude
Earn a certificate of completion from MIT IDSS
Certificate from the MIT School of Engineering and IDSS upon successful completion of the program
-
World #1
MIT ranks #1 in World Universities – QS World University Rankings, 2025
-
U.S. #2
MIT ranks #2 among National Universities – U.S. News & World Report Rankings, 2024–2025


* Image for illustration only. Certificate subject to change.
Program Faculty
-
Stefanie Jegelka
Associate Professor, EECS and IDSS
Expert in algorithms and optimization for AI.
Pioneer advancing theoretical machine learning foundations.
Know More -
Munther Dahleh
William A. Coolidge Professor, EECS and IDSS; Founding Director, IDSS
Trailblazer in robust control and computational design.
Director propelling interdisciplinary research and innovation.
Know More -
Caroline Uhler
Professor, EECS and IDSS
Expert in computational biology, statistics, and systems.
Award-winning scholar relentlessly driving transformative data insights.
Know More -
Devavrat Shah
Andrew (1956) and Erna Viterbi Professor, EECS and IDSS
Renowned expert in large-scale network inference.
Award-winning innovator in data-driven decisions.
Know More -
John N. Tsitsiklis
Clarence J. Lebel Professor, Dept. of Electrical Engineering & Computer Science (EECS) at MIT
Leader in optimization, control, and learning.
Renowned scholar with multiple prestigious accolades.
Know More





Program Mentors
Interact with dedicated and experienced industry experts who will guide you in your learning & career journey
-
Jagan Chidella
Information Technology Specialist III (Principal Enterprise Architect) at California Department of Technology.
-
Aishwarya Krishna Allada
Senior Data Scientist
-
Anuj Saboo
Business Intelligence & Data Science Manager at BAT.
-
Reza Bagheri
Data Scientist
-
Osama Sidahmed
Data Scientist III at Fortra.
-
Venugopal Adep
AI Product Leader - General Manager at Jio Platforms Limited (JPL).
-
Chetan Jangamashetti
Product Data Scientist
-
Sriharsha Ramaraju
Senior Data Scientist at Psychiatry-UK.
-
Mohammad Raahemi
Data Scientist at Canada Border Services Agency.
-
Abhishek Kumar Mishra
Manager - Data Science & ML Ops at Collinson.
-
Saurabh Kango
Manager Data and AI programs at Meta.












Learners review our program support & mentors
Read about learners experiences with our program support, faculty, and mentors
-
The program empowered me to confidently build and apply machine learning models in real-world scenarios.
With a background in Industrial Engineering and over two years of experience in manufacturing and finance, I recognized the need to elevate my technical toolkit. I was motivated to dive deep into building Machine Learning models and bring data-driven innovation to my organization. The program proved to be a game-changer, advancing my understanding of models and enabling me to confidently select and deploy algorithms. I now apply tools like Python and Machine Learning to projects impacting organizational strategy. Balancing coursework with a full-time role was challenging, but meticulous planning made it worthwhile. The program significantly boosted my professional confidence, equipping me to approach complex data challenges strategically. I now transform raw data into valuable insights, building a strong foundation for future growth.
Read More
Maximiliano Salinas De Leon
Financial & Data Analyst , Reacciones Químicas
19th Feb 2026
-
The program strengthened my ability to apply rigorous, data-driven thinking to business decisions.
I have over a decade of experience in data, analytics, and business intelligence, working in senior leadership. I wanted a more rigorous, academically grounded understanding of Data Science and Machine Learning, especially for data-driven business decisions. The MIT Data Science and Machine Learning: Making Data-Driven Decisions program stood out due to its strong theoretical foundation and real-world applicability. It deepened my understanding of statistical thinking, classification techniques, and Machine Learning fundamentals, using Python-based projects and business case studies. I applied these concepts to improve analytical rigor in revenue optimization and customer behavior analysis. Balancing the program with a full-time executive role was challenging, but the structured curriculum and clear explanations helped me stay disciplined. The program strengthened my confidence in advanced analytics discussions. I now approach problems with a methodical, hypothesis-driven mindset, considering data quality and ethical implications. This program has elevated how I frame business problems and communicate insights.
Read More
Asiedu Ansu
Head of Data and Analytics Centre of Excellence , Vodafone Ghana
6th Feb 2026
-
Only a well-structured program can genuinely facilitate successful learning in any subject.
I recently completed a Data Science and Machine Learning program with Great Learning, and it was an amazing experience! Although there are many 'free' or 'inexpensive' programs available online today, I found that only a well-structured program like this one can genuinely facilitate successful learning in any subject. From the beginning, the program stood out due to its comprehensive design aimed at ensuring success. It wasn't just about providing access to instructional videos; the program was crafted to support learners every step of the way. One of the most invaluable aspects was the mentoring sessions. These sessions provided a platform to discuss issues and resolve any doubts, which is essential no matter how good the videos are. Additionally, the program offered robust support whenever I encountered difficulties. In my case, having a dedicated Program Manager made a great difference. The combination of detailed instructional content, regular mentoring, and exceptional support ensured that I learned and truly understood and could apply the concepts of Data Science and Machine Learning.
Read More
Salvador Ruz
Founder , tecnifinkar (an startup)
19th Apr 2024
-
El curso sobrepasó mi expectativa, altamente recomendado.
Soy el CIO de la Universidad Pedagógica Nacional. En la Universidad Pedagógica Nacional tengo el deseo de apoyar las investigaciones de las áreas de posgrado en materia de Ciencia de Datos, además con esto realizar colaboraciones interinstitucionales a nivel internacional sobre el tema. Me pareció un curso excelente, sobrepasó mi expectativa, altamente recomendado. Si bien es cierto la exigencia de repente rebasó las cargas de trabajo, al final fue muy satisfactorio el aprendizaje, los contenidos muy pertinentes, el nivel de profundidad adecuado y el material es muy bueno, sobre todo que podremos seguir accediendo a él durante un tiempo, lo cual da oportunidad de profundizar en algunos temas y recordar algunos otros. Los aprendizajes clave, fueron el retomar los conceptos aprendidos de probabilidad y estadística, aprendiendo también nuevos conceptos y su aplicación. Y sobre todo revisar el potencial de Python, que en mi caso, en programación, aunque había tenido experiencia, lo había dejado desde hace muchos años por dedicarme solo a la gestión de TI.
Read More
Victor Alvarez
subdirector , universidad pedagógica nacional
28th Sep 2023
-
La adopción de Ciencia de Datos es un requerimiento inmediato en mi institución.
"Mi interés por la Ciencia de Datos es porque en las instituciones donde colaboro la adopción de estas tecnologías es ya un requerimiento inmediato, tanto en la parte jurisdiccional como en la parte estadística. Mi experiencia la considero muy positiva, considero diseñar un proyecto para llevar lo aprendido en la institución donde trabajo y para proyectos personales. Aprendí Python y sus principales librerías, la interpretación de los resultados."
Read More
Otilio Hernandez
titular de la unidad de servicios informaticos (cio) , tribunal electoral de la ciudad de méxico
26th Sep 2023
-
El contenido bien estructurado y material de alta calidad transformaron mi capacidad en la Supply Chain.
"Mi principal motivación fue fortalecer mi capacidad de toma de decisiones basadas en datos y combinar técnicas avanzadas de análisis con mi experiencia en Supply Chain. Buscaba herramientas y habilidades que me permitieran generar soluciones innovadoras y eficientes en el mundo de la gestión de la cadena de suministro. El contenido estaba bien estructurado, y el material de aprendizaje fue de alta calidad. Los casos de estudio presentados por la facultad del MIT eran relevantes y actuales. Los proyectos me permitieron aplicar el conocimiento teórico en escenarios prácticos. Además, el apoyo de la oficina del programa fue esencial para mi proceso de aprendizaje. Lo más interesante fue cómo la ciencia de datos y el aprendizaje automático pueden transformar y optimizar los sistemas de cadena de suministro, llevándolos a un nuevo nivel de eficiencia y precisión. Las habilidades clave que adquirí incluyen técnicas avanzadas de análisis de datos, modelado predictivo y toma de decisiones basadas en datos. Aprendí cómo aplicar estos métodos en escenarios reales, lo que ha ampliado significativamente mi capacidad de aportar valor en roles relacionados con la cadena de suministro. Recomendaría que se sumerjan completamente en el programa, aprovechando todos los recursos y oportunidades de aprendizaje que ofrece."
Read More
Eugenio Araya
subdirector de gestión y desarrollo , pontificia universidad católica de chile
25th Sep 2023
-
Challenging hands-on projects were worthwhile and transformed my expectations for data teams.
I am 55 years old and decided to tackle this detailed program in Machine Learning and Data Analysis, given the promise of hands-on experience. The program structure and content are highly relevant and have certainly changed what I expect from my data teams going forward. Remote learning through the Olympus platform worked very well. The content was excellent, with all lectures transcribed for future reference. The hands-on projects were challenging but worthwhile. The mentor learning sessions on weekends were detailed and an essential part of the program. I found the program support to be excellent, and it was reassuring to have someone just a WhatsApp message away for help. I have already recommended this program to others.
Read More
Kobus Burger
head of data&analytics for client solutions , standard bank group
17th Jul 2023
-
Highly recommended for anyone seeking a career in Data Science.
The program is well-structured and brilliantly taught. The live sessions by industry experts were incredible. The projects and case studies provided practical experience. The Program Manager's support started before the program and continues even after completion. A highly recommended program for anyone seeking a career in Data Science.
Read More
Aseem Mehrotra
instrumentation maintenance & reliability engineer , adnoc group
15th Jul 2023
-
The weekend live sessions were really helpful for clearing doubts with an expert.
The teaching methodology was really nice. The program provided me with a lot of practical quizzes and wonderful notebooks. The weekend live sessions were really helpful as I could directly talk to an expert and ask all my doubts and queries.
Read More
Fabrizio De Masi
fieldbus & iot engineer , gefran
19th Jun 2023
-
A well-structured, comprehensive, and challenging learning journey over 12 weeks.
The MIT Data Science and Machine Learning program with Great Learning was an enriching experience over 12 weeks. The program was well-structured, comprehensive, and challenging, making it an impactful learning journey. The commitment to excellence from the MIT faculty, coupled with the support of the learning team and mentors, created a highly supportive environment. The Program Manager was pivotal in ensuring smooth communication and guidance, contributing significantly to the program's success. I highly recommend this program to those seeking a thorough understanding of Data Science and Machine Learning.\
Read More
Anca Fatu
power system specialist , independent electricity system operator
19th Jun 2023
Learners review
Learners review
-
Watch story
"The people behind the program were amazing, I believe this was best part of the program"
The favourite part was the hackathon competition, where we had to combine everything that we had learnt and build the model
Arlindo Almada
,
-
Watch story
" Mentors help you understand difficult concepts and complete the course"
Studying this course has placed me in a better position to offer good counseling in my field. I am going to stretch myself to work as a Data Scientist in the business industry. I see this opportunity as a dream come true.
Berthy Buah
STMIE Coordinator , Ghana Education Service
-
Watch story
"Building Confidence in Big Data Management Without Prior Experience"
Joined the program to learn handling big data and exceeded expectations. Gained valuable skills in Python and Machine Learning. Highly recommend it for anyone starting their data analytics journey!
Chun Wing Ip
Student , University Of Sydney
Course Fees
The course fee is USD 2,500
Invest in your career
-
Learn from world-renowned MIT IDSS faculty and top industry leaders
-
Build an impressive portfolio with 3 projects and 50+ case studies
-
Get personalized assistance with a dedicated Program Manager from Great Learning
-
Earn a certificate of completion from MIT IDSS and 8.0 Continuing Education Units (CEUs)

Application Process
The program follows a simple 3-step application process. The step-by-step process is outlined below.
-
1. Fill application form
Apply by filling a simple online application form.
-
2. Application Screening
A panel from Great Learning will review your application to determine your fit for the program your fit for the program.
-
3. Join program
After a final review, you will receive an offer for a seat in the upcoming cohort of the program.



Batch start date
-
Online · 13th Jun 2026
Admission closing soon
Frequently Asked Questions
What does the MIT IDSS AI and Data Science course offer?
The 12-week online AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact is offered by the MIT Institute for Data, Systems, and Society (IDSS). The program offers:
- A certificate of completion from MIT IDSS and the MIT Schwarzman College of Computing
- Mentorship from experienced industry experts
- Recorded lectures by MIT faculty.
- Exposure to cutting-edge topics, including Generative AI, Responsible AI, Deep Learning, and more
- A comprehensive curriculum covering both foundational and advanced concepts.
- Flexibility and practical value that working professionals need.
What makes the MIT IDSS AI and Data Science program unique?
MIT IDSS AI and Data Science program is unique because of its academic rigor and industry relevance. Here are the reasons why this program stands out:
Learn from MIT Faculty
Access recorded lectures from 13 world-renowned MIT faculty and instructors who bring academic depth and industry relevance to every session.
Get Mentored by Industry Experts
Receive direct mentorship from professionals working in the world’s leading organizations as they share real-world applications of Data Science and AI concepts.
Real-World Expertise
Work on 3 hands-on projects and explore over 50 real-world case studies to strengthen your skills and demonstrate your AI and Data Science capabilities.
Explore the Future of AI
Attend 3 exclusive masterclasses on Generative AI to understand the latest developments and how they are shaping industries worldwide.
Master Key AI Concepts
Deepen your understanding of core AI concepts, including Generative AI, Recommendation Systems, Responsible AI, and Deep Learning.
Earn a Recognized Credential
Receive a Certificate of Completion from MIT IDSS and earn 8.0 Continuing Education Units (CEUs), validating your ability to apply AI and Data Science for impact.
Career Support
Benefit from dedicated career support, including tailored CV and LinkedIn profile reviews designed to support your transition or advancement in the field.
What are the learning outcomes of the MIT IDSS AI and Data Science course?
With this AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact, learners will gain:
- Understand the intricacies of Data Science and Artificial Intelligence techniques and their applications to real-world problems
- Implement various Machine Learning techniques to solve complex problems and make data-driven business decisions
- Explore two major realms of Artificial Intelligence: Machine Learning and Deep Learning, and understand how they apply to domains such as Computer Vision and Recommendation Systems
- Choose how to represent your data effectively when making predictions
- Explore the practical applications of Recommendation Systems across various industries and business contexts
- Build an industry-ready portfolio of projects and demonstrate your ability to extract valuable business insights from data
What is the required weekly time commitment for this AI and Data Science program?
The program is designed for professionals and typically requires 8–12 hours per week. This includes:
- Around 2 hours of recorded faculty lectures
- 2 hours of weekend hands-on mentorship sessions (held over 7 weekends)
- Additional time for self-study, assignments, and project work
The format ensures you can balance learning with your professional responsibilities.
How is my performance evaluated in the MIT IDSS AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact?
Your progress is measured through continuous assessments designed to reinforce learning and real-world application.
These include:
- Quizzes and graded assignments
- Case studies and hands-on exercises
- Capstone project to test applied understanding
This approach ensures you stay engaged. It tracks your learning outcomes throughout the 12-week program.
Do I need to bring my own laptop for this AI and Data Science online course?
Yes, having your own laptop is required for attending the program. The necessary technology requirements shall be shared during registration.
Who is the faculty of this AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact?
This program is taught by renowned MIT faculty with over 120 years of collective experience in academic leadership, research, and industry collaboration. They have published award-winning papers and made significant contributions to AI, Data Science, and Machine Learning. In addition to the faculty, the course also features global industry mentors who will guide you through live, personalized mentoring sessions as you work on hands-on projects.
What languages and tools will I learn in this AI and Data science course?
You will learn the most in-demand languages and tools during the AI and Data Science Program, including:
- Python
- Pandas
- NumPy
- Keras
- TensorFlow
- Matplotlib
- Scikit-Learn and others.
How is the curriculum of this AI and Data Science course unique?
The curriculum, expertly crafted by MIT faculty, is designed to equip learners with industry-relevant tools and techniques, enabling them to apply these skills in AI, Data Science, Machine Learning, and Generative AI to real-world problems. Here's what makes it unique:
- Crafted by MIT faculty for academic depth and industry relevance.
- Covers complete AI and Data Science concepts from foundational techniques to advanced machine learning models, deep learning, NLP, computer vision, and recommendation systems.
- Focus on Generative AI and Responsible AI to ensure you're equipped for the next wave of innovation.
- Provides Hands-On Experience through 3 industry-relevant projects and over 50 real-world case studies.
- Built for Working Professionals with a flexible format, recorded lectures, and live weekend mentorship.
What role does Great Learning play in delivering this program?
Yes, this program is delivered by MIT IDSS in collaboration with Great Learning. As an education collaborator, Great Learning supports learners throughout their journey by providing access to experienced industry mentors, program support teams, and live personalized mentorship sessions.
Great Learning also facilitates learner engagement, offers career guidance, and ensures a seamless learning experience aligned with the high academic standards set by MIT IDSS.
Is this Data Science course online?
Yes. The program is delivered 100% online to meet the needs of working professionals. You can build practical skills in AI, Data Science, and Machine Learning from anywhere, all within a focused and efficient 12-week format.
Will I receive a certificate after completing the MIT IDSS AI and Data Science course for working professionals?
Upon successful completion of the AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact, you will receive a Certificate of Completion from MIT IDSS and earn 8.0 Continuing Education Units (CEUs), validating your ability to apply AI and Data Science for impact.
How is MIT ranked globally?
MIT is ranked #1 university in the world (QS World University Rankings) in AI and Data Science and the #2 national university in the U.S. (U.S. News & World Report). MIT Professional Education's programs reflect this leadership by integrating cutting-edge concepts and practical skill-building in these domains, enabling professionals to make data-driven decisions and lead digital transformation.
Will I receive a transcript or grade sheet after completing this AI and Data Science course?
As this is not a degree program or a full-time academic offering, the university does not issue transcripts or grade sheets for this course.
However, you will receive performance scores for each assessment and module. Upon successfully completing all program requirements, you will earn a Certificate of Completion from the MIT Schwarzman College of Computing and IDSS.
What is the duration of this MIT IDSS AI and Data Science Program?
The duration of the MIT IDSS AI and Data Science Program is 12 weeks.
It includes recorded lectures from award-winning MIT faculty, more than 50 real-world case studies, and 3 industry-relevant hands-on projects.
Who is this program ideal for?
The AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact is ideal for:
- Early-career professionals or senior managers (IT Managers, Business Intelligence Analysts, Data Science Managers, Management Consultants, and Business Managers) who want to apply AI, Data Science, and Machine Learning techniques in their firms.
- Data Scientists, Data Analysts, or Business Analysts who wish to turn vast volumes of data into valuable insights
- Entrepreneurs interested in innovation with the assistance of AI, Data Science, and Machine Learning techniques
- Those with academic or professional training in Applied Statistics or Mathematics will find the program easier to learn. However, participants without such a background can also complete the program, provided they are ready to put in extra effort. Great Learning will offer the required assistance.
What is the deadline to enroll in this AI and Data Science course from MIT IDSS?
The application process is conducted on a rolling basis and will close once the required number of candidates are enrolled. Apply early to secure your seat.
To ensure your chances of securing a seat, we encourage you to apply as early as possible.
What coding skills are helpful for an AI and Data Professional?
A successful AI and Data Professional needs a firm grasp of coding skills. Here are the key skills that help a professional learn Data Science:
- Python: Python is the most widely used language in the field of data analysis and Machine Learning.
- Foundational Knowledge of Other Languages: Familiarity with R, SQL, and SAS is essential, especially for statistical analysis and database management. Some roles may also require exposure to Java, Scala, or Julia.
- Understanding of the Data Workflow: Beyond programming, you’ll need to know how to work with tools for data acquisition, cleaning, transformation, warehousing, and visualization.
What is the registration process to pursue this online MIT IDSS AI and Data Science Program?
The registration process for this AI and Data Science program is as follows:
- Step-1: Application Form Register by completing the online application form.
- Step-2: Fill Application Screening A panel from Great Learning will assess your application based on academics, work experience, and motivation.
- Step-3: Join Program After a final review, you will receive an offer for a seat in the upcoming cohort of the program.
What is the program fee?
The total program fee is USD 2500.
Do I need to pay any additional charges for buying books, virtual learning material, or license fees?
No. All required learning materials are provided online through the Learning Management System (LMS). Because these fields continue to evolve, you will also receive a list of recommended books and resources for optional, in-depth exploration.
What are the available payment options for registering for the online Data Science course from MIT IDSS?
Applicants can pay the program fee through Bank Transfer and Credit/Debit Cards. They can also pay in easy installments using PayPal credit options and get interest-free payments for up to 6 months (Note that these services are subject to credit approval by PayPal). [For further details, please get in touch with us at dsml.mit@mygreatlearning.com]
Is there any refund policy?
Please note that submitting the registration fee constitutes enrollment in the program, and the cancellation penalties outlined below will be applied. If you are unable to attend your program, please review our dropout and refund policies below:
- Dropout requests received within 7 days of enrollment and more than 42 days prior to the commencement of the program will incur no fee. Any payment received will be refunded in full.
- Dropout requests received more than 42 days prior to the program but more than 7 days after the acceptance are subject to a cancellation fee of USD 250.
- Dropout requests received 22-41 days prior to the commencement of the program are subject to a cancellation fee equal to 50% of the program fee.
- Any dropout requests received fewer than 22 days prior to the commencement of the program are subject to a cancellation fee equal to 100% of the program fee.
- No refund will be made to those who do not engage in the program or leave before completing a program for which they have registered.
Are there any corporate sponsorship programs?
We accept corporate sponsorships and can assist you with the process. [For more information, please write to us at [dsml.mit@mygreatlearning.com]
Is there a demand for AI, Data Science, and Machine Learning specialists?
Yes, there is an increasing demand for AI, Data Science, and Machine Learning professionals across a wide range of industries, including Technology, Healthcare, Cybersecurity, Finance, Oil & Gas, Transportation, Education, Talent Acquisition, Inventory Management, E-commerce, and more.
As organizations increasingly adopt AI and data-driven decision-making, professionals skilled in AI, Data Science, Machine Learning, and Generative AI are in high demand. These skills offer strong opportunities for career growth, leadership roles, and long-term industry relevance.
Employment of data scientists is projected to grow 34 percent from 2024 to 2034, significantly faster than the average growth rate for all occupations.
If you’re looking to build a future-proof career, now is the time to upskill in AI, Data Science, and Machine Learning.
How to become a Data Scientist?
To become a Data Scientist, you need to have a blend of technical expertise, analytical thinking, and real-world problem-solving skills. If you have a strong academic background, that will help you learn the concepts related to the field.
Here’s how you can start:
- Build a strong foundation in mathematics, statistics, and programming.
- Gain hands-on experience with tools used in the industry.
- Develop applied knowledge through projects that simulate real-world data challenges.
- Strengthen your understanding of Generative AI, AI, and Machine Learning techniques.
Is the future of AI and data science promising?
- Growing demand in Business: Companies are leveraging AI and Data Science to reduce costs, improve marketing effectiveness, launch better products, and tap into new markets.
- Data-driven strategy making: Gartner has forecasted that many corporate strategies will highlight data and analytics as essential business competencies.
- Expanding applications: From healthcare and finance to retail and tech, Data Science is shaping decision-making and driving innovation across industries.
- Career longevity: With data at the core of digital transformation, professionals with expertise in AI, ML, and Data Science are well-positioned for long-term career growth.
As industries increasingly rely on data to drive innovation and growth, the need for skilled Data Science professionals will only continue to rise.
Gaining expertise in Artificial Intelligence, Machine Learning, and Data Science is a smart investment for you to future-proof your career.
What is Machine Learning?
Machine Learning refers to a group of techniques used by data scientists that allow computers to learn from data. From leisure to work, our lives are made easier with Machine Learning. The responsibilities of a Machine Learning specialist encompass a spectrum that extends from creating Machine Learning models to retraining systems.
What is Data Science?
Data Science is a field of study that uses a scientific approach to extract meaningful insights from data. Meaningful insights are derived from data sets, generating knowledge that advises recommendations for business growth.
Why choose Data Science and Machine Learning?
Organizations across industries increasingly rely on advanced Data Science and Machine Learning to drive strategic decision-making and improve business outcomes. Here’s how Data Science and Machine Learning create impact.
Inform stronger business strategies.
Leading companies use data-driven insights and machine learning models to design effective business plans, optimize operations, and accelerate growth.
Deliver solutions that meet customer needs.
Organizations with clear data strategies can anticipate market trends, innovate faster, and build products that offer greater value to end users.
Reduce operational costs.
For small and medium-sized enterprises, AI, Data Science, and Machine Learning enable more efficient processes and cost-effective solutions, helping them stay competitive despite limited resources.
This combination of strategic insight, customer-centric innovation, and operational efficiency is why Data Science and Machine Learning have become essential capabilities for modern businesses.
Delivered in Collaboration with:

MIT Institute for Data, Systems, and Society (IDSS) is collaborating with online education provider Great Learning to offer AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact. This program leverages MIT's leadership in innovation, science, engineering, and technical disciplines developed over years of research, teaching, and practice. Great Learning collaborates with institutions to manage enrollments (including all payment services and invoicing), technology, and participant support. Accessibility
 Application Closes
21st May 2026
Application Closes
21st May 2026

Frequently asked questions
What does the MIT IDSS AI and Data Science course offer?
The 12-week online AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact is offered by the MIT Institute for Data, Systems, and Society (IDSS). The program offers:
- A certificate of completion from MIT IDSS and the MIT Schwarzman College of Computing
- Mentorship from experienced industry experts
- Recorded lectures by MIT faculty.
- Exposure to cutting-edge topics, including Generative AI, Responsible AI, Deep Learning, and more
- A comprehensive curriculum covering both foundational and advanced concepts.
- Flexibility and practical value that working professionals need.
What makes the MIT IDSS AI and Data Science program unique?
MIT IDSS AI and Data Science program is unique because of its academic rigor and industry relevance. Here are the reasons why this program stands out:
Learn from MIT Faculty
Access recorded lectures from 13 world-renowned MIT faculty and instructors who bring academic depth and industry relevance to every session.
Get Mentored by Industry Experts
Receive direct mentorship from professionals working in the world’s leading organizations as they share real-world applications of Data Science and AI concepts.
Real-World Expertise
Work on 3 hands-on projects and explore over 50 real-world case studies to strengthen your skills and demonstrate your AI and Data Science capabilities.
Explore the Future of AI
Attend 3 exclusive masterclasses on Generative AI to understand the latest developments and how they are shaping industries worldwide.
Master Key AI Concepts
Deepen your understanding of core AI concepts, including Generative AI, Recommendation Systems, Responsible AI, and Deep Learning.
Earn a Recognized Credential
Receive a Certificate of Completion from MIT IDSS and earn 8.0 Continuing Education Units (CEUs), validating your ability to apply AI and Data Science for impact.
Career Support
Benefit from dedicated career support, including tailored CV and LinkedIn profile reviews designed to support your transition or advancement in the field.
What are the learning outcomes of the MIT IDSS AI and Data Science course?
With this AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact, learners will gain:
- Understand the intricacies of Data Science and Artificial Intelligence techniques and their applications to real-world problems
- Implement various Machine Learning techniques to solve complex problems and make data-driven business decisions
- Explore two major realms of Artificial Intelligence: Machine Learning and Deep Learning, and understand how they apply to domains such as Computer Vision and Recommendation Systems
- Choose how to represent your data effectively when making predictions
- Explore the practical applications of Recommendation Systems across various industries and business contexts
- Build an industry-ready portfolio of projects and demonstrate your ability to extract valuable business insights from data
What is the required weekly time commitment for this AI and Data Science program?
The program is designed for professionals and typically requires 8–12 hours per week. This includes:
- Around 2 hours of recorded faculty lectures
- 2 hours of weekend hands-on mentorship sessions (held over 7 weekends)
- Additional time for self-study, assignments, and project work
The format ensures you can balance learning with your professional responsibilities.
How is my performance evaluated in the MIT IDSS AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact?
Your progress is measured through continuous assessments designed to reinforce learning and real-world application.
These include:
- Quizzes and graded assignments
- Case studies and hands-on exercises
- Capstone project to test applied understanding
This approach ensures you stay engaged. It tracks your learning outcomes throughout the 12-week program.
Do I need to bring my own laptop for this AI and Data Science online course?
Yes, having your own laptop is required for attending the program. The necessary technology requirements shall be shared during registration.
Who is the faculty of this AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact?
This program is taught by renowned MIT faculty with over 120 years of collective experience in academic leadership, research, and industry collaboration. They have published award-winning papers and made significant contributions to AI, Data Science, and Machine Learning. In addition to the faculty, the course also features global industry mentors who will guide you through live, personalized mentoring sessions as you work on hands-on projects.
What languages and tools will I learn in this AI and Data science course?
You will learn the most in-demand languages and tools during the AI and Data Science Program, including:
- Python
- Pandas
- NumPy
- Keras
- TensorFlow
- Matplotlib
- Scikit-Learn and others.
How is the curriculum of this AI and Data Science course unique?
The curriculum, expertly crafted by MIT faculty, is designed to equip learners with industry-relevant tools and techniques, enabling them to apply these skills in AI, Data Science, Machine Learning, and Generative AI to real-world problems. Here's what makes it unique:
- Crafted by MIT faculty for academic depth and industry relevance.
- Covers complete AI and Data Science concepts from foundational techniques to advanced machine learning models, deep learning, NLP, computer vision, and recommendation systems.
- Focus on Generative AI and Responsible AI to ensure you're equipped for the next wave of innovation.
- Provides Hands-On Experience through 3 industry-relevant projects and over 50 real-world case studies.
- Built for Working Professionals with a flexible format, recorded lectures, and live weekend mentorship.
What role does Great Learning play in delivering this program?
Yes, this program is delivered by MIT IDSS in collaboration with Great Learning. As an education collaborator, Great Learning supports learners throughout their journey by providing access to experienced industry mentors, program support teams, and live personalized mentorship sessions.
Great Learning also facilitates learner engagement, offers career guidance, and ensures a seamless learning experience aligned with the high academic standards set by MIT IDSS.
Is this Data Science course online?
Yes. The program is delivered 100% online to meet the needs of working professionals. You can build practical skills in AI, Data Science, and Machine Learning from anywhere, all within a focused and efficient 12-week format.
Will I receive a certificate after completing the MIT IDSS AI and Data Science course for working professionals?
Upon successful completion of the AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact, you will receive a Certificate of Completion from MIT IDSS and earn 8.0 Continuing Education Units (CEUs), validating your ability to apply AI and Data Science for impact.
How is MIT ranked globally?
MIT is ranked #1 university in the world (QS World University Rankings) in AI and Data Science and the #2 national university in the U.S. (U.S. News & World Report). MIT Professional Education's programs reflect this leadership by integrating cutting-edge concepts and practical skill-building in these domains, enabling professionals to make data-driven decisions and lead digital transformation.
Will I receive a transcript or grade sheet after completing this AI and Data Science course?
As this is not a degree program or a full-time academic offering, the university does not issue transcripts or grade sheets for this course.
However, you will receive performance scores for each assessment and module. Upon successfully completing all program requirements, you will earn a Certificate of Completion from the MIT Schwarzman College of Computing and IDSS.
What is the duration of this MIT IDSS AI and Data Science Program?
The duration of the MIT IDSS AI and Data Science Program is 12 weeks.
It includes recorded lectures from award-winning MIT faculty, more than 50 real-world case studies, and 3 industry-relevant hands-on projects.
Who is this program ideal for?
The AI and Data Science: Leveraging Responsible AI, Data and Statistics for Practical Impact is ideal for:
- Early-career professionals or senior managers (IT Managers, Business Intelligence Analysts, Data Science Managers, Management Consultants, and Business Managers) who want to apply AI, Data Science, and Machine Learning techniques in their firms.
- Data Scientists, Data Analysts, or Business Analysts who wish to turn vast volumes of data into valuable insights
- Entrepreneurs interested in innovation with the assistance of AI, Data Science, and Machine Learning techniques
- Those with academic or professional training in Applied Statistics or Mathematics will find the program easier to learn. However, participants without such a background can also complete the program, provided they are ready to put in extra effort. Great Learning will offer the required assistance.
What is the deadline to enroll in this AI and Data Science course from MIT IDSS?
The application process is conducted on a rolling basis and will close once the required number of candidates are enrolled. Apply early to secure your seat.
To ensure your chances of securing a seat, we encourage you to apply as early as possible.
What coding skills are helpful for an AI and Data Professional?
A successful AI and Data Professional needs a firm grasp of coding skills. Here are the key skills that help a professional learn Data Science:
- Python: Python is the most widely used language in the field of data analysis and Machine Learning.
- Foundational Knowledge of Other Languages: Familiarity with R, SQL, and SAS is essential, especially for statistical analysis and database management. Some roles may also require exposure to Java, Scala, or Julia.
- Understanding of the Data Workflow: Beyond programming, you’ll need to know how to work with tools for data acquisition, cleaning, transformation, warehousing, and visualization.
What is the registration process to pursue this online MIT IDSS AI and Data Science Program?
The registration process for this AI and Data Science program is as follows:
- Step-1: Application Form Register by completing the online application form.
- Step-2: Fill Application Screening A panel from Great Learning will assess your application based on academics, work experience, and motivation.
- Step-3: Join Program After a final review, you will receive an offer for a seat in the upcoming cohort of the program.
What is the program fee?
The total program fee is USD 2500.
Do I need to pay any additional charges for buying books, virtual learning material, or license fees?
No. All required learning materials are provided online through the Learning Management System (LMS). Because these fields continue to evolve, you will also receive a list of recommended books and resources for optional, in-depth exploration.
What are the available payment options for registering for the online Data Science course from MIT IDSS?
Applicants can pay the program fee through Bank Transfer and Credit/Debit Cards. They can also pay in easy installments using PayPal credit options and get interest-free payments for up to 6 months (Note that these services are subject to credit approval by PayPal). [For further details, please get in touch with us at dsml.mit@mygreatlearning.com]
Is there any refund policy?
Please note that submitting the registration fee constitutes enrollment in the program, and the cancellation penalties outlined below will be applied. If you are unable to attend your program, please review our dropout and refund policies below:
- Dropout requests received within 7 days of enrollment and more than 42 days prior to the commencement of the program will incur no fee. Any payment received will be refunded in full.
- Dropout requests received more than 42 days prior to the program but more than 7 days after the acceptance are subject to a cancellation fee of USD 250.
- Dropout requests received 22-41 days prior to the commencement of the program are subject to a cancellation fee equal to 50% of the program fee.
- Any dropout requests received fewer than 22 days prior to the commencement of the program are subject to a cancellation fee equal to 100% of the program fee.
- No refund will be made to those who do not engage in the program or leave before completing a program for which they have registered.
Are there any corporate sponsorship programs?
We accept corporate sponsorships and can assist you with the process. [For more information, please write to us at [dsml.mit@mygreatlearning.com]
Is there a demand for AI, Data Science, and Machine Learning specialists?
Yes, there is an increasing demand for AI, Data Science, and Machine Learning professionals across a wide range of industries, including Technology, Healthcare, Cybersecurity, Finance, Oil & Gas, Transportation, Education, Talent Acquisition, Inventory Management, E-commerce, and more.
As organizations increasingly adopt AI and data-driven decision-making, professionals skilled in AI, Data Science, Machine Learning, and Generative AI are in high demand. These skills offer strong opportunities for career growth, leadership roles, and long-term industry relevance.
Employment of data scientists is projected to grow 34 percent from 2024 to 2034, significantly faster than the average growth rate for all occupations.
If you’re looking to build a future-proof career, now is the time to upskill in AI, Data Science, and Machine Learning.
How to become a Data Scientist?
To become a Data Scientist, you need to have a blend of technical expertise, analytical thinking, and real-world problem-solving skills. If you have a strong academic background, that will help you learn the concepts related to the field.
Here’s how you can start:
- Build a strong foundation in mathematics, statistics, and programming.
- Gain hands-on experience with tools used in the industry.
- Develop applied knowledge through projects that simulate real-world data challenges.
- Strengthen your understanding of Generative AI, AI, and Machine Learning techniques.
Is the future of AI and data science promising?
- Growing demand in Business: Companies are leveraging AI and Data Science to reduce costs, improve marketing effectiveness, launch better products, and tap into new markets.
- Data-driven strategy making: Gartner has forecasted that many corporate strategies will highlight data and analytics as essential business competencies.
- Expanding applications: From healthcare and finance to retail and tech, Data Science is shaping decision-making and driving innovation across industries.
- Career longevity: With data at the core of digital transformation, professionals with expertise in AI, ML, and Data Science are well-positioned for long-term career growth.
As industries increasingly rely on data to drive innovation and growth, the need for skilled Data Science professionals will only continue to rise.
Gaining expertise in Artificial Intelligence, Machine Learning, and Data Science is a smart investment for you to future-proof your career.
What is Machine Learning?
Machine Learning refers to a group of techniques used by data scientists that allow computers to learn from data. From leisure to work, our lives are made easier with Machine Learning. The responsibilities of a Machine Learning specialist encompass a spectrum that extends from creating Machine Learning models to retraining systems.
What is Data Science?
Data Science is a field of study that uses a scientific approach to extract meaningful insights from data. Meaningful insights are derived from data sets, generating knowledge that advises recommendations for business growth.
Why choose Data Science and Machine Learning?
Organizations across industries increasingly rely on advanced Data Science and Machine Learning to drive strategic decision-making and improve business outcomes. Here’s how Data Science and Machine Learning create impact.
Inform stronger business strategies.
Leading companies use data-driven insights and machine learning models to design effective business plans, optimize operations, and accelerate growth.
Deliver solutions that meet customer needs.
Organizations with clear data strategies can anticipate market trends, innovate faster, and build products that offer greater value to end users.
Reduce operational costs.
For small and medium-sized enterprises, AI, Data Science, and Machine Learning enable more efficient processes and cost-effective solutions, helping them stay competitive despite limited resources.
This combination of strategic insight, customer-centric innovation, and operational efficiency is why Data Science and Machine Learning have become essential capabilities for modern businesses.
Similar free courses for you
-

 Intermediate
Intermediate
 2.0 Hrs
2.0 Hrs
Applying Analytics to Business Problems
-

 Beginner
Beginner
 1.5 Hrs
1.5 Hrs
Data Analytics using Excel
-

 Intermediate
Intermediate
 2.0 Hrs
2.0 Hrs
Apriori Algorithm
-

 Beginner
Beginner
 3.0 Hrs
3.0 Hrs
Python for Machine Learning and Data Science
-

 Intermediate
Intermediate
 1.0 Hrs
1.0 Hrs
Applications of Data Science & Machine Learning
-

 Intermediate
Intermediate
 1.0 Hrs
1.0 Hrs
LDA in Entertainment Industry
-

 Intermediate
Intermediate
 0.5 Hrs
0.5 Hrs
Predict Footballer Transfer Market Value using Data Science
-

 Intermediate
Intermediate
 1.0 Hrs
1.0 Hrs
k-fold Cross Validation
-

 Intermediate
Intermediate
 2.0 Hrs
2.0 Hrs
Forecasting Hospital Blood Requirements
-

 Beginner
Beginner
 3.0 Hrs
3.0 Hrs
Marketing and Retail Analytics










Explore latest trends & topics
-
20+ Excel Formulas List with Examples
2025-05-14 13:44:03 UTC
-
Top 60 Statistics Interview Questions 2025
2025-05-14 13:41:56 UTC
-
Top 46 MATLAB Interview Questions and Answers in 2025
2025-05-14 13:39:49 UTC
-
Data Science vs Machine Learning and Artificial Intelligence: The Difference Explained
2025-05-14 13:09:23 UTC
-
Top 9 Job Roles in the World of Data Science for 2025
2025-05-14 13:07:55 UTC
-
100+ Data Science Interview Questions in 2025
2025-05-14 13:05:48 UTC
-
Top Data Scientist Skills You Must Have In 2025
2025-05-14 13:02:49 UTC
-
Jobs in Data Science and Business Analytics
2024-11-12 10:23:26 UTC
-
What is Data Science? - The Complete Guide
2024-01-24 07:28:57 UTC
-
How to Make the Career Transition From Data Analyst to Data Scientist?
2022-09-23 09:24:30 UTC










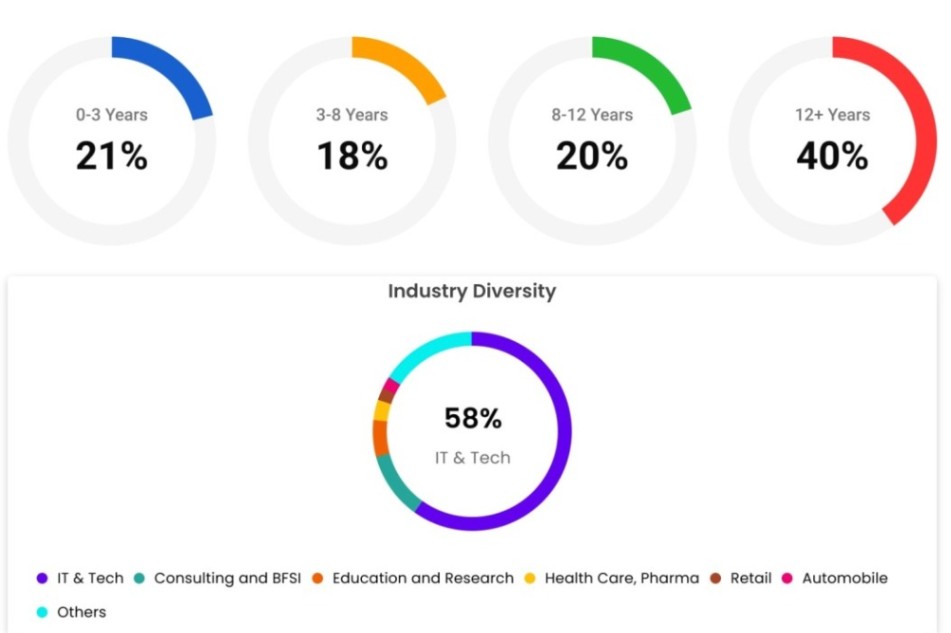
Batch Profile
The AI and Data Science class consists of working professionals from excellent organizations and backgrounds maintaining an impressive diversity across work experience, roles and industries.
Introduction to the Data Science & Machine Learning Course from MIT for Working Professionals
Numerous professional courses are available across the globe for Data Science and Machine Learning. Yet, there are several reasons for working professionals to register in this Machine Learning and Data Science professional certificate program from MIT IDSS, collaborating with Great Learning. The reasons are drafted below:
-
MIT is an abbreviation of the Massachusetts Institute of Technology, one of the world's highest-ranked institutions.
-
According to rankings by QS World University Rankings 2023, MIT has ranked #1 university globally, and according to rankings by the U.S. News and World Report 2023, MIT is ranked #2 in the world.
-
The objective of MIT IDSS is to extend education and research in state-of-the-art analytical techniques in statistics and data science, information and decision systems, and the social sciences, and to apply these techniques to address complex societal challenges in a miscellaneous set of areas like finance, urbanization, social networks, energy systems, and health.
Benefits of Pursuing MIT Data Science Certificate Course
-
Pursue the MIT Data Science certificate course and learn these cutting-edge technologies from 11 award-winning MIT faculty and instructors.
-
These award-winning MIT faculty members have designed the curriculum to build industry-valued skills.
-
You can demonstrate your Data Science and Machine Learning Leadership by creating a portfolio of 15+ case studies and 3 real-life projects.
-
You will work in a robust collaborative environment to communicate with peers in Data Science and Machine Learning.
-
Obtain live mentorship sessions and guidance from Machine Learning and Data Science professionals on applying concepts taught by the faculties.
Alumni IDSS Benefits
Have a glance at the benefits offered by IDSS alumni:
-
Participants can obtain exclusive discounts on present and future courses offered by MIT IDSS.
-
Participants can acquire a subscription to MIT IDSS alumni mailing and newsletter lists.
-
Participants can acquire membership to advance notice of upcoming events and courses.
Details about MIT Data Science Course
In this comprehensive MIT Data Science online course, the participants will grasp all the critical skills required to master Data Science and Machine Learning. Let’s go through the extensive details about the course in Data Science for working professionals:
Course Learnings:
-
Obtain an understanding of the intricacies of Data Science tools, techniques, and their significance to real-world problems.
-
Learn the procedure to implement several Machine Learning techniques for solving complex problems and making data-driven business decisions.
-
Explore two noteworthy realms of Machine Learning, Deep Learning & Neural Networks, and learn how to apply these techniques to areas like Computer Vision.
-
Choose the process of representing your data while making predictions.
-
Obtain an understanding of the theory behind recommendation systems and analyze their applications to numerous industries and business contexts.
-
Learn the method to create an industry-ready portfolio of projects for demonstrating your ability to derive business insights from data.
Course Syllabus:
-
It commences with the fundamentals of Python programming language (NumPy, Pandas, and Data Visualization) and Statistics for Data Science.
-
Afterward, participants will learn Machine Learning techniques, including Supervised and Unsupervised Learning Techniques, Clustering, Regression, Decision Trees, Random Forests, Classification and Hypothesis Testing, and several other algorithms.
-
Moving forward, participants will learn Deep Learning, Recommendation Systems, Networking & Graphical Models, Predictive Analysis, and Feature Engineering.
[Explore MIT Data Science Course Syllabus]
Course Eligibility:
-
Working professionals, such as early-career professionals or senior managers who want to pursue a career in Data Science and Machine Learning
-
Working professionals like Data Scientists, Data Analysts, or ML Engineers interested in leading Data Science and Machine Learning initiatives at their firms or businesses
-
Entrepreneurs interested in innovation with the assistance of Data Science and Machine Learning techniques
MIT Data Science for Working Professionals Course Duration
This professional course is for 12 weeks with recorded lectures from award-winning, world-renowned MIT faculty members and live mentorship sessions from industry experts.
Secure a Data Science Professional Certificate, along with Machine Learning from MIT IDSS
After successfully pursuing this course, you will secure a professional certificate in Data Science and Machine Learning: Making Data-Driven Decisions from MIT IDSS.
Hey there! Welcome back.


Forgot your password? No problem.

You are already registered. Please login instead.
Login
Forgot Password?
Enter your registered email and we'll send you a link to change your password.